在 Day 26,我們成功實作了對話記憶與來源追蹤功能,但在實測時發現了幾個系統的改進空間,因此今天會針對第一大類問題做修正與優化 -- 修正 Metadata 問題:
今天我們會深入分析這些問題的根本原因,並制定完整的修正計畫。
# Streamlit UI 顯示的結果
📚 參考來源
📄 ⚠️ 未命名筆記 — 未分類
📄 ⚠️ 未命名筆記 — 未分類
📄 ⚠️ 未命名筆記 — 未分類
所有來源都顯示相同的警告訊息,這不可能是巧合。問題一定出在資料流的某個環節。
讓我們追蹤一筆筆記的 metadata 是如何在系統中流動的:
Notion API → SQLite → 文本切分 → Chroma DB → 查詢結果 → Streamlit UI
src/embedding/embed_notion_chunks.py回顧 【Day 16】從 Chunk 到向量:將 Notion 筆記寫入 Chroma DB 的程式碼,我們發現寫入 Chroma DB 時的 metadata 設定過於簡化:
# ChromaDB 架構:只有一個 collection
collection = chroma_client.get_or_create_collection("notion_notes")
chunks = fetch_and_chunk(limit=20)
texts = [c["text"] for c in chunks]
ids = [c["chunk_id"] for c in chunks]
# ❌ 問題:metadata 只有 block_id 和 page_id
metadatas = [
{
"block_id": c["block_id"],
"page_id": c["page_id"]
}
for c in chunks
]
# 寫入 ChromaDB
collection.add(
ids=ids,
documents=texts,
metadatas=metadatas, # ← 缺少 Title 和 Category
embeddings=embeddings
)
這就是問題所在!當 source_tracker.py 嘗試讀取時,因為我們只把 page_id 傳進去,卻沒有把 SQLite 裡的完整頁面資訊(page_name、category 等)一起帶過去。導致 Chroma DB 的 metadata 不完整。
到了 Streamlit UI 顯示時:
page_name = metadata.get("page_name", "未命名筆記") # ❌ 拿不到,回傳預設值
category = metadata.get("category", "未分類") # ❌ 拿不到,回傳預設值
這就是為什麼所有來源都顯示「⚠️ 未命名筆記 — 未分類」的原因。
# 建立完整的 metadata
metadata = {
"block_id": chunk["block_id"],
"page_id": chunk["page_id"],
"page_name": page_info["page_name"], # ✅ 加入標題
"category": extract_category(page_info), # ✅ 加入分類
"page_url": page_info["page_url"], # ✅ 加入連結
}
當我們想在 Streamlit UI 加入「開啟原始筆記」的按鈕時,發現根本拿不到 Notion 的頁面網址:
# Streamlit UI 的嘗試
page_url = metadata.get("page_url")
if page_url:
st.markdown(f"[🔗 開啟 Notion 原始筆記]({page_url})")
else:
st.caption("⚠️ 無法取得原始連結") # ← 總是顯示這個
回到 【Day 9】設計 SQLite Schema:把 Notion JSON 轉成結構化資料 設計的資料表結構: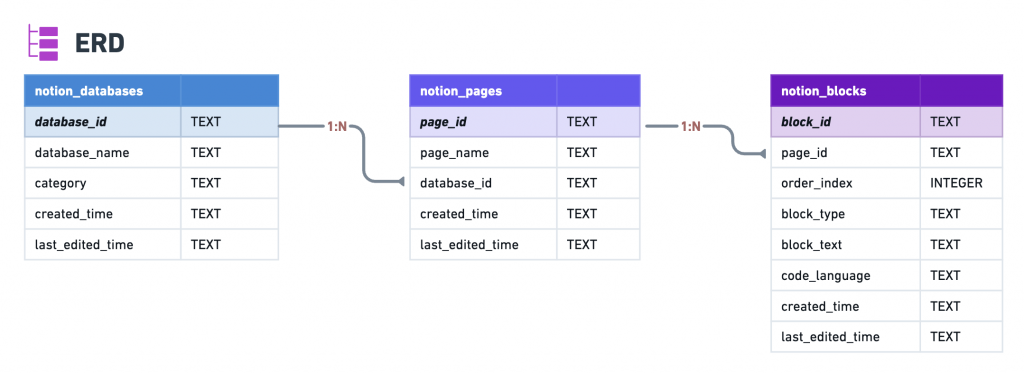
問題很明顯:我們當初設計 Schema 時,根本沒有規劃在notion_pages 儲存 URL 的欄位。既然我們的Schema 沒有 URL,在 【Day 11】把 Notion JSON 寫入 SQLite:建立可查詢的筆記資料庫 的寫入函數自然也沒有處理 URL。
每個環節都沒有設計處理 URL 的邏輯,若我們需要在 Streamlit UI 顯示 Notion 筆記URL,就必須依循資料流逐一加上。
Notion API ──✅ 有 URL──> [沒有擷取]
↓
SQLite ──────❌ 無欄位──> [沒有儲存]
↓
Chroma DB ───❌ 無資料──> [無法傳遞]
↓
Streamlit UI ❌ 無法顯示
-- 擴充後的 Schema(概念)
CREATE TABLE notion_pages (
page_id TEXT PRIMARY KEY,
page_name TEXT NOT NULL,
page_url TEXT, -- ✅ 新增:Notion 頁面連結
database_id TEXT,
created_time TEXT,
last_edited_time TEXT,
FOREIGN KEY (database_id) REFERENCES notion_databases(database_id)
);
同時需要修改:
當我們的 Notion 工作區逐漸成長,會建立各種不同用途的 Database,舉例來說:
Title、Day、行程類別...等
Title、Status
Title、Status、Category...等
當然不只這些範例,因此我們需要更具彈性的作法來收攏不同 Notion Database 的 Property。
我們目前在 notion_pages 的 Schema 設計是固定欄位,如果要為不同的 Notion Database 都加上對應的 property column 會導致:
有人可能會想:「那我為每個 Database 建一張表不就好了?」
-- 為每個 Database 建專屬的表
CREATE TABLE programming_notes (...);
CREATE TABLE project_management (...);
CREATE TABLE daily_logs (...);
但這會帶來新問題:
-- 彈性的 Schema 設計(概念)
CREATE TABLE notion_pages (
page_id TEXT PRIMARY KEY,
page_name TEXT NOT NULL,
page_url TEXT,
page_properties TEXT, -- ✅ JSON 格式儲存所有 properties
database_id TEXT,
created_time TEXT,
last_edited_time TEXT
);
目前的 Pipeline 有個隱藏問題:如果重複執行,會如何處理已存在的資料?
# 現有的寫入邏輯(Day 11)
def insert_notion_page(conn, page_id, page_name, ...):
cursor.execute("""
INSERT INTO notion_pages (page_id, page_name, ...)
VALUES (?, ?, ...)
""", (page_id, page_name, ...))
# ❌ 如果 page_id 已存在會報錯:UNIQUE constraint failed
這會導致:
採用「先刪後插」的策略,確保資料的唯一性與最新性。
# ✅ 改進後的概念
def upsert_notion_page(conn, page_data):
"""
使用 Delete + Insert 策略更新頁面
確保每次都是最新、完整的資料
"""
cursor = conn.cursor()
# Step 1: 刪除舊資料(如果存在)
cursor.execute(
"DELETE FROM notion_pages WHERE page_id = ?",
(page_data["page_id"],)
)
# Step 2: 插入新資料
cursor.execute("""
INSERT INTO notion_pages
(page_id, page_name, page_url, page_properties, ...)
VALUES (?, ?, ?, ?, ...)
""", (...))
conn.commit()
基於以上的問題分析,我們制定了完整的修正計畫:
-- 新增欄位
ALTER TABLE notion_pages ADD COLUMN page_url TEXT;
ALTER TABLE notion_pages ADD COLUMN page_properties TEXT;
-- 建立索引(提升查詢效能)
CREATE INDEX idx_page_name ON notion_pages(page_name);
CREATE INDEX idx_database_id ON notion_pages(database_id);
-- 安全性考量:
-- 1. 執行前先備份資料庫
-- 2. 驗證遷移結果
-- 3. 提供回滾機制
# 現在:只取基本資訊
page_data = {
"page_id": response["id"],
"page_name": extract_title(response),
"database_id": response["parent"]["database_id"],
}
# 改為:取得完整資訊
page_data = {
"page_id": response["id"],
"page_name": extract_title(response),
"page_url": response["url"], # ✅ 新增
"database_id": response["parent"]["database_id"],
"properties": extract_all_properties(response["properties"]), # ✅ 新增
"created_time": response["created_time"],
"last_edited_time": response["last_edited_time"]
}
# 現在:只有基本 metadata
metadata = {
"block_id": chunk["block_id"],
"page_id": chunk["page_id"]
}
# 改為:從 SQLite 查詢完整資訊
page_info = query_page_info_from_sqlite(chunk["page_id"])
metadata = {
"block_id": chunk["block_id"],
"page_id": chunk["page_id"],
"page_name": page_info["page_name"], # ✅ 新增
"page_url": page_info["page_url"], # ✅ 新增
"category": extract_category(page_info), # ✅ 新增
"database_id": page_info["database_id"],
}
# 現在:顯示預設值
page_name = metadata.get("page_name", "未命名筆記")
category = metadata.get("category", "未分類")
# 改為:顯示實際資訊 + 連結
page_name = metadata.get("page_name", "未命名筆記")
category = metadata.get("category", "未分類")
page_url = metadata.get("page_url")
with st.expander(f"📄 {page_name} — {category}"):
st.markdown(f"> {doc[:300]}...")
if page_url:
st.markdown(f"[🔗 開啟 Notion 原始筆記]({page_url})")
st.caption(f"建立時間: {metadata.get('created_time', 'N/A')[:10]}")
今天我們深入診斷了系統中的四個關鍵問題,找出了每個問題的根本原因,並制定了完整的修正計畫。這些問題環環相扣,反映出在初期設計時低估了 Notion 資料的複雜性與動態性:
notion_pages Schema 不夠彈性:固定欄位無法應對動態的 properties明天(Day 28),我將按照今天制定的計畫,逐步帶大家實作所有的修正。從 Schema 遷移開始,一路修改到 Streamlit UI,讓 metadata 在整個系統中完整流動!

