昨天 (Day 4) 我們讓 LLM 學會了逐步推理(CoT),避免它「一閃而過」直接給出錯誤答案。但還有另一種常見風險:幻覺與過時。
舉例來說,問模型:「維也納美泉宮幾點開門?」它可能:
不論哪一種,都會誤導使用者。
檢索增強生成(Retrieval-Augmented Generation, RAG) 的目標,就是在回答前,先去查找最新且可信的資料,讓模型「有憑有據」。
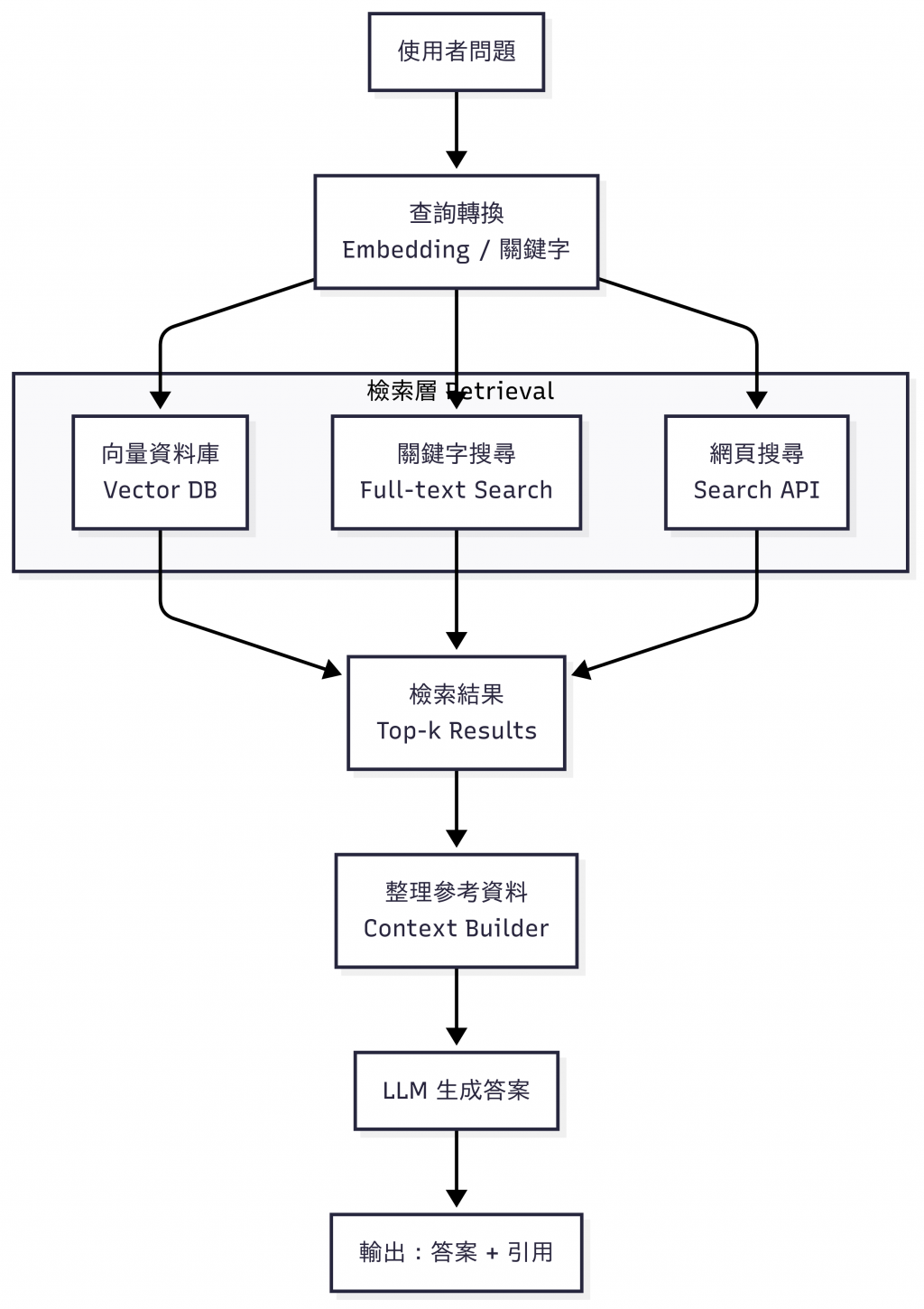
圖:RAG 基本流程。使用者問題先經過查詢轉換,透過向量資料庫、關鍵字搜尋或網頁搜尋取得候選內容,經過整理後再交給 LLM 生成答案,並附上引用。
這張圖展示了 最常見的 RAG(Retrieval-Augmented Generation)流程:
使用者問題:一開始我們丟給系統的問題,可能是「美泉宮幾點開門?」。
查詢轉換(Embedding / 關鍵字):把自然語言的問題轉換成電腦可搜尋的形式,例如語意向量(Embedding),或是抽取關鍵字。
搜尋層(Retrieval):透過三種常見方式尋找候選資料:
搜尋結果(Top-k Results):從眾多候選中選出最相關的幾筆(通常是前 k 筆)。
整理參考資料(Context Builder):將搜尋到的內容與使用者問題組合,提供給模型一個「有根據的上下文」。
LLM 生成答案:大型語言模型(如 GPT、Gemini、Claude)根據這些參考內容生成答案。
輸出(答案 + 引用來源):最終回答會包含來源,讓使用者能夠追溯並驗證資料。
整個流程就像「開書考」:LLM 不再靠記憶亂猜,而是先翻資料,再基於找到的依據作答。這正是 RAG 的核心價值——用真實資料降低幻覺,提升可信度。
Lewis, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks. (NeurIPS 2020)
→ 這篇為 RAG 的源頭研究,提出「檢索 + 生成」的架構,為後來眾多應用奠定了基礎。
簡單的判斷:
雖然大家常把 RAG 想成「丟進向量資料庫再查出來」,但實際上有不同的做法,各有適合的情境:
向量搜尋(Vector Search)
關鍵字搜尋(Keyword Search)
Web 搜尋
這樣的比較讓我們理解:
RAG 不是只有向量庫,而是可以靈活結合不同搜尋方式,依需求挑選最合適的管道。
目標:從零理解 RAG 的運作
流程:建立文件庫 → 向量化 → 搜尋 → 生成答案
安裝相依套件
pip install -U sentence-transformers faiss-cpu google-generativeai
範例程式
from sentence_transformers import SentenceTransformer
import faiss
import google.generativeai as genai
# 1. 初始化編碼模型(BGE 系列對中文檢索效果不錯)
encoder = SentenceTransformer("BAAI/bge-base-zh-v1.5")
# 2. 文件庫(示範資料)
docs = [
"美泉宮(Schönbrunn Palace)通常每天上午 9 點開門。",
"美景宮(Belvedere Palace)一般營業時間是上午 10 點。",
"聖史蒂芬大教堂(St. Stephen's Cathedral)通常上午 8 點開放。"
]
# 3. 建立向量索引
embeddings = encoder.encode(docs)
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(embeddings)
# 4. 查詢
query = "美泉宮幾點開門?"
q_emb = encoder.encode([query])
D, I = index.search(q_emb, k=1)
retrieved = docs[I[0][0]]
# 5. 呼叫 Gemini(免費額度可用)
genai.configure(api_key="你的_API_KEY")
llm = genai.GenerativeModel("gemini-2.0-flash")
prompt = f"根據以下資訊回答問題:\n\n資訊:{retrieved}\n\n問題:{query}\n請用中文簡潔回答。"
response = llm.generate_content(prompt)
print("搜尋結果:", retrieved)
print("LLM 回答:", response.text)
輸出結果
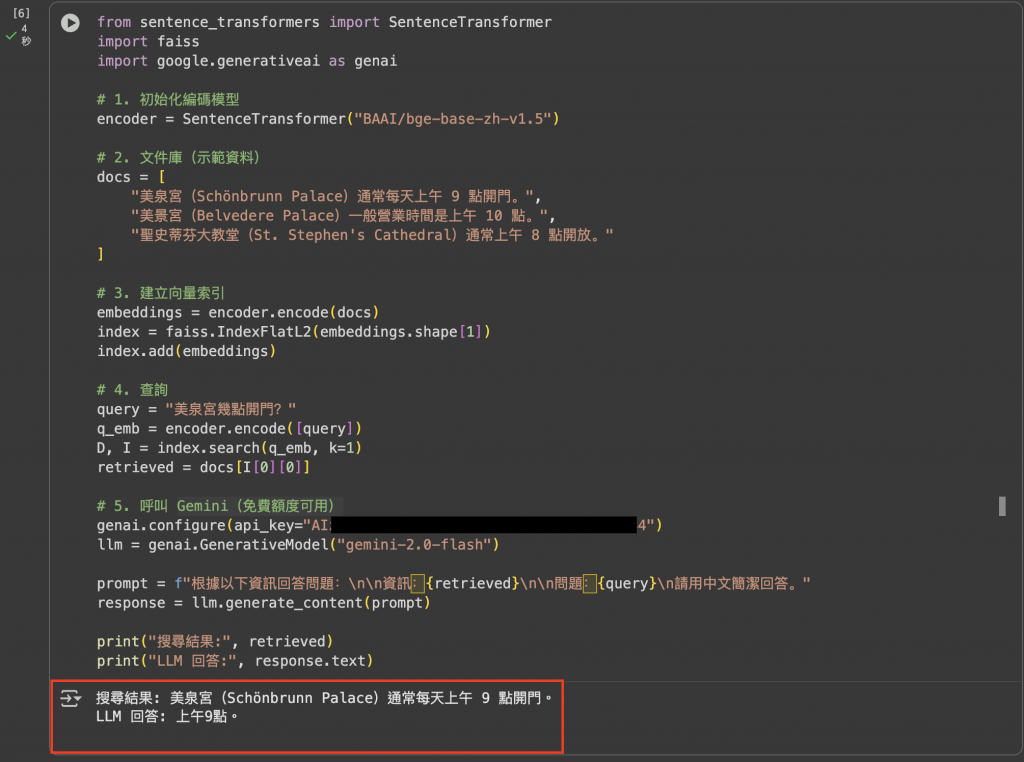
圖:Naive RAG 範例程式的實際輸出。模型先檢索到「美泉宮通常每天上午 9 點開門」的相關段落,再依據檢索結果生成答案。這樣的流程,就像讓 LLM 在「開書考」中作答:不是憑記憶或幻覺,而是依據明確依據來回應。
你剛剛完成了最簡單的 RAG:
前一個範例使用的是「本地知識庫」——先準備一批文件,再建立索引。這種方式適合固定的 FAQ、產品文件或內部資料。
但如果我們想查的是最新的資訊,例如「美泉宮今天幾點開門?」或「這週維也納的天氣如何?」光靠本地文件就不夠了。這時候就需要 Web 搜尋型的 RAG。
這裡我們示範透過 DuckDuckGo(DDG)搜尋引擎 來擴充 RAG:它支援中文查詢、不需要申請 API key,適合快速整合進入原型。
安裝套件
pip install ddgs google-generativeai
範例程式
from ddgs import DDGS
import google.generativeai as genai
# 1. 問題
query = "美泉宮 Schönbrunn Palace 幾點開門?"
# 2. 執行 DuckDuckGo 搜尋(支援中文,免 API key)
with DDGS() as ddgs:
results = [r["body"] for r in ddgs.text(query, region="tw-tzh", max_results=10)]
retrieved = "\n".join(results)
# 3. 呼叫 Gemini(免費額度可用)
genai.configure(api_key="你的_API_KEY")
llm = genai.GenerativeModel("gemini-2.5-flash")
prompt = f"根據以下網路搜尋資訊回答問題:\n\n資訊:{retrieved}\n\n問題:{query}\n請用中文簡潔回答,並在答案後標註來源。"
response = llm.generate_content(prompt)
# 4. 輸出
print("搜尋結果:", retrieved)
print("LLM 回答:", response.text)
輸出結果
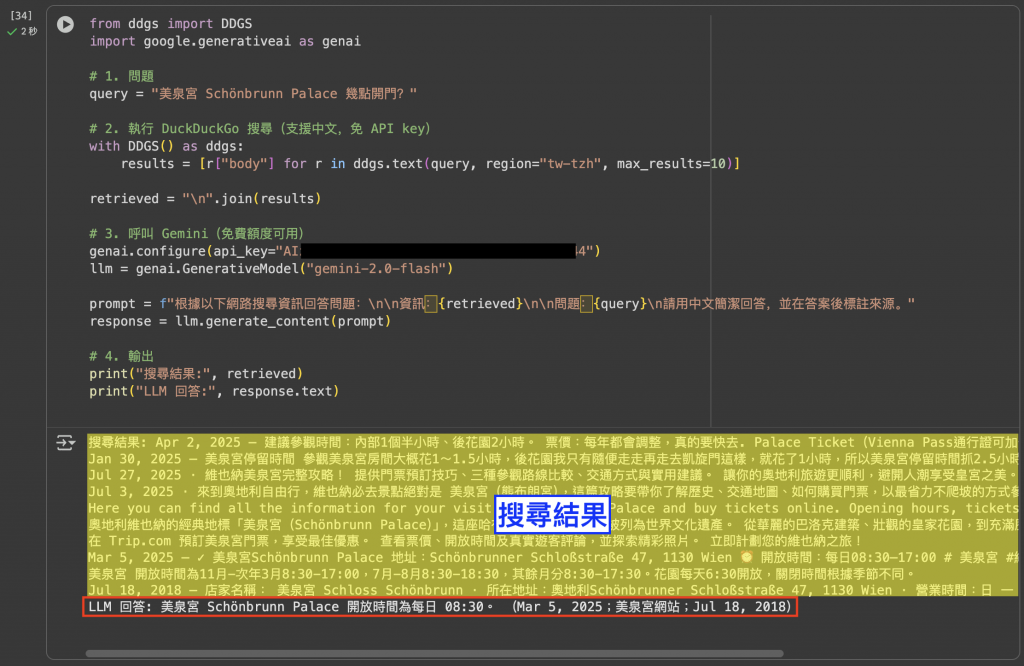
圖:Web 搜尋型 RAG 範例程式的實際輸出。這次不依賴本地文件庫,而是透過 DuckDuckGo 即時搜尋,取得美泉宮的開放時間,再交給 LLM 生成答案。這種方式適合需要「最新、公開資訊」的情境,例如查詢營業時間、新聞或官網公告。
這樣的 Web 搜尋型 RAG 和前一個 Naive RAG 剛好形成對比:
昨天的 CoT 解決「推理透明」,今天的 RAG 解決「答案可靠」。最佳組合是:
例如:
問:「美泉宮值得花一整天參觀嗎?」
- RAG 找到:宮殿 1,441 個房間、花園、動物園、迷宮…
- CoT 推理:面積大、內容多,確實值得一整天
- 結論:建議排一天行程
雖然 RAG 很有用,但它也有天生的限制。
舉個例子:
問題:「今天維也納下雨嗎?」
同樣的情況還有:
這些問題都需要直接呼叫外部工具或 API,而不是只靠搜尋。
因此,RAG 不是萬靈丹,它解決了「讓答案有依據」的問題,但要處理即時、互動、行動的需求,就必須進一步學會——使用工具。
這也將是我們接下來會探討的重點。
就像昨天讓模型「學會思考」,今天我們讓它「找到證據」。而明天,我們要讓模型真的能「動手做事」。

圖:奧地利國家圖書館(Austrian National Library, Prunksaal)。穹頂壁畫與典籍交織成無盡的知識星河,提醒我們:LLM 若不倚靠真實資料,往往在幻覺中徘徊;透過 RAG,更能在浩瀚語言的殿堂裡,找到憑據與方向。(攝影:作者自攝)


 iThome鐵人賽
iThome鐵人賽