
想像你請旅行規劃 Agent 幫你安排行程,條件是:
結果它回了一份看起來很漂亮的行程表,但當你真的把票價與餐飲加總後,發現竟然超過 500 歐。這就是典型的問題:LLM 生成的內容,常常只「看起來合理」,但實際不一定正確。
原因在於:LLM 在預設狀態下傾向「直接給答案」,卻缺乏 逐步推理(step-by-step reasoning) 的過程。就像學生在考數學時沒寫草稿,腦中「一閃而過」的答案,往往錯得離譜。
因此,想讓 LLM 成為可靠的 Agentic AI,第一步就是讓它學會「思考過程可見化」:一步一步拆解,最後再得出結論。這正是 Prompt 工程 與 Chain-of-Thought (CoT) 的價值。
回顧前面介紹的能力樹,推理是許多能力的基礎:
如果缺乏推理能力,其他能力往往就會變成「空中樓閣」。因此,讓 LLM 學會逐步思考,正是最自然的 實作起點。
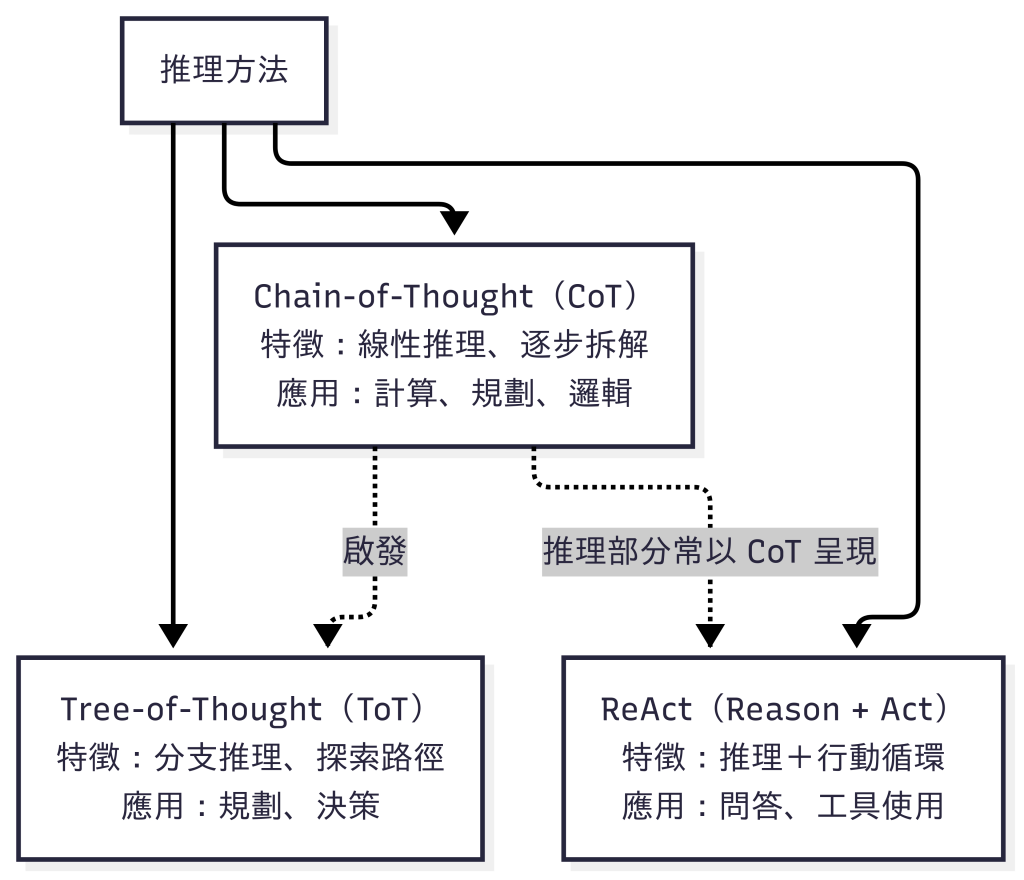
圖:三種推理方法的關係。CoT 提供逐步拆解的基礎,啟發了 ToT 的分支推理;而在 ReAct 中,推理部分也常以 CoT 形式呈現。三者並非演進關係,而是針對不同場景的互補方法。
顧名思義,就是讓模型在回答前,把思考過程一一寫出來。
「總花費是 420 歐。」
「第一天餐飲約 40 歐,門票 20 歐;第二天交通 15 歐,餐飲 35 歐,門票 25 歐;第三天餐飲 30 歐,紀念品 15 歐。合計 180 歐。」
透過逐步拆解,答案更透明,錯誤也容易被抓到。
Zero-shot CoT(最簡單範例)
只要在 Prompt 裡加上一句指示,就能引導模型展開逐步推理,例如:
這種指令能讓 LLM 先輸出「思考過程」,再收斂到最後答案,效果在計算、規劃、邏輯推理類問題特別明顯。
One-shot CoT
除了 zero-shot,你也可以用 one-shot:先給模型一個「已解好的範例」,再請它模仿同樣的格式來解新題。這樣能讓模型更快掌握「逐步拆解」的寫法。可參考以下範例 Prompt(旅行預算計算):
你將先閱讀一個範例,學習解題格式;之後請用同樣的格式解決新題。
【範例】
題目:兩天行程,交通每天 10 歐;餐飲每天 3 餐,每餐 12 歐;門票總計 18 歐。請計算總花費。
解題步驟:
1) 交通:10 × 2 = 20
2) 餐飲:3 × 12 × 2 = 72
3) 門票:18
4) 總和:20 + 72 + 18 = 110
答案:110 歐
【要解的問題】
題目:三天行程,交通每天 10 歐;餐飲每天 3 餐,每餐 15 歐;
第一天門票 20 歐;第二天門票 15 歐;第三天沒有門票。
請以「解題步驟 → 答案」的格式作答,最後只給一個總金額。
Few-shot CoT
原理和 one-shot 一樣,只是多放幾個範例,讓模型學到更一致的格式。
Wei, et al. Chain-of-thought prompting elicits reasoning in large language models. (NeurIPS 2022)
CoT 是線性的;ToT 則像在腦中「分支思考」,同時考慮多個選項,再選擇最優解。
在基礎 Prompt 裡不容易直接實現 ToT,通常需要透過額外框架(如 LangChain、程式控制迴圈)來模擬「分支展開 → 評估 → 選擇」。這部分會在後續進階應用再更完整介紹。
Yao, et al. Tree of Thoughts: Deliberate problem solving with large language models. (NeurIPS 2023)
把「推理」與「行動」結合:
單靠 Prompt 難以完整展現 ReAct,需要搭配「工具使用」機制。這裡先理解它的核心價值:推理不是終點,而是行動的前奏。 未來結合 Tool Use 後,ReAct 才能真正發揮威力。
Yao, et al. ReAct: Synergizing reasoning and acting in language models. (ICLR 2023)
就算有了 CoT,LLM 還是可能產生「幻覺」(Hallucination),也就是憑空編造或引用過時的資訊。
舉例:
問:「維也納美泉宮幾點開門?」
LLM 可能會回答:「早上 10 點」,但實際上大部分日子都是 9 點 開門。
這就是典型的幻覺:模型憑訓練記憶亂猜,或引用了過時的知識。
這時檢索增強(RAG)就能幫忙:它能從最新的官方資料或旅遊網站檢索正確答案(9 點),避免模型單靠內部知識而出錯。
但要注意,RAG 並不是萬能解法。假如問題變成:
問:「明天美泉宮幾點開門?」
而官網臨時公告「因維護延後到 10 點」,如果檢索來源只是靜態知識庫(如維基百科),仍會得到錯誤答案。這種狀況必須結合:
因此我們可以把幻覺問題分層來解決:
後續會再更完整地介紹這些解法,以及如何讓 Agent 能真正避免被幻覺誤導。
以下兩個例子我都實際使用 GPT-5 Instant 來執行。
選擇這個模型的原因是它能即時輸出,方便清楚比較「沒有 Chain-of-Thought」與「有 Chain-of-Thought」的差異。
我們會示範:
並各自比較「無 CoT」與「有 CoT」的輸出。
任務條件
Prompt A(沒有 Chain-of-Thought)
幫我估算三天維也納旅行的總預算。條件:每天交通 10 歐;每天餐飲 3 餐,每餐 15 歐;第一天美泉宮門票 20 歐;第二天美景宮門票 15 歐;第三天沒有門票。
實際輸出
「三天總花費約 235 歐。」
模型直接跳到結論,但 算錯了,而且完全沒有解釋過程。
Prompt B(啟用 Chain-of-Thought)
幫我估算三天維也納旅行的總預算。條件:每天交通 10 歐;每天餐飲 3 餐,每餐 15 歐;第一天美泉宮門票 20 歐;第二天美景宮門票 15 歐;第三天沒有門票。請逐步拆解計算過程,再給出總金額。
實際輸出
交通:10 × 3 = 30 歐
餐飲:45 × 3 = 135 歐
門票:20 + 15 + 0 = 35 歐
總計:200 歐
這次模型逐步拆解,最終得到正確答案,而且我們能驗證它的計算邏輯。
輸出對比(無 CoT vs 有 CoT)

圖:上半部(無 CoT,紅框)模型直接跳到結論,結果算錯為 235 歐 ❌;下半部(有 CoT,藍框)逐步拆解交通、餐飲、門票費用後,正確得出 200 歐 ✅。對比清楚顯示,CoT 能讓模型更透明、可靠。
任務條件
Prompt A(沒有 Chain-of-Thought)
請幫我規劃參觀美泉宮、美景宮和聖史蒂芬大教堂的一日行程,條件:早上 9 點出發,每個景點停留至少 2 小時,景點之間交通 30 分鐘,並且晚上 6 點前要結束。
實際輸出
以下是一日行程:
- 09:00 抵達美泉宮
- 09:00–11:00 參觀美泉宮
- 11:00–11:30 前往美景宮
- 11:30–13:30 參觀美景宮
- 13:30–14:00 前往聖史蒂芬大教堂
- 14:00–16:00 參觀聖史蒂芬大教堂
- 16:00–18:00 自由活動與結束行程
結論:行程在晚上 6 點前完成。
問題點
這份行程表表面上看起來符合條件,但其實隱藏了矛盾:
Prompt B(啟用 Chain-of-Thought)
請幫我規劃參觀美泉宮、美景宮和聖史蒂芬大教堂的一日行程,條件:早上 9 點出發,每個景點停留至少 2 小時,景點之間交通 30 分鐘,並且晚上 6 點前要結束。請逐步拆解,檢查時間是否足夠。
實際輸出
- 9:00 出發,9:30 抵達美泉宮 → 參觀至 11:30
- 交通 30 分鐘 → 12:00 抵達美景宮 → 參觀至 14:00
- 交通 30 分鐘 → 14:30 抵達聖史蒂芬大教堂 → 參觀至 16:30
- 結束時間 16:30,符合 18:00 前結束的條件
行程可行。
這份輸出不只給出行程表,還逐步檢查每個條件是否滿足,因此比 Prompt A 更可靠。
輸出對比(無 CoT vs 有 CoT)
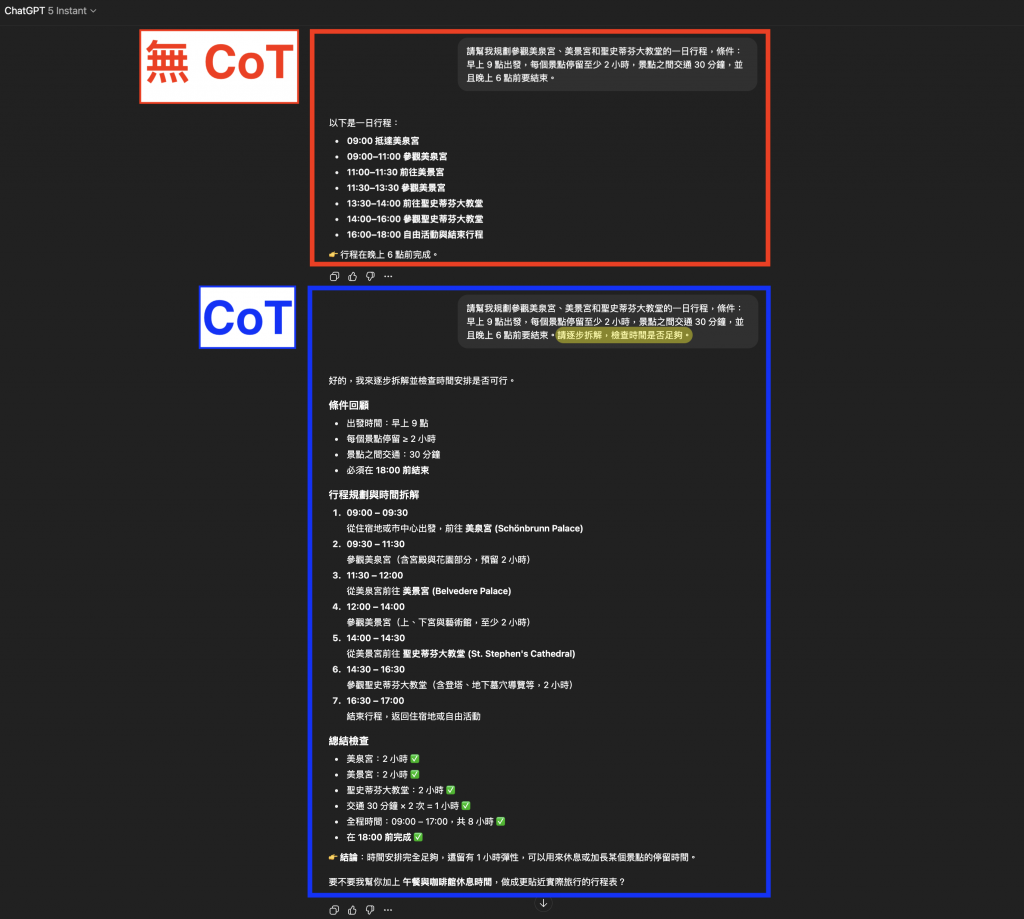
圖:上半部(無 CoT,紅框)模型直接給出行程,看似合理但隱藏矛盾,例如「09:00 抵達美泉宮」卻沒有計算出發交通時間;下半部(有 CoT,藍框)則逐步拆解並檢查停留時間與交通條件,確認行程在 18:00 前完成,輸出更可靠。
你也可以嘗試在不同的 LLM(例如 ChatGPT、Gemini、Claude、Llama)上跑一次,對比有無 CoT 的差異,通常都能觀察到顯著不同。
今天我們完成了第一步:讓 LLM 學會 逐步推理。
這也呼應了我們的進化路線:先讓 AI 想得清楚,再讓它查得到真實資訊。後續會更深入探討如何結合檢索、工具與反思,逐步打造一個更穩健的 Agent。

圖:布魯赫爾(Pieter Bruegel the Elder)《巴別塔》(The Tower of Babel),收藏於維也納藝術史博物館(Kunsthistorisches Museum)。巴別塔因語言被混亂(Confusion of Tongues),眾人無法理解彼此而最終停工;這就像 LLM 若沒有穩固的推理基礎,輸出容易陷入幻覺與誤解。唯有逐步推理與檢驗,才能確保輸出更可靠。(攝影:作者自攝)

 iThome鐵人賽
iThome鐵人賽