在 Day 28,我們成功修復了向量資料庫的結構問題,讓資料流從 SQLite 到 ChromaDB 重新順暢起來。不過當我們開啟 Streamlit App 時,卻發現「參考來源」仍然顯示成一片混亂的 「⚠️ 未命名筆記 — 未分類」。這意味著——雖然資料通了,但 metadata 還沒跟上。
今天,我們要完成 Notion RAG 系統的最後一哩路:
讓每一段回答都能清楚標示「它來自哪裡」,並讓使用者可以一鍵開啟原始 Notion 筆記。
今日目標
完成 Notion RAG 系統的 Metadata 重構與 UI 優化,包含:
page_name, category, page_url)我們在測試階段發現,原本的 source_tracker.py 雖然能顯示來源,但讀取的 metadata 欄位與實際資料不一致:
metadata.get("Title"),但在 ChromaDB 裡實際欄位是 page_name
page_url,導致無法建立「查看原文」連結這些錯誤讓系統雖然能檢索結果,但使用者看不出這些資訊的「出處」。
src/rag/source_tracker.py上一版實作請參考【Day 26】用 Streamlit 打造會記憶的 AI 助理:對話記憶 × 來源追蹤實作
from typing import List, Dict, Tuple
from datetime import datetime
class SourceTracker:
"""
來源追蹤器
功能:
1. 格式化檢索到的來源
2. 評估來源可信度
3. 生成來源顯示內容
"""
def __init__(self):
self.tracked_sources = []
def format_sources(
self,
context_pairs: List[Tuple], # [(doc, metadata), ...]
similarities: List[float] = None, # 可選的相似度分數
max_snippet_length: int = 150
) -> List[Dict]:
"""
格式化檢索到的來源
Args:
context_pairs: retrieve_context 返回的 (doc, metadata) 對
similarities: 相似度分數列表(如果有的話)
max_snippet_length: 文字片段的最大長度
Returns:
格式化後的來源列表
"""
sources = []
for i, (doc, metadata) in enumerate(context_pairs):
# 如果沒有提供相似度,預設為 0.8
similarity = similarities[i] if similarities and i < len(similarities) else 0.8
source = {
"title": metadata.get("page_name", "未命名筆記"),
"category": metadata.get("category", "未分類"),
"url": metadata.get("page_url", ""),
"snippet": self._create_snippet(doc, max_snippet_length),
"similarity": round(float(similarity), 3),
"block_id": metadata.get("block_id", ""),
"confidence": self._calculate_confidence(similarity),
"retrieved_at": datetime.now().isoformat()
}
sources.append(source)
# 按相似度排序
sources.sort(key=lambda x: x["similarity"], reverse=True)
# 記錄追蹤
self.tracked_sources.extend(sources)
return sources
def _create_snippet(self, text: str, max_length: int) -> str:
"""
創建文字預覽片段
Args:
text: 完整文字
max_length: 最大長度
Returns:
截斷後的文字片段
"""
if not text:
return "(無內容)"
# 移除多餘空白
text = " ".join(text.split())
if len(text) <= max_length:
return text
# 截斷並添加省略號
return text[:max_length].rsplit(' ', 1)[0] + "..."
def _calculate_confidence(self, similarity_score: float) -> str:
"""
根據相似度分數計算可信度等級
Args:
similarity_score: 相似度分數 (0-1)
Returns:
可信度等級: "高", "中", "低"
"""
if similarity_score >= 0.85:
return "高"
elif similarity_score >= 0.70:
return "中"
else:
return "低"
def generate_display_text(self, sources: List[Dict], max_display: int = 3) -> str:
"""
生成來源顯示文字(用於 UI)
Args:
sources: 來源列表
max_display: 最多顯示幾個來源
Returns:
格式化的顯示文字
"""
if not sources:
return "📚 無參考來源"
display_sources = sources[:max_display]
lines = [f"📚 參考來源 ({len(sources)} 則筆記):\n"]
for i, source in enumerate(display_sources, 1):
# 可信度圖示
confidence_icon = self._get_confidence_icon(source["confidence"])
lines.append(
f"{i}. {confidence_icon} **{source['title']}** — {source['category']}"
)
lines.append(f" {source['snippet']}")
lines.append(f" 相似度: {self._format_similarity_bar(source['similarity'])}")
lines.append("")
if len(sources) > max_display:
lines.append(f"... 還有 {len(sources) - max_display} 則相關筆記")
return "\n".join(lines)
def _get_confidence_icon(self, confidence: str) -> str:
"""根據可信度返回對應圖示"""
icons = {
"高": "✅",
"中": "⚠️",
"低": "ℹ️"
}
return icons.get(confidence, "📄")
def _format_similarity_bar(self, similarity: float) -> str:
"""
格式化相似度為進度條
Args:
similarity: 相似度分數 (0-1)
Returns:
視覺化的進度條
"""
filled = int(similarity * 10)
bar = "█" * filled + "░" * (10 - filled)
percentage = int(similarity * 100)
return f"{bar} {percentage}%"
def get_stats(self) -> Dict:
"""
獲取來源追蹤統計
Returns:
統計資訊字典
"""
if not self.tracked_sources:
return {
"total_sources": 0,
"avg_similarity": 0,
"high_confidence": 0,
"medium_confidence": 0,
"low_confidence": 0
}
similarities = [s["similarity"] for s in self.tracked_sources]
confidences = [s["confidence"] for s in self.tracked_sources]
return {
"total_sources": len(self.tracked_sources),
"avg_similarity": round(sum(similarities) / len(similarities), 3),
"max_similarity": max(similarities),
"min_similarity": min(similarities),
"high_confidence": confidences.count("高"),
"medium_confidence": confidences.count("中"),
"low_confidence": confidences.count("低")
}
def clear_tracking(self):
"""清空追蹤記錄"""
self.tracked_sources = []
app.pyimport streamlit as st
from datetime import datetime
from src.rag import notion_rag_backend
# ===== 頁面配置 =====
st.set_page_config(
page_title="Notion × LLM 智慧助理",
page_icon="💬",
layout="wide",
initial_sidebar_state="expanded"
)
# ===== 自訂 CSS 樣式 =====
st.markdown("""
<style>
/* 主題色調 */
.stApp {
background-color: #f8f9fa;
}
/* 聊天訊息樣式 */
.chat-message {
padding: 1rem;
border-radius: 0.5rem;
margin-bottom: 1rem;
}
/* 來源區塊樣式 */
.source-box {
background-color: #fff3cd;
border-left: 4px solid #ffc107;
padding: 0.75rem;
margin-top: 0.5rem;
border-radius: 0.25rem;
}
/* 統計資訊樣式 */
.stats-box {
background-color: #e7f3ff;
padding: 1rem;
border-radius: 0.5rem;
border-left: 4px solid #2196F3;
}
</style>
""", unsafe_allow_html=True)
# ===== 標題 =====
st.title("💬 Notion × LLM 智慧助理")
st.markdown("透過對話的方式,探索你的 Notion 筆記")
# ===== 側邊欄設定 =====
with st.sidebar:
st.header("⚙️ 設定")
# 檢索設定
st.subheader("🔍 檢索設定")
top_k = st.slider(
"檢索數量",
min_value=1,
max_value=10,
value=3,
help="從知識庫中檢索幾筆相關內容"
)
similarity_threshold = st.slider(
"相似度門檻",
min_value=0.5,
max_value=0.95,
value=0.7,
step=0.05,
help="只顯示相似度高於此門檻的來源"
)
# LLM 設定
st.subheader("🤖 LLM 設定")
temperature = st.slider(
"創造力",
min_value=0.0,
max_value=1.0,
value=0.7,
step=0.1,
help="越高越有創意,越低越精確"
)
# 顯示設定
st.subheader("📊 顯示設定")
show_sources = st.checkbox("顯示筆記來源", value=True)
show_similarity = st.checkbox("顯示相似度分數", value=False)
show_timestamp = st.checkbox("顯示時間戳記", value=True)
# 記憶設定
st.subheader("🧠 記憶設定")
enable_memory = st.checkbox("啟用對話記憶", value=True, help="記住先前的對話內容")
# 分隔線
st.markdown("---")
# 操作按鈕
st.subheader("🛠️ 操作")
col1, col2 = st.columns(2)
with col1:
if st.button("🗑️ 清除對話", use_container_width=True):
notion_rag_backend.clear_memory()
st.session_state.chat_history = []
st.rerun()
with col2:
if st.button("📊 查看統計", use_container_width=True):
st.session_state.show_stats = True
if st.button("📥 匯出對話", use_container_width=True):
markdown = notion_rag_backend.export_conversation()
st.download_button(
label="下載 Markdown",
data=markdown,
file_name=f"conversation_{datetime.now().strftime('%Y%m%d_%H%M%S')}.md",
mime="text/markdown"
)
# 統計資訊
if st.session_state.get('show_stats', False):
st.markdown("---")
st.subheader("📈 統計資訊")
memory_stats = notion_rag_backend.get_memory_stats()
source_stats = notion_rag_backend.get_source_stats()
st.markdown(f"""
<div class="stats-box">
<b>記憶統計</b><br>
對話輪數: {memory_stats['turns']}<br>
記憶使用: {memory_stats['memory_usage']}<br>
<br>
<b>來源統計</b><br>
總來源數: {source_stats['total_sources']}<br>
平均相似度: {source_stats.get('avg_similarity', 0):.2f}
</div>
""", unsafe_allow_html=True)
if st.button("關閉統計"):
st.session_state.show_stats = False
st.rerun()
# ===== 初始化 session_state =====
if "chat_history" not in st.session_state:
st.session_state.chat_history = []
# ===== 主要對話區域 =====
# 顯示歷史對話
for i, msg in enumerate(st.session_state.chat_history):
with st.chat_message(msg["role"]):
# 顯示訊息內容
st.markdown(msg["content"])
# 顯示時間戳記
if show_timestamp and "timestamp" in msg:
st.caption(f"⏰ {msg['timestamp']}")
# 顯示來源(僅助理訊息)
if msg["role"] == "assistant" and show_sources and "sources" in msg:
sources = msg["sources"]
if sources:
with st.expander(f"📚 參考來源 ({len(sources)} 則筆記)", expanded=False):
for j, source in enumerate(sources, 1):
# 根據可信度選擇圖示
confidence_icons = {"高": "✅", "中": "⚠️", "低": "ℹ️"}
icon = confidence_icons.get(source.get('confidence', '中'), "📄")
# 顯示來源資訊
#st.markdown(f"""
#**{j}. {icon} {source['title']}** — {source['category']}
#""")
# 標題和連結按鈕
col1, col2 = st.columns([4, 1])
with col1:
st.markdown(f"**{j}. {icon} {source['title']}** — {source['category']}")
with col2:
if source.get('url'):
st.link_button(
"📝 筆記連結",
source['url'],
use_container_width=True
)
# 顯示文字片段
st.caption(source['snippet'])
# 可選:顯示相似度
if show_similarity:
similarity = source['similarity']
st.progress(similarity, text=f"相似度: {similarity:.2%}")
if j < len(sources):
st.markdown("---")
# ===== 使用者輸入 =====
user_query = st.chat_input("💬 請輸入你的問題...")
if user_query:
# 立即顯示使用者訊息
timestamp = datetime.now().strftime("%H:%M:%S")
with st.chat_message("user"):
st.markdown(user_query)
if show_timestamp:
st.caption(f"⏰ {timestamp}")
# 儲存使用者訊息
st.session_state.chat_history.append({
"role": "user",
"content": user_query,
"timestamp": timestamp
})
# 顯示載入狀態
with st.chat_message("assistant"):
with st.spinner("🔄 思考中..."):
try:
# 根據設定選擇是否使用記憶
if enable_memory:
answer, sources = notion_rag_backend.generate_answer_with_memory(
user_query,
top_k=top_k
)
else:
# 使用舊版本(無記憶)
answer = notion_rag_backend.generate_answer(user_query)
sources = []
# 過濾低相似度的來源
if sources:
sources = [s for s in sources if s['similarity'] >= similarity_threshold]
# 顯示回答
st.markdown(answer)
# 顯示時間戳記
assistant_timestamp = datetime.now().strftime("%H:%M:%S")
if show_timestamp:
st.caption(f"⏰ {assistant_timestamp}")
# 顯示來源
if sources and show_sources:
with st.expander(f"📚 參考來源 ({len(sources)} 則筆記)", expanded=False):
for j, source in enumerate(sources, 1):
confidence_icons = {"高": "✅", "中": "⚠️", "低": "ℹ️"}
icon = confidence_icons.get(source.get('confidence', '中'), "📄")
#st.markdown(f"""
#**{j}. {icon} {source['title']}** — {source['category']}
#""")
# 標題和連結按鈕
col1, col2 = st.columns([4, 1])
with col1:
st.markdown(f"**{j}. {icon} {source['title']}** — {source['category']}")
with col2:
if source.get('url'):
st.link_button(
"📝 筆記連結",
source['url'],
use_container_width=True
)
st.caption(source['snippet'])
if show_similarity:
similarity = source['similarity']
st.progress(similarity, text=f"相似度: {similarity:.2%}")
if j < len(sources):
st.markdown("---")
# 儲存助理回答
st.session_state.chat_history.append({
"role": "assistant",
"content": answer,
"sources": sources,
"timestamp": assistant_timestamp
})
except Exception as e:
st.error(f"❌ 發生錯誤: {str(e)}")
st.exception(e)
# 重新執行以更新顯示
st.rerun()
# ===== 頁尾資訊 =====
st.markdown("---")
col1, col2, col3 = st.columns(3)
with col1:
if st.session_state.chat_history:
turns = len([m for m in st.session_state.chat_history if m["role"] == "user"])
st.metric("對話輪數", turns)
with col2:
memory_stats = notion_rag_backend.get_memory_stats()
st.metric("記憶使用", memory_stats['memory_usage'])
with col3:
if enable_memory:
st.success("🧠 對話記憶已啟用")
else:
st.info("💤 對話記憶已停用")
┌─────────────────────────────────────────────────────────┐
│ 1. SQLite (notion.db) │
│ - notion_databases (database_name, category) │
│ - notion_pages (page_name, page_url, page_properties)│
│ - notion_blocks (block_text, order_index) │
└─────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 2. Embedding Pipeline (embed_notion_chunks.py) │
│ - 從 SQLite 撈取 blocks │
│ - Chunking (500 chars, 50 overlap) │
│ - OpenAI Embedding API │
│ - 寫入 ChromaDB (含完整 metadata) │
└─────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 3. ChromaDB (data/chroma_db) │
│ documents: [chunk_text_1, chunk_text_2, ...] │
│ metadatas: [{ │
│ page_name: "Class 類別", │
│ category: "Learning", │
│ page_url: "https://notion.so/...", │
│ database_name: "Python 學習筆記", │
│ ... │
│ }] │
│ embeddings: [[0.123, 0.456, ...], ...] │
└─────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 4. RAG Backend (notion_rag_backend.py) │
│ - 使用者問題 → OpenAI Embedding │
│ - ChromaDB 向量搜尋 │
│ - 返回 (documents, metadatas, distances) │
└─────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 5. Source Tracker (source_tracker.py) │
│ - format_sources(results) │
│ - 提取 page_name, category, page_url │
│ - 計算相似度和可信度 │
│ - 返回格式化的 sources │
└─────────────────┬───────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ 6. Streamlit UI (app.py) │
│ - 顯示標題: source['title'] │
│ - 顯示分類: source['category'] │
│ - 連結按鈕: source['url'] │
│ - 相似度條: source['similarity'] │
└─────────────────────────────────────────────────────────┘
最後讓我們來看一下 Notion Rag 實作結果吧!
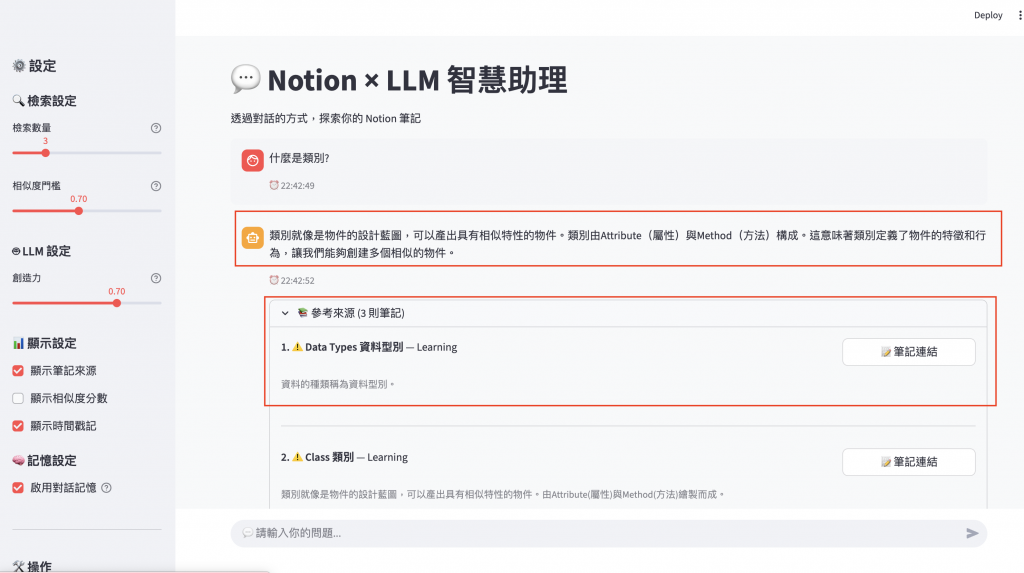
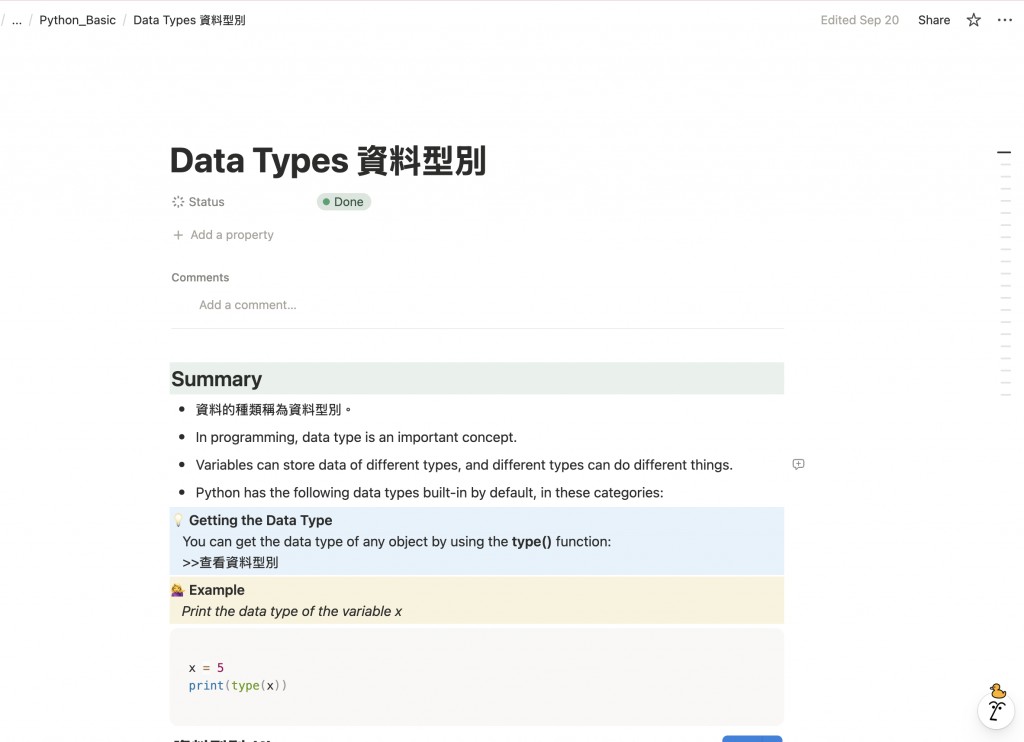
查看統計資訊
點選「查看統計」,可呈現目前的統計資訊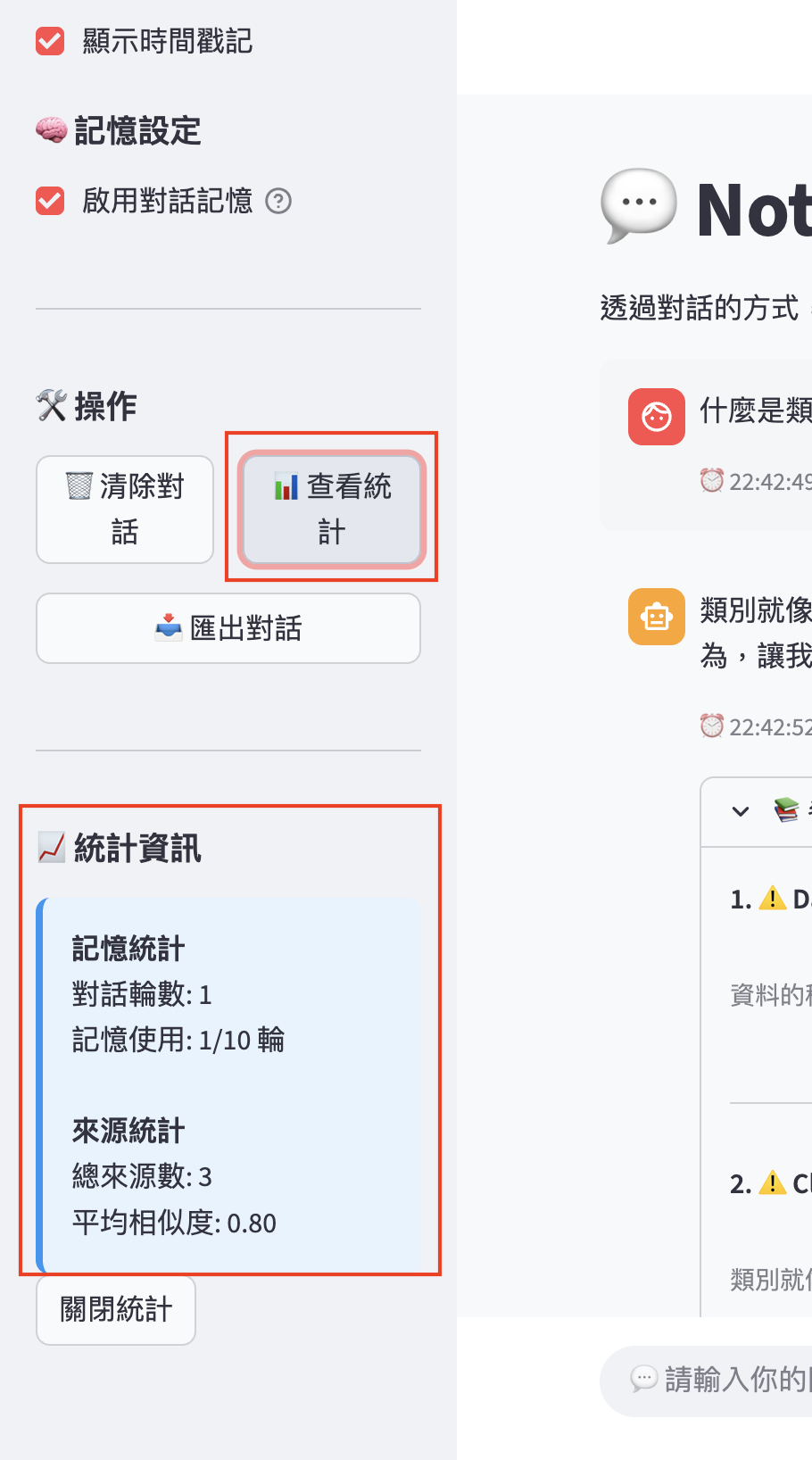
匯出對話
點選「匯出對話」,會跳出「下載 Markdown」的按鈕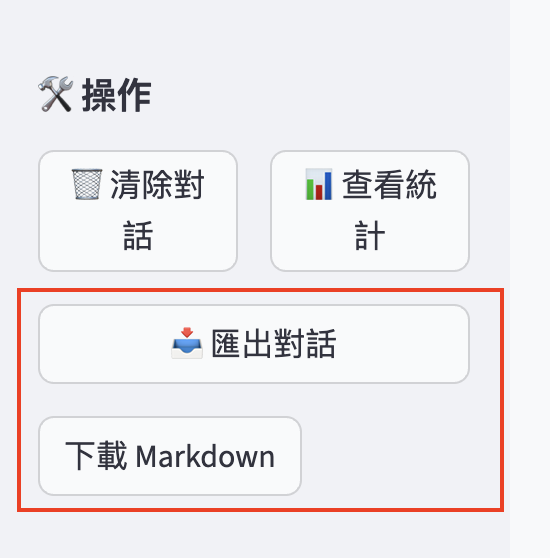
下載的對話紀錄.md如下: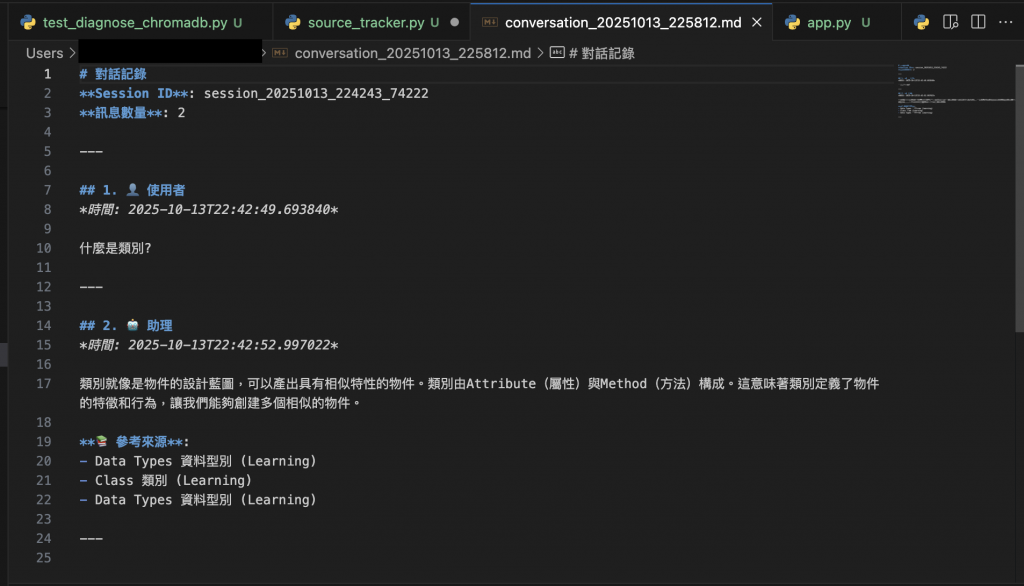
清空對話
點選「清空對話」,即可將目前對話窗清除
恭喜!我們的 Notion RAG 系統的核心功能已經可以運作了!
今天我們完成了最後一塊拼圖:
完整的 Metadata 流(SQLite → ChromaDB → UI)。現在每個回答都帶著正確的出處、分類與可點擊的 Notion 連結,不再是「未命名筆記」或「未分類」。
明天將迎來這個系列的最終章!
我會帶你回顧整個 Notion 遇上 LLM:30 天打造我的 AI 知識管理系統 的完整旅程,並分享進階擴展方向與最佳實踐!



 iThome鐵人賽
iThome鐵人賽