昨天把 Indexing pipeline 跑過一遍:從資料載入、Chunking、Embeddings,到向量資料庫。
要讓 RAG 找到「對的內容」,關鍵在第三步與第四步:把文字變成向量,並在向量空間裡找到最相近的片段。
講到「向量」,大家應該不陌生——在數學課或日常圖表裡,我們常看到一維的數線、二維的平面,甚至三維的立體座標。
那更高維度呢?我們的眼睛看不見四維、五維,更不用說 768 維、1536 維這樣的空間。
在這些看不見的空間裡,AI 依靠的就是數學計算。
但看到這裡,你可能會好奇:為什麼我一直強調「維度」?
當我們用 Embeddings 把文字轉換成向量後,每個詞或句子就能被映射到一個座標點。這些座標不是隨便放的,而是根據語意來分布:意思相近的向量會更靠近,意思差很多的向量就會被拉遠。
下面是我畫的簡易示意圖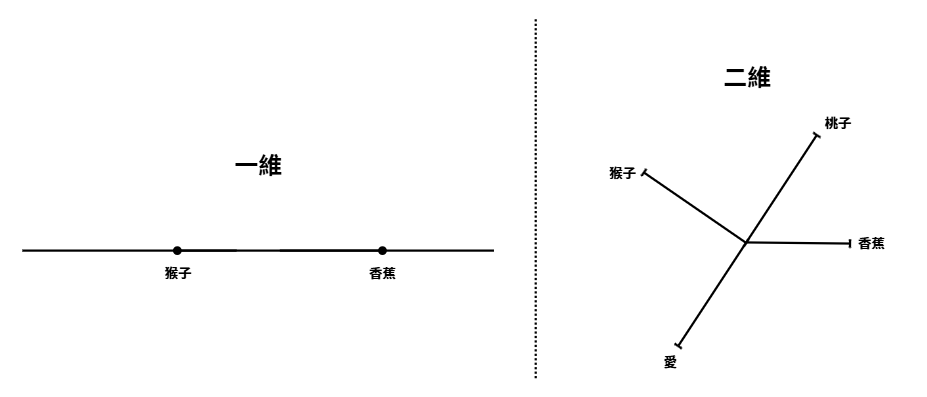
不過從圖片中就可以發現,如果單單只有一維,很多文字都會被「硬塞」在同一條線上,分不出彼此的語意差異。
舉例來說,如果我把「蘋果(水果)」和「蘋果(Apple 公司)」都放在一維數線上,它們可能剛好落在很接近的位置,但實際上語意完全不同。
這就是為什麼我們需要更高維度的空間。
在二維平面上,我們可以把「水果蘋果」放在「香蕉」附近,並把「Apple 公司」拉到另一個方向。
到了三維甚至更高維度,就能更精細地表達語意之間的差異。對電腦來說,維度越多,越能準確表示「詞與詞的語意關係」,不過當然維度不是越多越好,因為維度越高,計算與儲存的成本也會跟著增加。
所以,Embedding 幫我們把文字放進一個高維度的座標空間裡,讓電腦能用「數字」理解語意。
但僅僅有座標還不夠,我們還需要一個方法去判斷:哪些點是彼此接近的?哪些又是距離很遠的?
今天就先分享到這邊,明天會繼續分享相似度是怎麼計算的~

