昨天我們已經熟悉了深度學習的框架(TensorFlow 與 PyTorch),
今天要正式踏入 「實戰」! (激動的吶喊)
我們會用最經典的 MNIST 手寫數字資料集,
打造一個可以辨識 0–9 手寫數字的小模型。
這是幾乎所有深度學習初學者的第一個專案,
就像「Hello World」一樣,是 AI 世界的入門儀式。
當你第一次學習深度學習時,選擇一個合適的資料集非常重要。
如果資料太大,你會因為等待訓練太久而失去耐心;
而如果資料太複雜,你會在一開始就陷入太多技術細節,反而難以掌握核心概念。
而 MNIST,正好是一個 「經典」的入門選擇。
MNIST 是由 70,000 張手寫數字圖片所組成的資料集,
每張圖片都是 28×28 的灰階影像。
這意味著它的數據量不大,圖片的內容也相對單純,
不像真實世界中的照片有複雜的顏色、光線和背景。
換個說法,MNIST 就像一個很乾淨的實驗環境,你不必擔心其他問題,
而可以去專心體會 「模型如何學習特徵、如何做分類」 這件事。
除此之外,MNIST 之所以那麼經典,還因為它幾乎是所有深度學習教材的共同語言。
不論看的是書籍、線上課程,還是研究論文,
MNIST 幾乎一定會出現。
這就像程式設計學習中的「Hello World」這句看到膩的話,但它就是入門的第一步,
任何一個工程師都知道它的存在。
對新手來說,這樣的資料集能讓你快速上手,並且方便和他人交流學習成果。
而在實務進行上,MNIST 也扮演了「第一步測試」的角色。
有許多新演算法、新模型一開始都會用 MNIST 來驗證可行性,
因為它 「規模小」 、且 「容易實驗」 。
如果有一個想法連 MNIST 都無法表現良好,那大概可以回家洗洗睡了。
那大概也不需要拿去挑戰更複雜的影像辨識任務。
所以,今天我們選擇 MNIST,不只是因為它簡單,
更因為它能幫助我們在
短時間內完成 「資料讀取 → 建立模型 → 訓練 → 測試」 的完整流程。
這個過程才是學習深度學習的核心,
而 MNIST 正好提供了一個理想的入門環境。
參考資料:
https://zh.wikipedia.org/zh-tw/MNIST%E6%95%B0%E6%8D%AE%E5%BA%93
我們這次一樣使用之前使用的 google colab 做實作,
此次實作的目標是要讓模型可以正確的辨識數字,並降低錯誤率。
詳細一點來說,
我們會電腦一張 28x28 的灰階圖片,每個像素點都有 0–255 的亮度值。
這張圖可能是一個人手寫的「5」。
而透過神經網路,電腦會逐層把這些像素轉換成內部的 「特徵表徵」。
簡單來說,就是它嘗試理解「這裡有一條彎曲的線」、「這裡有個圈圈」之類的特徵。
最後,模型會輸出 10 個數字的機率(0–9),並判斷出機率最高者作為最後答案。
以下是操作步驟:
為了降低新手的學習門檻,Keras 在它的 keras.datasets 模組裡,
直接內建了 MNIST 資料集。
也就是說,不需要自己去下載和整理資料,
我們只需要輸入以下程式碼:
from tensorflow import keras
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
就可以導入MNIST的資料集,裡面有:
- x_train:60,000 筆,每筆 28x28
- y_train:對應標籤(0–9)
- x_test:10,000 張測試影像
原始影像的數值範圍是 0–255(像素亮度)。
而神經網路在處理數據時,如果範圍太大或不一致,會讓學習變慢。
我們需要把它縮放到 0–1,讓模型學習得更快。
要將數值縮小到 0–1 之間,程式碼如下:
# 把像素值轉換為浮點數,並縮放到 0–1
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
接著,因為 Keras 的 Dense 層(全連接層)要吃一維的向量資料,
所以我們需要把 28x28 的影像 「攤平成 784 維的向量」 :
# 攤平成一維向量
x_train = x_train.reshape((x_train.shape[0], 28*28))
x_test = x_test.reshape((x_test.shape[0], 28*28))
最後,標籤需要轉換成 「one-hot 編碼」格式,
讓模型能處理分類問題。
舉例來說,數字 3 的標籤就會轉換成 [0,0,0,1,0,0,0,0,0,0],
我們這邊使用keras內建的工具 「to_categorical」,
它的功能就是把「一個整數標籤」轉換成 one-hot 編碼。
程式碼如下:
from tensorflow.keras.utils import to_categorical
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
(One-hot在數位電路和機器學習中被用來表示一種特殊的位元組或向量,
該位元組或向量裏僅容許其中一位爲1,其他位都必須爲0)
參考資料:https://zh.wikipedia.org/zh-tw/%E7%8B%AC%E7%83%AD
在資料準備好後,下一步就是「建立模型」。
這時候我們就像在搭建一座神經網路的積木。
最簡單的做法是用一個全連接層(Dense layer),
把輸入的 784 (28x28)個像素值映射到隱藏層,
再進一步輸出成 10 個分類結果(數字0-9)。
輸出層通常會搭配 softmax 函數,讓模型能夠輸出 「機率分布」
現在我們來搭建一個最簡單的神經網路,描述如下:
from tensorflow.keras import models, layers
model = models.Sequential()
model.add(layers.Dense(128, activation="relu", input_shape=(784,)))
model.add(layers.Dense(10, activation="softmax"))
接著就是「編譯模型」,這一步很像是告訴模型它要怎麼學習。
我們要指定 損失函數(loss function)、
優化器(optimizer)以及 評估指標 。
對於分類問題,我們會選擇 交叉熵損失(categorical crossentropy),
再搭配像是 Adam 這樣的優化器,幫助模型一步一步調整權重。
程式碼如下:
model.compile(optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"])
參數解釋:
optimizer="adam":
Adam 是一種自動調整學習率的最佳化方法,通常收斂快且表現穩定。
loss="categorical_crossentropy":
分類任務常用的損失函數,會量化模型預測機率與真實標籤差多少。
metrics=["accuracy"]:
訓練/驗證時會顯示正確率(accuracy)作為衡量指標。
在完成這些設定後,我們就可以開始「訓練模型」了。
這時候,電腦會反覆觀看訓練資料,透過誤差的回饋逐漸調整自己。
每一個 「epoch」 代表模型完整看過一次所有的訓練圖片,
而每一個 「batch」 則是模型一次只處理一小組影像。
這裡的 validation_split=0.2 則表示:
把 20% 的訓練資料(x_train, y_train)分出來當驗證集
其餘 80% 繼續拿來訓練。
而隨著訓練的進行,我們會看到模型在訓練集與驗證集上的正確率逐漸提升。
當訓練組數越高,準確率大多時間都會變高,
但與之訓練時間也會變長。
以下是程式碼:
model.fit(x_train, y_train, epochs=5, batch_size=128, validation_split=0.2)
最後,就是 「測試與驗證」 。
我們把模型丟到測試集上,看看它能否正確辨識那些「它從來沒見過」的手寫數字。
如果正確率可以達到 九成 以上,
代表這個簡單的模型已經成功學會基本的數字辨識。
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"測試集正確率:{test_acc:.4f}")
而最後就是運作畫面結果,圖片如下: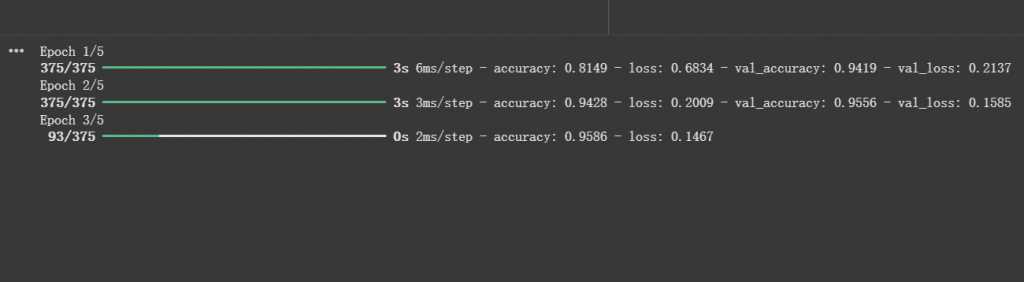
-我們設定了訓練次數為5次,所以總共會在下方執行5次完整的Epoch
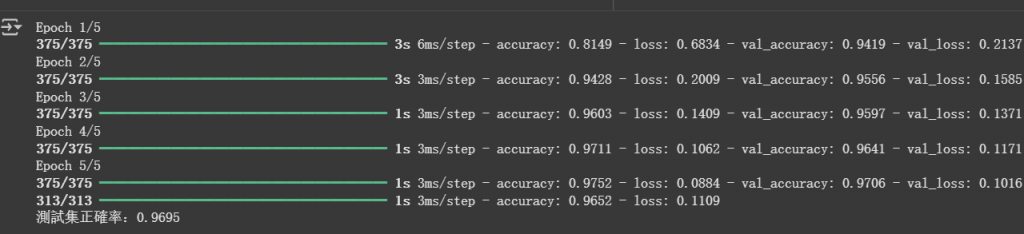
-這就是訓練完的成果,我們的準確率達到了96%,已經算是合格了
到這裡,我們已經完成了第一個「深度學習實戰」。
從資料讀取、前處理,到建立模型與訓練,
整個流程算是深度學習的基本範例。
而且因為 Keras 的設計很直觀,
我們不需要去處理複雜的底層數學,就能很快得到成果。
這一步不只是「練習」,也之後做任何 AI 專案的基礎。

