昨天我們用 ROC 曲線 + AUC 了解了 Logistic Regression 的表現,今天來嘗試另一個模型 —— 隨機森林 (Random Forest),並把兩者的表現放在一起比較。
其實在還沒真正跑過模型前,我也無法保證 Random Forest 一定會比 Logistic Regression 表現更好。這正是為什麼我們需要嘗試不同模型的原因之一,因為每種機器學習方法都有它背後的「假設」與「學習方式」。不同資料集、不同特徵組合,適合的模型也會不一樣。所以我們不能只用一種模型就覺得足夠了,應該多試幾種,看看誰表現最好。
這邊讓我們快速回顧一下這兩個模型的特性:
Logistic Regression: 是線性模型,它假設特徵和結果之間呈線性關係。優點是簡單、執行速度快,而且具有良好的解釋性。
Random Forest: 是由許多決策樹組成的集成模型,可以捕捉非線性關係,對於特徵縮放、缺值、非線性都有不錯的處理能力。
訓練的過程一樣要對資料做前處理,不過因為前面已經檢查過沒有缺失值,所以這邊就只針對類別欄位做 one-hot encoding和切分資料(80% 訓練,20% 驗證)
# 訓練 Random Forest
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score, RocCurveDisplay
import matplotlib.pyplot as plt
## 對類別欄位做 one-hot encoding
categorical_cols = train.select_dtypes(include=["object"]).columns
train = pd.get_dummies(train, columns=categorical_cols)
test = pd.get_dummies(test, columns=categorical_cols)
## 確保 train/test 欄位一致
train, test = train.align(test, join="left", axis=1, fill_value=0)
# 分離特徵與標籤
X = train.drop("y", axis=1)
y = train["y"]
# 切分資料(80% 訓練,20% 驗證)
X_train, X_val, y_train, y_val = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# 訓練 Random Forest
rf_model = RandomForestClassifier(random_state=42)
rf_model.fit(X_train, y_train)
# 預測機率
rf_pred_prob = rf_model.predict_proba(X_val)[:, 1]
# 計算 AUC
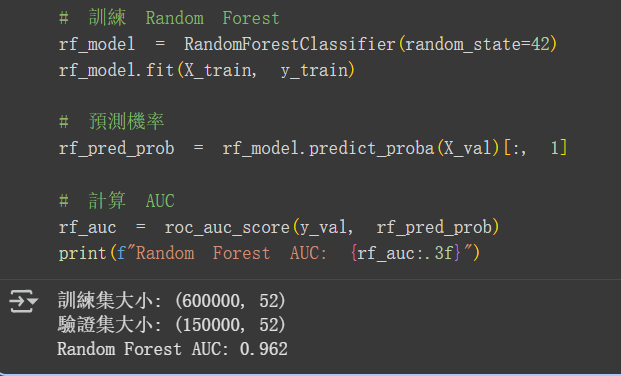
rf_auc = roc_auc_score(y_val, rf_pred_prob)
print(f"Random Forest AUC: {rf_auc:.3f}")
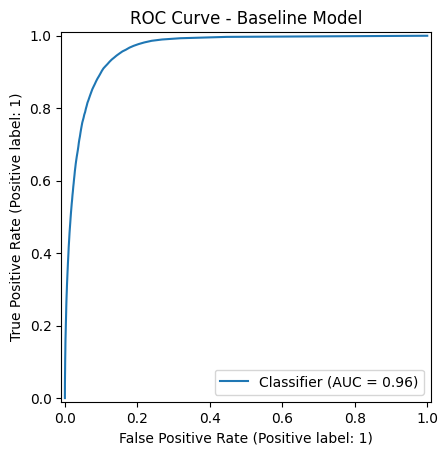
接下來畫出 Random Forest 的 ROC 曲線
# 畫 Random Forest 的 ROC 曲線
RocCurveDisplay.from_predictions(y_val, rf_pred_prob)
plt.title("ROC Curve - Baseline Model")
plt.show()
auc = roc_auc_score(y_val, rf_pred_prob)
print(f"AUC: {auc:.3f}")
我把昨天的 Logistic regression 跟今天的 Random Forest 的 ROC 曲線放在一起比較,可以看到其實差距非常小,不仔細觀察很難看出區別。但還是可以發現Random Forest 曲線比 Logistic Regression 更靠近左上角,代表它更能區分正負樣本
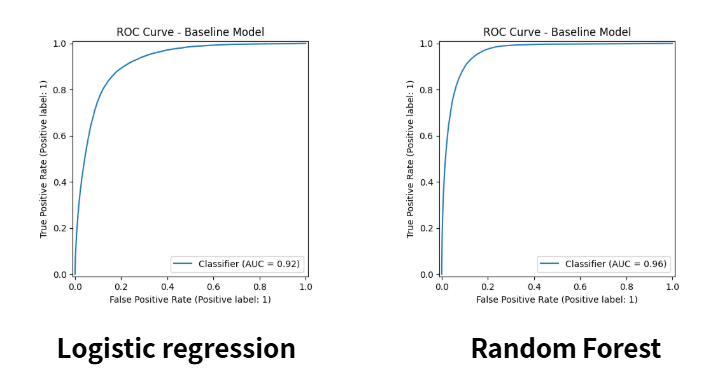
我們最終得到了這樣的結果:
| 模型 | AUC |
|---|---|
| Logistic Regression | 0.92 |
| Random Forest | 0.96 |
可以看到 Random Forest 提升了 AUC,顯示它在這個Binary Classification with a Bank Dataset 上學到更多非線性的關係。未來大家要測試其他模型,如 XGBoost、LightGBM,看看能否再創新高分數,也都可以自己試試看!
今天我們學到了:
明天我們會嘗試:


 iThome鐵人賽
iThome鐵人賽