在 Day4 文章裡,我們完成了 Notion Integration、API Token 設定,並用 /v1/users/me 測試過連線。今天要進一步實作:透過 Notion API 把 Database 內容完整拉出來,並進行初步清洗,讓我們的資料變得乾淨且可用。
本篇目標
今天我們會以一個 旅遊行程 Database 作為範例,這是我今年實際到釜山旅行的行程表,裡面存放每天的景點、交通、費用等資訊。
Kanban View
這是我用來安排出國行程最喜歡的View,很方便查看每日行程跟景點資訊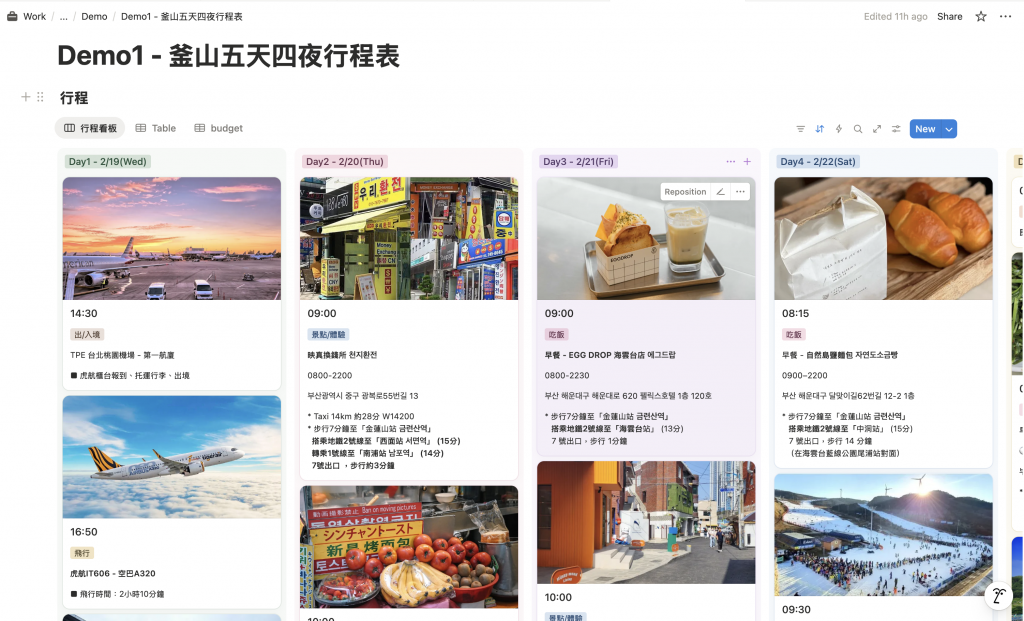
Table View
Property & Page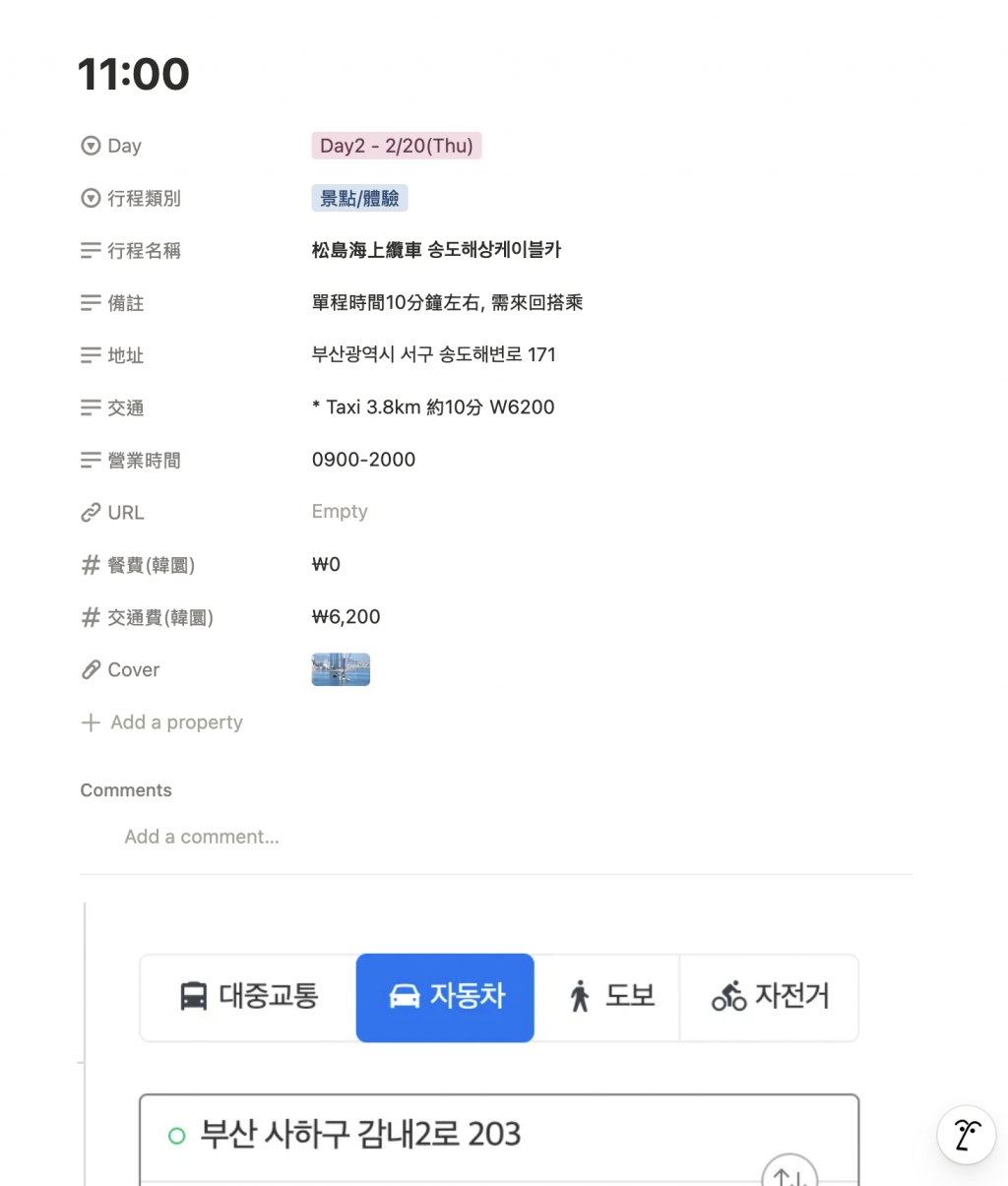
| 欄位名稱 | 資料型態 | 範例值 |
|---|---|---|
| Day | Select | Day2 - 2/20(Thu) |
| 行程類別 | Multi-select | 景點 / 體驗 |
| 行程名稱 | Title | 松島海上纜車 송도해상케이블카 |
| 備註 | Text | 單程時間10分鐘左右,需來回搭乘 |
| 地址 | Text | 부산광역시 서구 송도해변로 171 |
| 交通 | Text | Taxi 3.8km 約10分 ₩6200 |
| 營業時間 | Text | 0900-2000 |
| 餐費(韓國) | Number | ₩0 |
| 交通費(韓國) | Number | ₩6,200 |
| URL | URL | https://... (或 Empty) |
| Cover | File | 圖片 (e.g. 行程照片) |
這樣的結構很適合作為 行程知識庫,後續可以用來做:
要串接 API,需要知道 Database ID。這個 ID 會在 Notion 網址裡:
打開你的 Database,點選Copy link
網址會長得像範例這樣,Database ID通常是一串 32 位元的 UUID:
https://www.notion.so/yourworkspace/abcd1234efgh5678ijkl9012mnop3456?v=xxxx
👉 其中 abcd1234efgh5678ijkl9012mnop3456 就是 Database ID。
你可以把它存進 .env:
NOTION_DATABASE_ID=abcd1234efgh5678ijkl9012mnop3456
src/notion_fetch.py
用 /v1/databases/{database_id} 就能抓到 schema(欄位結構),並且列出欄位名稱與型別。
import requests, os
from dotenv import load_dotenv
load_dotenv()
token = os.getenv("NOTION_TOKEN")
database_id = os.getenv("NOTION_DATABASE_ID")
url = f"https://api.notion.com/v1/databases/{database_id}"
headers = {
"Authorization": f"Bearer {token}",
"Notion-Version": "2022-06-28"
}
res = requests.get(url, headers=headers)
data = res.json()
# 印出所有欄位名稱
for prop_name, prop_info in data["properties"].items():
print(prop_name, ":", prop_info["type"])
skip_fields = ["Cover"]
for prop_name, prop_info in data["properties"].items():
if prop_name in skip_fields:
continue
print(prop_name, ":", prop_info["type"])
地址 : rich_text
行程類別 : select
URL : url
備註 : rich_text
交通 : rich_text
餐費(韓圜) : number
交通費(韓圜) : number
營業時間 : rich_text
Day : select
行程名稱 : rich_text
當地時間 : title
這樣就可以取得乾淨的 欄位清單,能用來決定後續的清理規則(例如數字要統一單位、時間要正規化、multi_select 要展開)。
src/pull_database_records.py
使用 /v1/databases/{database_id}/query,並將結果展平為乾淨的結構:
import os, json, requests
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv("NOTION_TOKEN")
DB_ID = os.getenv("NOTION_DATABASE_ID")
BASE = "https://api.notion.com/v1"
HEADERS = {
"Authorization": f"Bearer {TOKEN}",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json",
}
# ---------- 1) 取得 Database schema ----------
def fetch_database_schema(database_id: str) -> dict:
url = f"{BASE}/databases/{database_id}"
res = requests.get(url, headers=HEADERS)
res.raise_for_status()
return res.json()["properties"] # { field_name: {type: ..., ...}, ... }
# ---------- 2) 查詢所有 rows(自動分頁) ----------
def query_database_all(database_id: str, page_size: int = 100) -> list:
url = f"{BASE}/databases/{database_id}/query"
payload = {"page_size": page_size}
results = []
while True:
res = requests.post(url, headers=HEADERS, json=payload)
res.raise_for_status()
data = res.json()
results.extend(data.get("results", []))
if not data.get("has_more"):
break
payload["start_cursor"] = data["next_cursor"]
return results # list of page objects
# ---------- 3) Notion 各型別 → Python 值 展平 ----------
def join_rich_text(arr):
if not arr: return ""
out = []
for rt in arr:
if "text" in rt and rt["text"]:
out.append(rt["text"].get("content", ""))
elif "plain_text" in rt: # 兼容 mention/equation 等
out.append(rt["plain_text"])
return "".join(out).strip()
def parse_property_value(prop_obj: dict, prop_type: str):
"""
將 Notion property 依 type 轉成「單一可用值」。
你可依需求再擴充 relation/rollup/people 等。
"""
p = prop_obj
if prop_type == "title":
return join_rich_text(p.get("title", []))
if prop_type == "rich_text":
return join_rich_text(p.get("rich_text", []))
if prop_type == "number":
return p.get("number", None)
if prop_type == "select":
sel = p.get("select")
return sel["name"] if sel else None
if prop_type == "multi_select":
return [t["name"] for t in p.get("multi_select", [])]
if prop_type == "url":
return p.get("url", None)
if prop_type == "email":
return p.get("email", None)
if prop_type == "phone_number":
return p.get("phone_number", None)
if prop_type == "checkbox":
return p.get("checkbox", None)
if prop_type == "date":
d = p.get("date")
if not d: return None
# 回傳 (start, end);若只需 start 可改 d.get("start")
return {"start": d.get("start"), "end": d.get("end")}
if prop_type == "files":
# 你說暫時不要 Cover,可在上層跳過此欄位
files = p.get("files", [])
# 仍提供第一個 URL 的取法,日後若要用得到:
if not files: return None
f = files[0]
if "file" in f: return f["file"]["url"]
if "external" in f: return f["external"]["url"]
return None
if prop_type == "people":
return [u.get("name") for u in p.get("people", [])]
if prop_type == "status":
st = p.get("status")
return st["name"] if st else None
if prop_type == "relation":
# 只回傳 relation 的 page_id 陣列(需要再 join 可延伸)
return [r.get("id") for r in p.get("relation", [])]
if prop_type == "created_time":
return p.get("created_time")
if prop_type == "last_edited_time":
return p.get("last_edited_time")
# 其它型別先原樣回傳,或視需求擴充
return p
# ---------- 4) 以 schema 動態展平一筆 row ----------
def flatten_row(page_obj: dict, schema: dict, skip_fields=None) -> dict:
skip_fields = set(skip_fields or [])
props = page_obj["properties"]
row = {"page_id": page_obj.get("id")}
for field_name, info in schema.items():
if field_name in skip_fields:
continue
ptype = info["type"]
row[field_name] = parse_property_value(props.get(field_name, {}), ptype)
return row
# ---------- 5) 主程式:輸出乾淨列資料 ----------
if __name__ == "__main__":
os.makedirs("data/clean", exist_ok=True)
# (a) 取得 schema
schema = fetch_database_schema(DB_ID)
# (b) 取得所有 rows
pages = query_database_all(DB_ID)
# (c) 指定要略過的欄位(依你的需求先排除 Cover)
skip = {"Cover"}
# (d) 展平
clean_rows = [flatten_row(p, schema, skip_fields=skip) for p in pages]
# (e) 存檔
with open("data/clean/database_rows.json", "w", encoding="utf-8") as f:
json.dump(clean_rows, f, ensure_ascii=False, indent=2)
# 可選:印幾筆確認
print(f"Total rows: {len(clean_rows)}")
for r in clean_rows[:3]:
print(r)
接下來我們就可以成功取得資料囉!
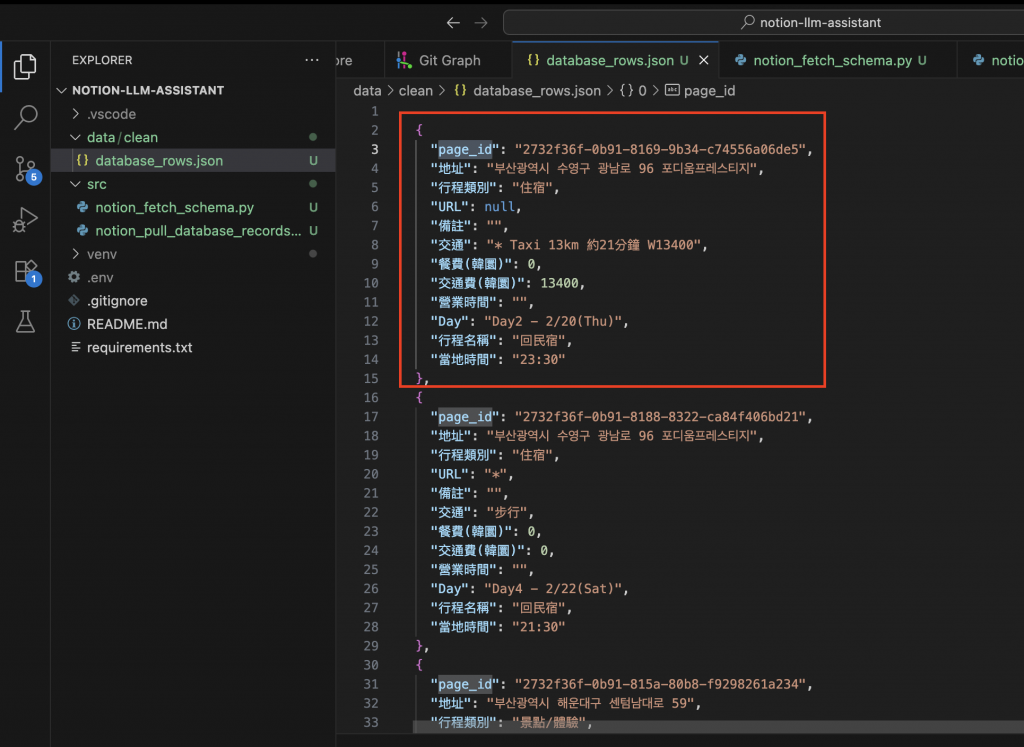
可以看到 database_rows.json 展開的模樣會有許多筆page_id,下一篇會再深入Page的實作。
今天我們完成了 Notion Database 資料的抓取與展平:
這讓原本複雜的 Notion JSON 結構,變成我們能直接使用的知識庫輸入。
Database 適合存「結構化資料」(例如行程、任務、專案),但 Notion 中還有大量「非結構化內容」,例如會議筆記、讀書心得、甚至一篇長文。這些內容存在 Page 與 Block 裡。
Day 6 我們會:

