目標先講清楚:
我要把既有的 LiveKit 語音代理,改成用 LangGraph 當「大腦」。
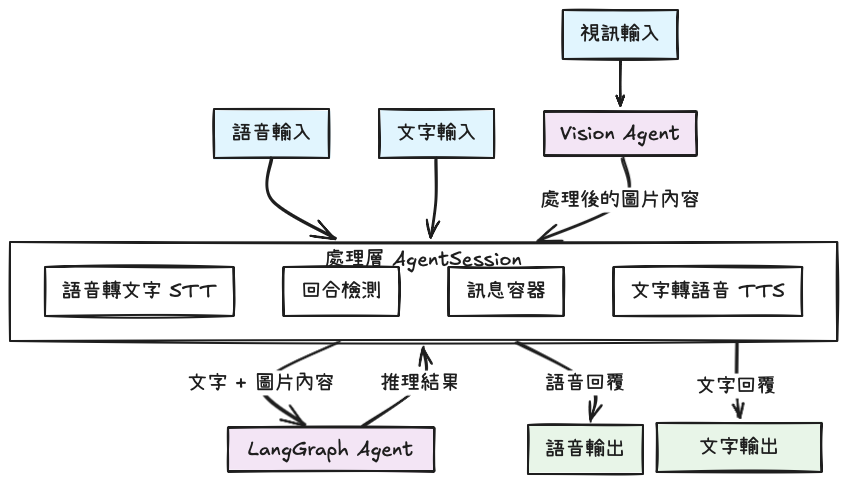
核心變更:把vision_agent的 LLM 換成 LangGraph workflow(viaLLMAdapter),讓 tools / memory / context 都能在「流程圖」上精細可控。
一句話:LiveKit 管即時媒體與連線;LangGraph 管推理流程與狀態。
LiveKit Agents 幫我處理 WebRTC、房間、音訊/視訊軌、斷句與串流回傳等「低延遲與穩定」的外殼;LangGraph 則把多步驟推理、工具呼叫、記憶寫成 StateGraph,讓每一步何時執行、如何彙整訊息都有明確邏輯。這樣未來要換模型、增工具、改記憶策略,都只碰流程層。
LiveKit 的 Agents 生態有一整套可直接跑的 examples:從 任務導向語音代理 到 Avatar、多模/即時 API、企業級運維能力。
| 面向 | 想打造什麼 | 起手 Example(路徑) | 會用到的技術 / 套件 |
|---|---|---|---|
| 客服/預約/點餐 | 得來速點餐、前台接聽、餐廳多代理 | examples/drive-thru/*、frontdesk/*、voice_agents/* |
Agents/Room I/O、OpenAI/Deepgram/Cartesia/Silero、Pydantic、轉彎偵測 |
| Avatar/音訊視覺化 | 說話頭像、品牌化輸出、波形→影像 | avatars/*、audio_wave/* |
Realtime、VideoGenerator、NumPy/FFT、OpenCV |
| 語音代理樣板與技巧 | 背景音/變速/說話者分離、結構化輸出、工具註冊 | voice_agents/* |
多說話者標記、librosa、Pydantic/Enum、錯誤回呼/壽命管理 |
| 即時 API/多模整合 | 天氣/搜尋/笑話、Gemini 視訊理解、Ultravox | realtime/*、rag/* 等 |
外部 HTTP/Realtime API、歷史載入、半級聯 |
| 基礎積木/運維能力 | E2EE、房間統計、最小 worker、暖轉接 | metrics/*、basics/* 等 |
端到端加密、RTC 監控、部署與測試藍圖 |
以上可在 livekit/agents 的 examples 目錄找到對應實作。
1) basic graph(最小可用)
先使用官方提供的基本範例,建立basic graph
# basic_graph.py
from typing import Annotated
from typing_extensions import TypedDict
from dotenv import load_dotenv
load_dotenv()
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai import ChatOpenAI # 也可用 init_chat_model("openai:gpt-4o-mini")
# 1) 定義狀態:messages 用 add_messages 自動合併訊息
class State(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
# 2) 節點:把歷史 messages 丟給 LLM,產生一則新的 AIMessage
def chatbot(state: State) -> dict:
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
ai = llm.invoke(state["messages"])
return {"messages": [ai]}
# 3) 組圖:START -> chatbot -> END
builder = StateGraph(State)
builder.add_node("chatbot", chatbot)
builder.add_edge(START, "chatbot")
builder.add_edge("chatbot", END)
# 4) 編譯成可呼叫的 graph
graph_flow = builder.compile()
2) 替換 vision_agent 的 LLM
把原本直連模型,改為 livekit.plugins.langchain.LLMAdapter(graph_flow)。這樣 LiveKit 仍然處理即時串流與回合切分,但推理走 LangGraph;中途若有工具呼叫與內部訊息,也能由圖管理)
# vision_agent.py(節錄)
from livekit import agents
from livekit.agents import AgentSession, Agent, RoomInputOptions
from livekit.plugins import deepgram, cartesia, silero, langchain # <— 注意引入 langchain 插件
from livekit.agents.turn_detectors.multilingual import MultilingualModel
from basic_graph import graph_flow # 我們剛剛編譯好的 LangGraph
async def entrypoint(ctx: agents.JobContext):
session = AgentSession(
stt=deepgram.STT(model="nova-3", language="multi"),
# 原本可能是 openai.LLM(...) 或 with_azure(...)
# llm=openai.LLM(model="gpt-4o-mini"),
# 現在改成把 LangGraph 當 LLM:
llm=langchain.LLMAdapter(graph_flow),
tts=cartesia.TTS(model="sonic-2", voice="f9a4b3a6-b44b-469f-90e3-c8e19bd30e99"),
vad=silero.VAD.load(),
turn_detection=MultilingualModel(),
)
agent = Agent(
instructions="You are a helpful voice AI assistant with vision capabilities."
)
await session.start(agent=agent, room=ctx.room, room_input_options=RoomInputOptions())
目前已準備好
basic_graph.py(最小 StateGraph)與vision_agent.py(把 LLM 換成 LLMAdapter),後續只要「加節點」就能擴充工具、記憶、上下文策略。
Default(5/5)—— 介紹我會使用什麼工具,來協助或排查整個服務

