在 Day 27,我們深入診斷了系統中的關於 metadata 四個關鍵問題,並制定了完整的修正計畫。今天我們要動手實作,按照既定的順序逐步完成所有修正:
src/scirpts/migrate_sqlite_schema.py
import sqlite3
import shutil
import os
from datetime import datetime
from pathlib import Path
"""
SQLite Schema 遷移腳本
目的:新增 page_url 和 page_properties 欄位
"""
# 設定路徑
PROJECT_ROOT = Path(__file__).parent.parent.parent
DB_PATH = PROJECT_ROOT / "data" / "notion.db"
def backup_database(db_path):
"""備份資料庫"""
if not os.path.exists(db_path):
raise FileNotFoundError(f"找不到資料庫: {db_path}")
# 建立備份檔名(帶時間戳)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
backup_path = f"{db_path}.backup_{timestamp}"
# 複製檔案
shutil.copy2(db_path, backup_path)
# 取得檔案大小
size_mb = os.path.getsize(backup_path) / (1024 * 1024)
print(f"✅ 資料庫已備份")
print(f" 位置: {backup_path}")
print(f" 大小: {size_mb:.2f} MB")
return backup_path
def migrate_schema(db_path):
"""遷移 Schema 到新版本"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
try:
print("\n" + "="*50)
print("開始 Schema 遷移")
print("="*50)
# 檢查現有欄位
cursor.execute("PRAGMA table_info(notion_pages)")
existing_columns = [col[1] for col in cursor.fetchall()]
print(f"\n現有欄位: {', '.join(existing_columns)}")
migrations_performed = []
# 新增 page_url 欄位
if "page_url" not in existing_columns:
print("\n[1/2] 新增 page_url 欄位...")
cursor.execute("ALTER TABLE notion_pages ADD COLUMN page_url TEXT")
migrations_performed.append("page_url")
print(" ✅ 完成")
else:
print("\n[1/2] ✓ page_url 欄位已存在,跳過")
# 新增 page_properties 欄位
if "page_properties" not in existing_columns:
print("[2/2] 新增 page_properties 欄位...")
cursor.execute("ALTER TABLE notion_pages ADD COLUMN page_properties TEXT")
migrations_performed.append("page_properties")
print(" ✅ 完成")
else:
print("[2/2] ✓ page_properties 欄位已存在,跳過")
# 建立索引(提升查詢效能)
print("\n建立索引...")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_page_name
ON notion_pages(page_name)
""")
print(" ✅ idx_page_name")
cursor.execute("""
CREATE INDEX IF NOT EXISTS idx_database_id
ON notion_pages(database_id)
""")
print(" ✅ idx_database_id")
# 提交變更
conn.commit()
# 顯示結果
print("\n" + "="*50)
if migrations_performed:
print(f"✅ Schema 遷移完成!")
print(f" 新增欄位: {', '.join(migrations_performed)}")
else:
print("✅ Schema 已是最新版本,無需變更")
print("="*50)
return True
except Exception as e:
conn.rollback()
print(f"\n❌ 遷移失敗: {e}")
return False
finally:
conn.close()
def verify_migration(db_path):
"""驗證遷移是否成功"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
try:
print("\n" + "="*50)
print("驗證 Schema")
print("="*50)
# 檢查欄位
cursor.execute("PRAGMA table_info(notion_pages)")
columns = {col[1]: col[2] for col in cursor.fetchall()}
required_columns = {
"page_id": "TEXT",
"page_name": "TEXT",
"page_url": "TEXT",
"page_properties": "TEXT",
"database_id": "TEXT",
"created_time": "TEXT",
"last_edited_time": "TEXT"
}
print("\n【欄位檢查】")
all_columns_ok = True
for col_name, col_type in required_columns.items():
if col_name in columns:
print(f" ✅ {col_name:<20} ({col_type})")
else:
print(f" ❌ {col_name:<20} 缺少此欄位")
all_columns_ok = False
# 檢查索引
cursor.execute("PRAGMA index_list(notion_pages)")
indexes = [idx[1] for idx in cursor.fetchall()]
print("\n【索引檢查】")
required_indexes = ["idx_page_name", "idx_database_id"]
all_indexes_ok = True
for idx_name in required_indexes:
if idx_name in indexes:
print(f" ✅ {idx_name}")
else:
print(f" ⚠️ {idx_name} (缺少此索引)")
all_indexes_ok = False
# 總結
print("\n" + "="*50)
if all_columns_ok and all_indexes_ok:
print("✅ 驗證通過!Schema 遷移成功")
else:
print("⚠️ 部分驗證項目未通過")
print("="*50)
return all_columns_ok and all_indexes_ok
finally:
conn.close()
def cleanup_backup(backup_path, force=False):
"""清理備份檔案(可選)"""
if not os.path.exists(backup_path):
print(f"⚠️ 備份檔案不存在: {backup_path}")
return
if force:
os.remove(backup_path)
print(f"🗑️ 已刪除備份: {backup_path}")
else:
print(f"\n備份檔案位置: {backup_path}")
print("建議:先執行完整測試,確認系統運作正常後再手動刪除備份")
response = input("\n確定要刪除備份檔案嗎? [y/N]: ")
if response.lower() == 'y':
os.remove(backup_path)
print(f"🗑️ 已刪除備份: {backup_path}")
else:
print(f"✓ 保留備份")
def main():
"""完整的 Schema 遷移流程"""
print("="*50)
print("SQLite Schema 遷移工具")
print("="*50)
print(f"資料庫位置: {DB_PATH}")
# 確認是否繼續
response = input("\n確定要執行遷移嗎? [y/N]: ")
if response.lower() != 'y':
print("已取消")
return
# Step 1: 備份
print("\n【Step 1: 備份資料庫】")
try:
backup_path = backup_database(DB_PATH)
except Exception as e:
print(f"❌ 備份失敗: {e}")
return
# Step 2: 遷移
print("\n【Step 2: 執行遷移】")
success = migrate_schema(DB_PATH)
if not success:
print(f"\n⚠️ 遷移失敗!")
print(f"請檢查備份: {backup_path}")
return
# Step 3: 驗證
print("\n【Step 3: 驗證結果】")
verified = verify_migration(DB_PATH)
# Step 4: 清理備份(可選)
if verified:
print("\n【Step 4: 備份管理】")
cleanup_backup(backup_path, force=False)
else:
print(f"\n⚠️ 驗證未通過,請保留備份: {backup_path}")
if __name__ == "__main__":
main()
# print('PROJECT_ROOT=', PROJECT_ROOT)
# 執行遷移腳本
python scripts/migrate_schema.py
Phase 1 完成! 現在我們的資料庫已經有 page_url 和 page_properties 欄位了。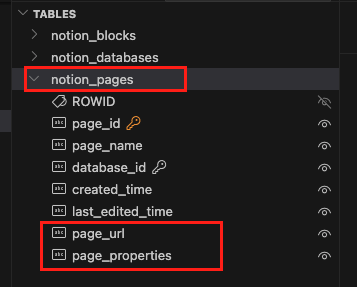
同步更新我們的 ERD,在 notion_pages 加上 page_url 和 page_properties: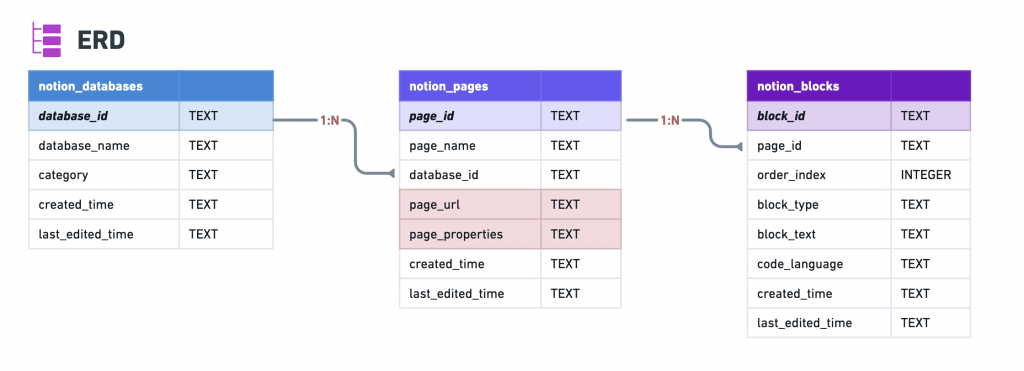
def extract_properties()src/fetch/fetch_database.py
import os, requests
from dotenv import load_dotenv
load_dotenv()
"""
抓取 Notion Database 的 metadata 和 Pages
1. 取得 Database 資訊
2. 查詢 Database 內所有 Pages
3. 萃取並清理 Properties
"""
TOKEN = os.getenv("NOTION_TOKEN")
HEADERS = {
"Authorization": f"Bearer {TOKEN}",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json",
}
BASE = "https://api.notion.com/v1"
def join_text(arr):
"""將 rich_text / title 陣列合併成單一字串"""
if not arr:
return ""
return "".join([t.get("plain_text", "") for t in arr]).strip()
def extract_properties(properties: dict) -> dict:
"""
萃取並清理 Notion properties
將各種類型的 property 轉換為乾淨的 dict 格式
Args:
properties: Notion API 回傳的 properties 物件
Returns:
清理後的 properties dict
"""
cleaned = {}
for prop_name, prop_value in properties.items():
prop_type = prop_value.get("type")
try:
if prop_type == "title":
# Title 類型
cleaned[prop_name] = join_text(prop_value.get("title", []))
elif prop_type == "rich_text":
# Rich Text 類型
cleaned[prop_name] = join_text(prop_value.get("rich_text", []))
elif prop_type == "select":
# Select 類型(單選)
select_obj = prop_value.get("select")
cleaned[prop_name] = select_obj.get("name") if select_obj else None
elif prop_type == "multi_select":
# Multi-select 類型(多選)
cleaned[prop_name] = [
item.get("name") for item in prop_value.get("multi_select", [])
]
elif prop_type == "date":
# Date 類型
date_obj = prop_value.get("date")
if date_obj:
cleaned[prop_name] = {
"start": date_obj.get("start"),
"end": date_obj.get("end")
}
else:
cleaned[prop_name] = None
elif prop_type == "number":
# Number 類型
cleaned[prop_name] = prop_value.get("number")
elif prop_type == "checkbox":
# Checkbox 類型
cleaned[prop_name] = prop_value.get("checkbox", False)
elif prop_type == "url":
# URL 類型
cleaned[prop_name] = prop_value.get("url")
elif prop_type == "email":
# Email 類型
cleaned[prop_name] = prop_value.get("email")
elif prop_type == "phone_number":
# Phone 類型
cleaned[prop_name] = prop_value.get("phone_number")
elif prop_type == "status":
# Status 類型
status_obj = prop_value.get("status")
cleaned[prop_name] = status_obj.get("name") if status_obj else None
elif prop_type == "people":
# People 類型
people_list = prop_value.get("people", [])
cleaned[prop_name] = [
person.get("name") or person.get("id", "")
for person in people_list
]
elif prop_type == "files":
# Files 類型
files = []
for file_obj in prop_value.get("files", []):
if file_obj.get("type") == "external":
url = file_obj.get("external", {}).get("url", "")
if url:
files.append(url)
elif file_obj.get("type") == "file":
url = file_obj.get("file", {}).get("url", "")
if url:
files.append(url)
cleaned[prop_name] = files
elif prop_type == "relation":
# Relation 類型(關聯到其他頁面)
cleaned[prop_name] = [
rel.get("id") for rel in prop_value.get("relation", [])
]
elif prop_type == "formula":
# Formula 類型
formula_obj = prop_value.get("formula", {})
formula_type = formula_obj.get("type")
if formula_type in ["string", "number", "boolean", "date"]:
cleaned[prop_name] = formula_obj.get(formula_type)
else:
cleaned[prop_name] = None
elif prop_type == "rollup":
# Rollup 類型
rollup_obj = prop_value.get("rollup", {})
rollup_type = rollup_obj.get("type")
if rollup_type in ["number", "date", "array"]:
cleaned[prop_name] = rollup_obj.get(rollup_type)
else:
cleaned[prop_name] = None
else:
# 未知類型,保留原始值
cleaned[prop_name] = prop_value
except Exception as e:
# 如果某個 property 解析失敗,記錄但不中斷
print(f" ⚠️ 解析 property '{prop_name}' ({prop_type}) 失敗: {e}")
cleaned[prop_name] = None
return cleaned
def fetch_database_meta(database_id: str) -> dict:
"""
取得 Database 本體的 metadata(含 created_time / last_edited_time / 名稱)
Args:
database_id: Database ID
Returns:
Database metadata dict
"""
url = f"{BASE}/databases/{database_id}"
res = requests.get(url, headers=HEADERS)
res.raise_for_status()
data = res.json()
# 嘗試抓 database 名稱(有些 DB 會把名稱放在 title 陣列)
db_name = join_text(data.get("title", [])) or data.get("id")
return {
"database_id": data["id"].replace("-", ""),
"database_name": db_name,
"created_time": data.get("created_time"),
"last_edited_time": data.get("last_edited_time"),
#"raw": data, # 保留原始,方便除錯(寫檔時可忽略)
}
def query_database_all(database_id: str, page_size: int = 100) -> list:
"""
查詢 Database 的 rows(每筆 row 實際上是一個 Page)
並補上 page_name / page_url / properties / created_time / last_edited_time
Args:
database_id: Database ID
page_size: 每次查詢的頁面數量
Returns:
Pages 列表
"""
url = f"{BASE}/databases/{database_id}/query"
payload = {"page_size": page_size}
results = []
while True:
res = requests.post(url, headers=HEADERS, json=payload)
res.raise_for_status()
data = res.json()
for row in data.get("results", []):
page_id = row["id"]
page_url = row.get("url", "") # Notion 網頁連結
created_time = row.get("created_time")
last_edited_time = row.get("last_edited_time")
# 找出第一個 title 欄位當作 page_name
page_name = None
for prop in row["properties"].values():
if prop["type"] == "title":
page_name = join_text(prop.get("title", []))
break
# 萃取並清理 properties
row["properties"] = extract_properties(row["properties"])
results.append({
"id": page_id,
"page_id": page_id, # 方便下游語意一致
"page_name": page_name,
"page_url": page_url, # ✅ 新增
"page_properties": row["properties"], # 清理後的 properties
"created_time": created_time,
"last_edited_time": last_edited_time,
#"properties": row["properties"], # 保留原始屬性
})
if not data.get("has_more"):
break
payload["start_cursor"] = data["next_cursor"]
return results
src/pipeline/run_notion_to_json.py (原run_notion_pipeline.py)
import os, json, yaml, sys
from pathlib import Path
from dotenv import load_dotenv
project_root = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, project_root)
from src.fetch.fetch_database import fetch_database_meta, query_database_all
from src.fetch.fetch_page import fetch_page_blocks
from src.preprocess.parse_blocks import parse_block
load_dotenv()
"""
Notion api 資料處理 Pipeline
1. 讀取 config/databases.yml
2. 針對每個 Database:
A) 讀取 Database 中繼資料(名稱、建立時間等)
B) 查詢 Database 內所有 rows → Page 清單
C) 針對每個 Page 抓取其 blocks
D) 解析每個 Block,補上 order_index
E) 以 Database 名稱分檔輸出 JSON
"""
# 設定路徑
PROJECT_ROOT = Path(__file__).parent.parent.parent
OUTPUT_DIR = PROJECT_ROOT / "data" / "clean"
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
def run_pipeline(config_path="config/databases.yml"):
"""執行完整的資料處理流程"""
# 讀取設定檔
with open(config_path, "r", encoding="utf-8") as f:
config = yaml.safe_load(f)
print("="*60)
print("Notion API 資料處理 Pipeline")
print("="*60)
# 處理每個 Database
for db in config["databases"]:
db_id = db["id"]
db_name = db["name"]
category = db.get("category")
print(f"\n{'='*60}")
print(f"處理 Database: {db_name}")
print(f"分類: {category}")
print(f"{'='*60}")
# A) 讀取 Database 中繼資料
print("\n[A] 讀取 Database 中繼資料...")
meta = fetch_database_meta(db_id)
meta["database_name"] = db_name # 以 YAML 中的 name 蓋過 meta 的 title(可自行選擇是否覆蓋)
meta["category"] = category
print(f" ✅ Database ID: {meta['database_id']}")
# B) 查詢 rows → Page 清單
print("\n[B] 查詢 Database 內的所有 Pages...")
rows = query_database_all(db_id)
print(f" Rows: {len(rows)}")
print(f" ✅ 找到 {len(rows)} 個頁面")
# 收集資料
db_pages = []
db_blocks = []
# C-E) 針對每個 Page 處理
print("\n[C-E] 處理每個 Page...")
for i, row in enumerate(rows, 1):
page_id = row["page_id"]
page_name = row.get("page_name", "")
page_url = row.get("page_url", "")
page_properties = row["page_properties"]
page_created = row.get("created_time")
page_edited = row.get("last_edited_time")
print(f" [{i}/{len(rows)}] {page_name}")
# C) 抓該 Page 的 blocks
blocks_raw = fetch_page_blocks(page_id)
# D) 解析每個 block,補上 order_index
parsed_blocks = [
parse_block(b, idx) for idx, b in enumerate(blocks_raw)
]
# E) 收集頁面資料(✅ 完整資料)
db_pages.append({
"page_id": page_id,
"page_name": page_name,
"page_url": page_url, # ✅ 有 URL
"page_properties": page_properties, # ✅ 有 properties
"database_id": meta["database_id"],
"created_time": row["created_time"],
"last_edited_time": row["last_edited_time"],
})
# E) 收集 blocks
#db_blocks.extend(parsed_blocks)
for pb in parsed_blocks:
# 附上 page_id 以便後續寫入 notion_blocks
pb["page_id"] = page_id
db_blocks.append(pb)
# F) 輸出 JSON
print("\n[F] 輸出 JSON 檔案...")
safe_name = f"{category}_{db_name.replace(' ', '_')}"
out_path = OUTPUT_DIR / f"{safe_name}.json"
payload = {
"database": {
"database_id": meta["database_id"],
"database_name": meta["database_name"],
"category": meta.get("category"),
"created_time": meta.get("created_time"),
"last_edited_time": meta.get("last_edited_time"),
},
"pages": db_pages,
"blocks": db_blocks,
}
with open(out_path, "w", encoding="utf-8") as f:
json.dump(payload, f, ensure_ascii=False, indent=2)
print(f" ✅ 已儲存: {out_path}")
print(f" 📊 統計: {len(db_pages)} 個頁面, {len(db_blocks)} 個區塊")
print("\n" + "="*60)
print("✅ Pipeline 執行完成!")
print("="*60)
if __name__ == "__main__":
run_pipeline()
python -m src.pipeline.run_notion_to_json
Phase 2 完成! 現在我們已經從 Notion API 取得完整的頁面資訊了,可以在JSON檔看到pages已出現 page_url 及 page_properties 資訊。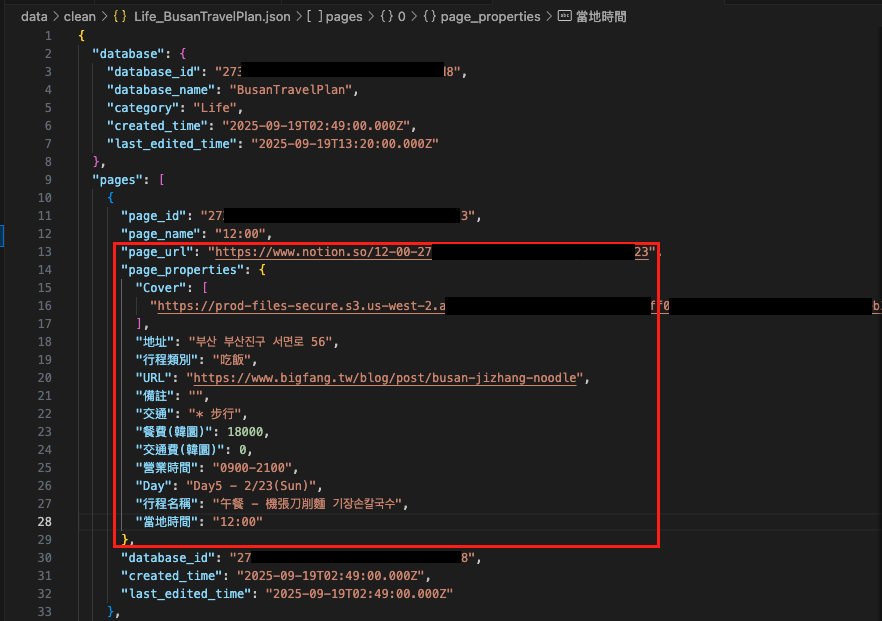
load_to_sqlite.pyimport os, json, sqlite3
from pathlib import Path
from datetime import datetime
from typing import Dict, Any, List, Optional
"""
將清理好的 JSON 檔案匯入 SQLite 資料庫
1. 讀取 data/clean/*.json
2. 寫入 data/notion.db
"""
# 設定路徑
PROJECT_ROOT = Path(__file__).parent.parent.parent
DB_PATH = PROJECT_ROOT / "data" / "notion.db"
CLEAN_DIR = PROJECT_ROOT / "data" / "clean"
def should_update(created_time: str, last_edited_time: str, run_date: str) -> bool:
"""
判斷是否需要更新
條件:run_date <= created_time OR run_date <= last_edited_time
Args:
created_time: 建立時間 (ISO 格式)
last_edited_time: 最後編輯時間 (ISO 格式)
run_date: 執行日期 (ISO 格式或 'YYYY-MM-DD')
Returns:
是否需要更新
"""
if not run_date:
# 如果沒有指定 run_date,則全部更新
return True
try:
# 轉換為可比較的格式(只比較日期部分)
run_dt = run_date[:10] if len(run_date) >= 10 else run_date
created_dt = created_time[:10] if created_time else ""
edited_dt = last_edited_time[:10] if last_edited_time else ""
# run_date <= created_time OR run_date <= last_edited_time
return run_dt <= created_dt or run_dt <= edited_dt
except Exception as e:
print(f" ⚠️ 日期比較失敗: {e}, 預設更新")
return True
# database upsert
def upsert_database(
conn: sqlite3.Connection,
db_data: Dict[str, Any],
run_date: Optional[str] = None
) -> bool:
"""
Upsert Database 資料
Args:
conn: SQLite 連線
db_data: Database 資料
run_date: 執行日期(可選)
Returns:
是否有更新
"""
# 判斷是否需要更新
if not should_update(
db_data.get("created_time", ""),
db_data.get("last_edited_time", ""),
run_date
):
return False
cursor = conn.cursor()
# Delete + Insert
cursor.execute(
"DELETE FROM notion_databases WHERE database_id = ?",
(db_data["database_id"],)
)
cursor.execute("""
INSERT INTO notion_databases
(database_id, database_name, category, created_time, last_edited_time)
VALUES (?, ?, ?, ?, ?)
""", (
db_data["database_id"],
db_data["database_name"],
db_data.get("category"),
db_data.get("created_time"),
db_data.get("last_edited_time")
))
return True
# page upsert
def upsert_page(
conn: sqlite3.Connection,
page_data: Dict[str, Any],
run_date: Optional[str] = None
) -> bool:
"""
Upsert Page 資料
Args:
conn: SQLite 連線
page_data: Page 資料
run_date: 執行日期(可選)
Returns:
是否有更新
"""
# 判斷是否需要更新
if not should_update(
page_data.get("created_time", ""),
page_data.get("last_edited_time", ""),
run_date
):
return False
cursor = conn.cursor()
# 將 page_properties 轉為 JSON 字串
properties_json = json.dumps(
page_data.get("page_properties", {}),
ensure_ascii=False
)
# Delete + Insert
cursor.execute(
"DELETE FROM notion_pages WHERE page_id = ?",
(page_data["page_id"],)
)
cursor.execute("""
INSERT INTO notion_pages
(page_id, page_name, page_url, page_properties,
database_id, created_time, last_edited_time)
VALUES (?, ?, ?, ?, ?, ?, ?)
""", (
page_data["page_id"],
page_data.get("page_name", "無標題"),
page_data.get("page_url", ""),
properties_json,
page_data["database_id"],
page_data.get("created_time"),
page_data.get("last_edited_time")
))
return True
# block upsert
def upsert_blocks_for_page(
conn: sqlite3.Connection,
page_id: str,
blocks: List[Dict[str, Any]],
run_date: Optional[str] = None
) -> int:
"""
Upsert 單一頁面的所有 Blocks
Args:
conn: SQLite 連線
page_id: 頁面 ID
blocks: 該頁面的所有 blocks
run_date: 執行日期(可選)
Returns:
更新的 block 數量
"""
if not blocks:
return 0
cursor = conn.cursor()
updated_count = 0
# 檢查是否需要更新這個頁面的 blocks
# 只要有任一 block 需要更新,就全部更新(保持一致性)
needs_update = False
for block in blocks:
if should_update(
block.get("created_time", ""),
block.get("last_edited_time", ""),
run_date
):
needs_update = True
break
if not needs_update:
return 0
# 刪除該頁面的所有舊 blocks
cursor.execute(
"DELETE FROM notion_blocks WHERE page_id = ?",
(page_id,)
)
# 插入新 blocks
for block in blocks:
cursor.execute("""
INSERT INTO notion_blocks
(block_id, page_id, order_index, block_type, block_text,
code_language, created_time, last_edited_time)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
block["block_id"],
page_id,
block.get("order_index", 0),
block.get("block_type", ""),
block.get("block_text", ""),
block.get("code_language"),
block.get("created_time"),
block.get("last_edited_time")
))
updated_count += 1
return updated_count
def load_json_to_sqlite(
json_path: Path,
db_path: Path = DB_PATH,
run_date: Optional[str] = None
) -> Dict[str, int]:
"""
載入單一 JSON 檔案到 SQLite(智能增量更新)
Args:
json_path: JSON 檔案路徑
db_path: SQLite 資料庫路徑
run_date: 執行日期(格式:YYYY-MM-DD 或 ISO),若為 None 則全部更新
Returns:
統計資訊 dict
"""
print(f"\n處理檔案: {json_path.name}")
if run_date:
print(f" 篩選條件: run_date <= {run_date}")
# 讀取 JSON
with open(json_path, "r", encoding="utf-8") as f:
data = json.load(f)
# 連接資料庫
conn = sqlite3.connect(db_path)
stats = {
"databases_updated": 0,
"pages_updated": 0,
"pages_skipped": 0,
"blocks_updated": 0,
"blocks_skipped": 0
}
try:
# 開始交易
conn.execute("BEGIN")
# 取得資料
db_data = data["database"]
pages = data["pages"]
blocks = data["blocks"]
# 1. Upsert Database
if upsert_database(conn, db_data, run_date):
stats["databases_updated"] += 1
print(f" ✅ Database: {db_data['database_name']} (已更新)")
else:
print(f" ⏭️ Database: {db_data['database_name']} (跳過)")
# 2. Upsert Pages
for page in pages:
if upsert_page(conn, page, run_date):
stats["pages_updated"] += 1
else:
stats["pages_skipped"] += 1
print(f" ✅ Pages: 更新 {stats['pages_updated']}, 跳過 {stats['pages_skipped']}")
# 3. 按頁面分組 blocks
blocks_by_page = {}
for block in blocks:
page_id = block["page_id"]
if page_id not in blocks_by_page:
blocks_by_page[page_id] = []
blocks_by_page[page_id].append(block)
# 4. Upsert Blocks(按頁面處理)
for page_id, page_blocks in blocks_by_page.items():
updated = upsert_blocks_for_page(conn, page_id, page_blocks, run_date)
if updated > 0:
stats["blocks_updated"] += updated
else:
stats["blocks_skipped"] += len(page_blocks)
print(f" ✅ Blocks: 更新 {stats['blocks_updated']}, 跳過 {stats['blocks_skipped']}")
# 提交交易
conn.commit()
print(f" ✅ 完成:{json_path.name}")
return stats
except Exception as e:
# 發生錯誤時回滾
conn.rollback()
print(f" ❌ 錯誤:{e}")
raise
finally:
conn.close()
def get_statistics(db_path: Path = DB_PATH) -> Dict[str, int]:
"""
取得資料庫統計資訊
"""
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
try:
cursor.execute("SELECT COUNT(*) FROM notion_databases")
db_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM notion_pages")
page_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM notion_blocks")
block_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM notion_pages WHERE page_url IS NOT NULL AND page_url != ''")
url_count = cursor.fetchone()[0]
cursor.execute("SELECT COUNT(*) FROM notion_pages WHERE page_properties IS NOT NULL AND page_properties != ''")
props_count = cursor.fetchone()[0]
return {
"databases": db_count,
"pages": page_count,
"blocks": block_count,
"pages_with_url": url_count,
"pages_with_properties": props_count
}
finally:
conn.close()
def main(run_date: Optional[str] = None):
"""
主程式
Args:
run_date: 執行日期(格式:YYYY-MM-DD),若為 None 則全部更新
"""
print("="*60)
print("將 JSON 檔案載入 SQLite(智能增量更新)")
print("="*60)
if run_date:
print(f"\n📅 執行日期: {run_date}")
print("只會更新在此日期之後建立或編輯的資料")
else:
print("\n📅 執行模式: 全量更新")
print("將更新所有資料")
# 確保目錄存在
CLEAN_DIR.mkdir(parents=True, exist_ok=True)
# 取得所有 JSON 檔案
json_files = list(CLEAN_DIR.glob("*.json"))
if not json_files:
print("\n⚠️ 找不到 JSON 檔案")
print(f"請確認 {CLEAN_DIR} 目錄中有 JSON 檔案")
return
print(f"\n找到 {len(json_files)} 個檔案")
# 處理每個檔案
success_count = 0
error_count = 0
total_stats = {
"databases_updated": 0,
"pages_updated": 0,
"pages_skipped": 0,
"blocks_updated": 0,
"blocks_skipped": 0
}
for json_file in json_files:
try:
stats = load_json_to_sqlite(json_file, run_date=run_date)
success_count += 1
# 累加統計
for key in total_stats:
total_stats[key] += stats[key]
except Exception as e:
error_count += 1
print(f" ❌ 處理失敗:{e}")
# 顯示總結
print("\n" + "="*60)
print("載入完成")
print("="*60)
print(f"成功: {success_count} 個檔案")
print(f"失敗: {error_count} 個檔案")
print("\n【更新統計】")
print(f" Databases 更新: {total_stats['databases_updated']}")
print(f" Pages 更新: {total_stats['pages_updated']}, 跳過: {total_stats['pages_skipped']}")
print(f" Blocks 更新: {total_stats['blocks_updated']}, 跳過: {total_stats['blocks_skipped']}")
# 顯示資料庫統計
print("\n【資料庫統計】")
db_stats = get_statistics()
print(f" Databases: {db_stats['databases']}")
print(f" Pages: {db_stats['pages']}")
print(f" Blocks: {db_stats['blocks']}")
print(f" 有 URL 的 Pages: {db_stats['pages_with_url']}")
print(f" 有 Properties 的 Pages: {db_stats['pages_with_properties']}")
print("\n✅ 所有檔案載入完成!")
if __name__ == "__main__":
import sys
# 從命令列參數讀取 run_date
run_date = None
if len(sys.argv) > 1:
run_date = sys.argv[1]
main(run_date)
因為我們有新增兩個欄位,因此先執行全量更新,重刷資料
python -m src.preprocess.load_to_sqlite
輸出結果:
============================================================
將 JSON 檔案載入 SQLite(智能增量更新)
============================================================
📅 執行模式: 全量更新
將更新所有資料
找到 2 個檔案
處理檔案: Learning_PythonBasicNotes.json
✅ Database: PythonBasicNotes (已更新)
✅ Pages: 更新 8, 跳過 0
✅ Blocks: 更新 566, 跳過 0
✅ 完成:Learning_PythonBasicNotes.json
處理檔案: Life_BusanTravelPlan.json
✅ Database: BusanTravelPlan (已更新)
✅ Pages: 更新 53, 跳過 0
✅ Blocks: 更新 106, 跳過 0
✅ 完成:Life_BusanTravelPlan.json
============================================================
載入完成
============================================================
成功: 2 個檔案
失敗: 0 個檔案
【更新統計】
Databases 更新: 2
Pages 更新: 61, 跳過: 0
Blocks 更新: 672, 跳過: 0
【資料庫統計】
Databases: 2
Pages: 61
Blocks: 672
有 URL 的 Pages: 61
有 Properties 的 Pages: 61
✅ 所有檔案載入完成!
完成全量更新後,再讓我們測試一組增量更新,run_date設為2025-10-01
python -m src.preprocess.load_to_sqlite 2025-10-01
結果顯示並無2025-10-01後更新的資料,因此皆不執行更新
============================================================
將 JSON 檔案載入 SQLite(智能增量更新)
============================================================
📅 執行日期: 2025-10-01
只會更新在此日期之後建立或編輯的資料
找到 2 個檔案
處理檔案: Learning_PythonBasicNotes.json
篩選條件: run_date <= 2025-10-01
⏭️ Database: PythonBasicNotes (跳過)
✅ Pages: 更新 0, 跳過 8
✅ Blocks: 更新 0, 跳過 566
✅ 完成:Learning_PythonBasicNotes.json
處理檔案: Life_BusanTravelPlan.json
篩選條件: run_date <= 2025-10-01
⏭️ Database: BusanTravelPlan (跳過)
✅ Pages: 更新 0, 跳過 53
✅ Blocks: 更新 0, 跳過 106
✅ 完成:Life_BusanTravelPlan.json
============================================================
載入完成
============================================================
成功: 2 個檔案
失敗: 0 個檔案
【更新統計】
Databases 更新: 0
Pages 更新: 0, 跳過: 61
Blocks 更新: 0, 跳過: 672
【資料庫統計】
Databases: 2
Pages: 61
Blocks: 672
有 URL 的 Pages: 61
有 Properties 的 Pages: 61
✅ 所有檔案載入完成!
notion_pages 資料在【Day 11】把 Notion JSON 寫入 SQLite:建立可查詢的筆記資料庫 有帶到如何使用 VSCode 查詢 SQLite DB,讓我們寫一段簡易 query 確認 notion_pages 的資料
SELECT page_name, page_url, page_properties
FROM notion_pages
ORDER BY last_edited_time DESC
LIMIT 5
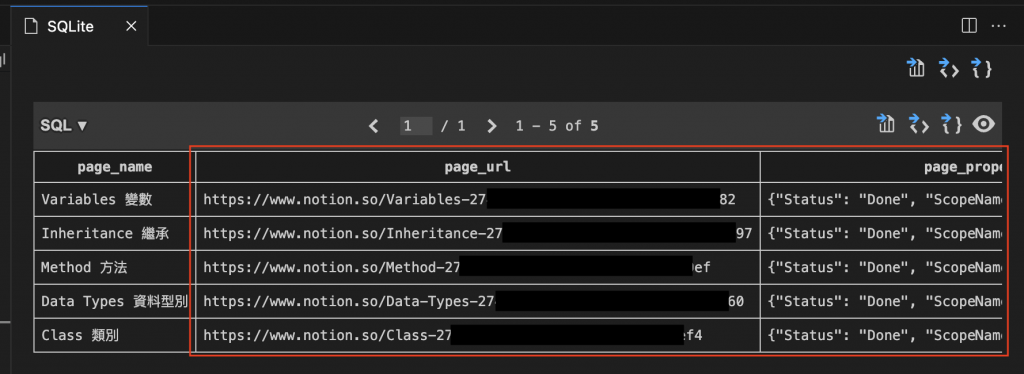
直接點擊 1筆 row 查看: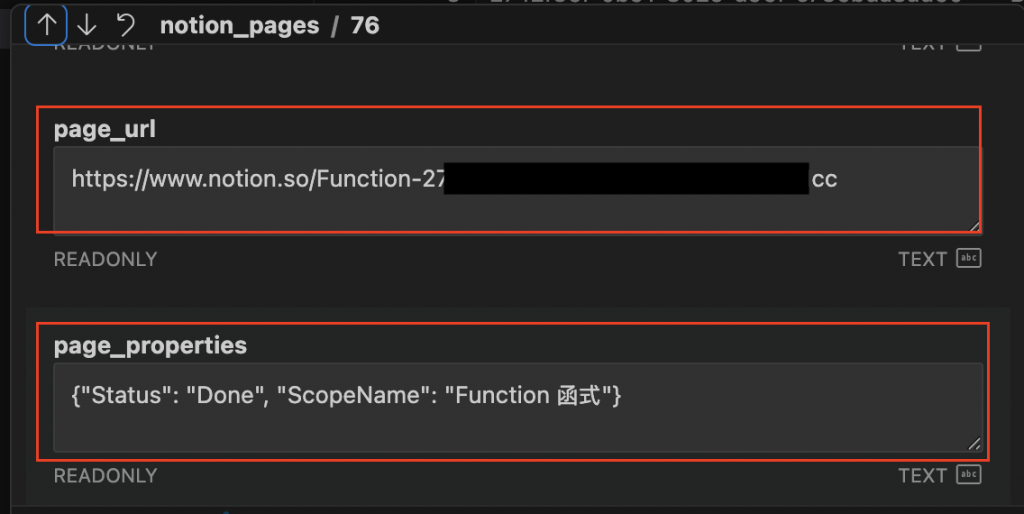
Phase 3 完成! SQLite 資料庫現在有完整的 page_url 和 page_properties 了。
src/embedding/embed_notion_chunk.py將 Notion blocks 切成 chunks,產生 embeddings,並寫入 Chroma DB
功能:
import sqlite3
import json
import os
from pathlib import Path
from typing import Dict, Any, List, Optional, Set
import chromadb
from chromadb.config import Settings
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
"""
將 Notion blocks 切成 chunks,產生 embeddings,並寫入 Chroma DB
功能:
1. 從 SQLite 撈出 blocks
2. 進行 chunking
3. 呼叫 OpenAI Embedding API
4. 寫入 Chroma DB
5. 支援增量更新機制(Delete + Insert)
6. 包含完整 metadata(database, page, block 資訊)
"""
# 設定路徑
PROJECT_ROOT = Path(__file__).parent.parent.parent
DB_PATH = PROJECT_ROOT / "data" / "notion.db"
CHROMA_PATH = PROJECT_ROOT / "data" / "chroma_db"
# 初始化 OpenAI Client
openai_client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# ============================================
# 1. 從 SQLite 撈出 blocks
# ============================================
def should_update_page(
created_time: str,
last_edited_time: str,
run_date: Optional[str]
) -> bool:
"""
判斷頁面是否需要更新
條件:run_date <= created_time OR run_date <= last_edited_time
"""
if not run_date:
return True
try:
run_dt = run_date[:10] if len(run_date) >= 10 else run_date
created_dt = created_time[:10] if created_time else ""
edited_dt = last_edited_time[:10] if last_edited_time else ""
return run_dt <= created_dt or run_dt <= edited_dt
except:
return True
def get_pages_to_update(
conn: sqlite3.Connection,
run_date: Optional[str] = None
) -> Set[str]:
"""
取得需要更新的 page_id 列表
"""
cursor = conn.cursor()
cursor.execute("""
SELECT page_id, created_time, last_edited_time
FROM notion_pages
""")
pages_to_update = set()
total_pages = 0
for page_id, created_time, last_edited_time in cursor.fetchall():
total_pages += 1
if should_update_page(created_time, last_edited_time, run_date):
pages_to_update.add(page_id)
print(f" 總頁面數: {total_pages}")
print(f" 需要更新: {len(pages_to_update)}")
return pages_to_update
def fetch_blocks_from_sqlite(
conn: sqlite3.Connection,
page_ids: Optional[Set[str]] = None
) -> List[Dict[str, Any]]:
"""
從 SQLite 撈出 blocks
Args:
conn: SQLite 連線
page_ids: 要處理的 page_id 集合(None 表示全部)
Returns:
blocks 列表
"""
cursor = conn.cursor()
if page_ids:
# 增量模式:只處理指定的頁面
placeholders = ",".join(["?"] * len(page_ids))
query = f"""
SELECT block_id, page_id, block_text, order_index
FROM notion_blocks
WHERE page_id IN ({placeholders})
AND block_text IS NOT NULL
AND block_text != ''
AND LENGTH(block_text) > 10
ORDER BY page_id, order_index
"""
cursor.execute(query, tuple(page_ids))
else:
# 全量模式:處理所有 blocks
query = """
SELECT block_id, page_id, block_text, order_index
FROM notion_blocks
WHERE block_text IS NOT NULL
AND block_text != ''
AND LENGTH(block_text) > 10
ORDER BY page_id, order_index
"""
cursor.execute(query)
blocks = cursor.fetchall()
result = []
for block_id, page_id, block_text, order_index in blocks:
result.append({
"block_id": block_id,
"page_id": page_id,
"block_text": block_text,
"order_index": order_index
})
print(f" 從 SQLite 取得 {len(result)} 個 blocks")
return result
def query_full_metadata(
conn: sqlite3.Connection,
page_id: str,
block_id: str
) -> Optional[Dict[str, Any]]:
"""
查詢完整的 metadata(跨三張表 JOIN)
包含 database, page, block 資訊
"""
cursor = conn.cursor()
cursor.execute("""
SELECT
-- Database 資訊
d.database_id,
d.database_name,
d.category,
-- Page 資訊
p.page_id,
p.page_name,
p.page_url,
p.page_properties,
p.created_time,
p.last_edited_time,
-- Block 資訊
b.block_id,
b.order_index,
b.block_text
FROM notion_blocks b
JOIN notion_pages p ON b.page_id = p.page_id
JOIN notion_databases d ON p.database_id = d.database_id
WHERE b.block_id = ? AND b.page_id = ?
""", (block_id, page_id))
row = cursor.fetchone()
if not row:
return None
try:
page_properties = json.loads(row[6]) if row[6] else {}
except:
page_properties = {}
return {
"database_id": row[0],
"database_name": row[1],
"category": row[2] or "未分類",
"page_id": row[3],
"page_name": row[4],
"page_url": row[5],
"page_properties": page_properties,
"created_time": row[7],
"last_edited_time": row[8],
"block_id": row[9],
"order_index": row[10],
"block_text": row[11]
}
# ============================================
# 2. 進行 chunking
# ============================================
def chunk_text(
text: str,
chunk_size: int = 500,
chunk_overlap: int = 50
) -> List[str]:
"""
切分文本為多個 chunks
Args:
text: 要切分的文本
chunk_size: 每個 chunk 的大小
chunk_overlap: chunk 之間的重疊大小
Returns:
chunk 列表
"""
if not text or len(text) <= chunk_size:
return [text] if text else []
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
# 如果不是最後一個 chunk,嘗試在句子邊界切分
if end < len(text):
for separator in ['。', '!', '?', '\n\n', '\n', '. ', '! ', '? ']:
last_sep = text[start:end].rfind(separator)
if last_sep != -1:
end = start + last_sep + len(separator)
break
chunk = text[start:end].strip()
if chunk:
chunks.append(chunk)
start = end - chunk_overlap
return chunks
def chunk_blocks(
blocks: List[Dict[str, Any]],
chunk_size: int = 500,
chunk_overlap: int = 50
) -> List[Dict[str, Any]]:
"""
將 blocks 切分為 chunks
Args:
blocks: block 列表
chunk_size: chunk 大小
chunk_overlap: chunk 重疊大小
Returns:
chunks 列表
"""
chunks = []
for block in blocks:
text_chunks = chunk_text(
block["block_text"],
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
for i, text in enumerate(text_chunks):
chunks.append({
"chunk_id": f"{block['block_id']}_chunk_{i}",
"block_id": block["block_id"],
"page_id": block["page_id"],
"chunk_index": i,
"text": text,
"block_text": block["block_text"] # 保留完整 block_text
})
print(f" 切分後共 {len(chunks)} 個 chunks")
return chunks
# ============================================
# 3. 呼叫 OpenAI Embedding API
# ============================================
def embed_texts(
texts: List[str],
model: str = "text-embedding-3-small"
) -> List[List[float]]:
"""
使用 OpenAI API 將文本轉換為 embeddings
Args:
texts: 文本列表
model: Embedding model 名稱
Returns:
Embeddings 列表
"""
if not texts:
return []
try:
response = openai_client.embeddings.create(
model=model,
input=texts
)
return [d.embedding for d in response.data]
except Exception as e:
print(f" ❌ Embedding API 呼叫失敗: {e}")
return [None] * len(texts)
# ============================================
# Metadata 處理
# ============================================
def extract_key_properties(
page_properties: Dict[str, Any],
max_properties: int = 10
) -> Dict[str, Any]:
"""
從 page_properties 中提取關鍵欄位
避免 metadata 過大
"""
priority_fields = [
"分類", "Category", "類別", "Type",
"難度", "Difficulty", "Level",
"標籤", "Tags", "Label",
"狀態", "Status", "State",
"優先級", "Priority",
"專案", "Project"
]
extracted = {}
# 優先提取重要欄位
for field in priority_fields:
if field in page_properties and len(extracted) < max_properties:
value = page_properties[field]
if isinstance(value, list):
extracted[field] = ", ".join(str(v) for v in value if v)
elif isinstance(value, dict):
extracted[field] = value.get("start", str(value))
elif value is not None:
extracted[field] = str(value)
# 補充其他欄位
remaining = max_properties - len(extracted)
if remaining > 0:
for key, value in page_properties.items():
if key not in extracted and len(extracted) < max_properties:
if isinstance(value, (str, int, float, bool)):
extracted[key] = str(value)
elif isinstance(value, list) and all(isinstance(v, str) for v in value):
extracted[key] = ", ".join(value)
return extracted
def build_chunk_metadata(
full_metadata: Dict[str, Any],
chunk_index: int
) -> Dict[str, Any]:
"""
為 chunk 建立完整的 metadata
包含 database, page, block 所有資訊
"""
metadata = {
# Database 資訊
"database_id": full_metadata["database_id"],
"database_name": full_metadata["database_name"],
"category": full_metadata["category"],
# Page 資訊
"page_id": full_metadata["page_id"],
"page_name": full_metadata["page_name"],
"page_url": full_metadata["page_url"],
# Block 資訊
"block_id": full_metadata["block_id"],
"block_text": full_metadata["block_text"],
"order_index": full_metadata["order_index"],
"chunk_index": chunk_index,
# 時間資訊
"created_time": full_metadata["created_time"],
"last_edited_time": full_metadata["last_edited_time"]
}
# 加入精簡的 page properties
key_properties = extract_key_properties(full_metadata["page_properties"])
metadata.update(key_properties)
return metadata
# ============================================
# 4. 寫入 Chroma DB(Delete + Insert)
# ============================================
def delete_page_chunks(
collection,
page_ids: Set[str]
) -> Dict[str, int]:
"""
Delete 階段:刪除指定頁面的所有舊 chunks
"""
if not page_ids:
return {"deleted": 0, "errors": 0}
print(f"\n【Delete 階段】刪除 {len(page_ids)} 個頁面的舊 chunks...")
stats = {"deleted": 0, "errors": 0}
for i, page_id in enumerate(page_ids, 1):
try:
results = collection.get(
where={"page_id": page_id},
include=[]
)
chunk_ids = results["ids"]
if chunk_ids:
collection.delete(ids=chunk_ids)
stats["deleted"] += len(chunk_ids)
if i % 10 == 0:
print(f" 進度: {i}/{len(page_ids)} pages, 已刪除 {stats['deleted']} chunks")
except Exception as e:
print(f" ⚠️ 刪除頁面 {page_id[:8]}... 失敗: {e}")
stats["errors"] += 1
print(f" ✅ Delete 完成: 刪除 {stats['deleted']} 個舊 chunks")
return stats
def insert_chunks_to_chroma(
collection,
sqlite_conn: sqlite3.Connection,
chunks: List[Dict[str, Any]],
embedding_model: str = "text-embedding-3-small",
batch_size: int = 100
) -> Dict[str, int]:
"""
Insert 階段:寫入新 chunks 到 ChromaDB
包含生成 embeddings 和完整 metadata
Args:
collection: ChromaDB collection
sqlite_conn: SQLite 連線
chunks: chunk 列表
embedding_model: Embedding model 名稱
batch_size: 批次大小
Returns:
統計資訊
"""
print(f"\n【Insert 階段】寫入 {len(chunks)} 個新 chunks...")
print(f" Embedding Model: {embedding_model}")
stats = {"inserted": 0, "errors": 0, "skipped": 0}
total_batches = (len(chunks) + batch_size - 1) // batch_size
for batch_num, batch_start in enumerate(range(0, len(chunks), batch_size), 1):
batch_end = min(batch_start + batch_size, len(chunks))
batch = chunks[batch_start:batch_end]
batch_ids = []
batch_documents = []
batch_metadatas = []
batch_texts = []
# 準備批次資料
for chunk in batch:
try:
# 查詢完整 metadata
full_metadata = query_full_metadata(
sqlite_conn,
chunk["page_id"],
chunk["block_id"]
)
if not full_metadata:
stats["skipped"] += 1
continue
# 建立 metadata
metadata = build_chunk_metadata(
full_metadata,
chunk["chunk_index"]
)
batch_ids.append(chunk["chunk_id"])
batch_documents.append(chunk["text"])
batch_metadatas.append(metadata)
batch_texts.append(chunk["text"])
except Exception as e:
print(f" ⚠️ 處理 chunk 失敗: {e}")
stats["errors"] += 1
# 生成 embeddings 並寫入
if batch_texts:
try:
# 呼叫 OpenAI Embedding API
print(f" 生成 embeddings (batch {batch_num}/{total_batches})...")
batch_embeddings = embed_texts(batch_texts, model=embedding_model)
# 過濾失敗的 embeddings
valid_data = [
(id, doc, meta, emb)
for id, doc, meta, emb in zip(
batch_ids, batch_documents, batch_metadatas, batch_embeddings
)
if emb is not None
]
if valid_data:
valid_ids, valid_docs, valid_metas, valid_embs = zip(*valid_data)
# 寫入 ChromaDB
collection.add(
ids=list(valid_ids),
documents=list(valid_docs),
metadatas=list(valid_metas),
embeddings=list(valid_embs)
)
stats["inserted"] += len(valid_ids)
stats["errors"] += len(batch_ids) - len(valid_ids)
print(f" 進度: {batch_num}/{total_batches} batches, "
f"已寫入 {stats['inserted']}/{len(chunks)} chunks")
except Exception as e:
print(f" ❌ 批次寫入失敗: {e}")
stats["errors"] += len(batch_ids)
print(f" ✅ Insert 完成: 寫入 {stats['inserted']} 個 chunks")
return stats
# ============================================
# 主程式
# ============================================
def main(
run_date: Optional[str] = None,
rebuild: bool = False,
chunk_size: int = 500,
chunk_overlap: int = 50,
embedding_model: str = "text-embedding-3-small"
):
"""
主程式:完整的向量化流程
流程:
1. 從 SQLite 撈出 blocks
2. 進行 chunking
3. 呼叫 OpenAI Embedding API
4. 寫入 Chroma DB(Delete + Insert)
Args:
run_date: 執行日期(None 表示全量更新)
rebuild: 是否完全重建
chunk_size: chunk 大小
chunk_overlap: chunk 重疊
embedding_model: Embedding model
"""
print("="*60)
print("Notion 筆記向量化 Pipeline")
print("="*60)
# 決定執行模式
if rebuild:
mode = "完全重建"
print(f"\n📅 執行模式: {mode}")
elif run_date:
mode = "增量更新"
print(f"\n📅 執行模式: {mode} (run_date: {run_date})")
else:
mode = "全量更新"
print(f"\n📅 執行模式: {mode}")
# 檢查 API Key
if not os.getenv("OPENAI_API_KEY"):
print("\n❌ 錯誤:找不到 OPENAI_API_KEY")
print("請在 .env 檔案中設定")
return
# 連接資料庫
print("\n【準備階段】")
print(" 連接 SQLite...")
sqlite_conn = sqlite3.connect(DB_PATH)
print(" 連接 ChromaDB...")
chroma_client = chromadb.PersistentClient(
path=str(CHROMA_PATH),
settings=Settings(anonymized_telemetry=False)
)
# 處理 collection
if rebuild:
try:
chroma_client.delete_collection("notion_notes")
print(" ✅ 已刪除舊 collection")
except:
pass
collection = chroma_client.create_collection(
name="notion_notes",
metadata={"description": "Notion 筆記向量資料庫"}
)
print(" ✅ 已建立新 collection")
pages_to_update = None
delete_stats = None
else:
collection = chroma_client.get_or_create_collection("notion_notes")
existing_count = collection.count()
print(f" ✅ 使用現有 collection({existing_count} 個文件)")
print("\n【查詢階段】")
pages_to_update = get_pages_to_update(sqlite_conn, run_date)
if not pages_to_update:
print(" ✅ 沒有頁面需要更新")
sqlite_conn.close()
return
delete_stats = delete_page_chunks(collection, pages_to_update)
try:
# 1. 從 SQLite 撈出 blocks
print("\n【Step 1: 撈出 blocks】")
blocks = fetch_blocks_from_sqlite(sqlite_conn, pages_to_update)
if not blocks:
print(" ⚠️ 沒有 blocks 可處理")
return
# 2. 進行 chunking
print("\n【Step 2: Chunking】")
chunks = chunk_blocks(blocks, chunk_size, chunk_overlap)
# 3-4. 生成 embeddings 並寫入 ChromaDB
insert_stats = insert_chunks_to_chroma(
collection,
sqlite_conn,
chunks,
embedding_model
)
# 驗證
print("\n" + "="*60)
print("【驗證結果】")
print("="*60)
final_count = collection.count()
print(f"\n📊 Collection 統計:")
print(f" 最終文件數: {final_count}")
if delete_stats:
print(f" 本次刪除: {delete_stats['deleted']}")
print(f" 本次新增: {insert_stats['inserted']}")
# 顯示樣本
if final_count > 0:
print("\n【樣本 Metadata】")
sample = collection.get(limit=1, include=["metadatas", "documents"])
key_fields = [
"database_name", "category",
"page_name", "page_url",
"block_id", "order_index"
]
metadata = sample["metadatas"][0]
print(json.dumps(
{k: v for k, v in metadata.items() if k in key_fields},
indent=2,
ensure_ascii=False
))
print("\n【樣本內容】")
print(sample["documents"][0][:150] + "...")
print("\n" + "="*60)
print("✅ 向量化完成!")
print("="*60)
except Exception as e:
print(f"\n❌ 發生錯誤: {e}")
import traceback
traceback.print_exc()
finally:
sqlite_conn.close()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(description="Notion 筆記向量化工具")
parser.add_argument(
"run_date",
nargs="?",
help="執行日期(YYYY-MM-DD),不指定則全量更新"
)
parser.add_argument(
"--rebuild",
action="store_true",
help="完全重建"
)
parser.add_argument(
"--chunk-size",
type=int,
default=500,
help="Chunk 大小(預設:500)"
)
parser.add_argument(
"--chunk-overlap",
type=int,
default=50,
help="Chunk 重疊(預設:50)"
)
parser.add_argument(
"--embedding-model",
type=str,
default="text-embedding-3-small",
help="Embedding model"
)
args = parser.parse_args()
main(
run_date=args.run_date,
rebuild=args.rebuild,
chunk_size=args.chunk_size,
chunk_overlap=args.chunk_overlap,
embedding_model=args.embedding_model
)
python -m src.embedding.embed_notion_chunks --rebuild
python -m src.embedding.embed_notion_chunks
# 使用預設 chunk 設定
python -m src.embedding.embed_notion_chunks 2024-10-01
# 自訂 chunk 大小
python -m src.embedding.embed_notion_chunks 2024-10-01 --chunk-size=300 --chunk-overlap=30
✅ 已建立新 collection
【Step 1: 撈出 blocks】
從 SQLite 取得 352 個 blocks
【Step 2: Chunking】
切分後共 352 個 chunks
【Insert 階段】寫入 352 個新 chunks...
Embedding Model: text-embedding-3-small
生成 embeddings (batch 1/4)...
進度: 1/4 batches, 已寫入 100/352 chunks
生成 embeddings (batch 2/4)...
進度: 2/4 batches, 已寫入 200/352 chunks
生成 embeddings (batch 3/4)...
進度: 3/4 batches, 已寫入 300/352 chunks
生成 embeddings (batch 4/4)...
進度: 4/4 batches, 已寫入 352/352 chunks
✅ Insert 完成: 寫入 352 個 chunks
============================================================
【驗證結果】
============================================================
📊 Collection 統計:
最終文件數: 352
本次新增: 352
【樣本 Metadata】
{
"page_url": "https://www.notion.so/14-45-ppp",
"category": "Life",
"block_id": "bbb,
"database_name": "BusanTravelPlan",
"page_name": "14:45",
"order_index": 0
}
【樣本內容】
停靠車站:全線6站。尾浦⇌登月隧道⇌青沙浦⇌青沙浦踏石觀景臺⇌九德浦⇌松亭
運行時間:全長4.8公里,單程30分鐘(速度15Km/h)
列車類型:行駛於路面鐵道,復古造型列車,全車廂皆為面海座位...
============================================================
✅ 向量化完成!
============================================================
Phase 4 完成! 現在 Chroma DB 中的每個 chunk 都有完整的 metadata 了。
今天我們透過三階段的架構重構,解決了 metadata 遺失的問題:
Phase 1: SQLite Schema 遷移
Phase 2: Notion API → JSON 邏輯更新
Phase 3: SQLite 寫入邏輯重構
Phase 4: Chroma DB 寫入改進
明天我們將繼續回到 Streamlit UI,呈現目前修改的結果!


 iThome鐵人賽
iThome鐵人賽