在深度學習的世界裡,模型就像是一台車子。
我們希望它能夠載著資料,開往「正確答案」的方向。
但如果沒有方向盤和導航,這台車就會亂開。
而對模型來說,這個「方向盤」就是 損失函數(Loss Function),
而讓車子能夠跟著導航一步步修正方向的,
就是 最佳化方法(Optimization Method)。
我們今天就會著重在介紹這兩個專業名詞上面,
來看看它代表什麼,如何使用:
用簡單一點的方式來說,損失函數就是一個數學工具,
用來量化「模型的預測」和「正確答案」之間差多少。
有點像你在考試,分數和答案的差距就是「誤差」,
而損失函數就像是打分系統,專門告訴你跟標準還差多少。
專業一點來說, Loss Function 就是用來衡量模型預測結果與
實際目標值(真實值)之間的差異或誤差。
它將模型的預測結果與真實值之間的差異轉換成一個數值,
表示模型預測的「糟糕程度」。
數值越「大」,表示預測誤差越「大」;
數值越「小」,表示預測越接近真實值。
以下我們來介紹一些比較常見的損失函數:
以回歸問題來說,也就是模型要預測連續數值時,
最常見的做法是使用「均方誤差」,
它的計算方式是把「預測值和真實值的差距平方後取平均」。
那為什麼要平方呢?
因為平方大家也知道就會變成正數,
如此就可以避免正負誤差互相抵消,也能強調大的誤差。
它的公式如下圖: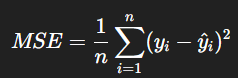
這個方法和上面均方誤差的差別很簡單,
它是直接取「差距的絕對值」後平均,
這樣會讓模型對極端誤差的敏感度稍微降低,
對於偏差錯誤的極端比較寬容一些。
它的公式如下圖: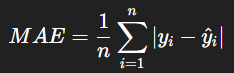
而如果我們要換到處理「分類問題」時,
例如像是模型要判斷圖片裡是貓還是狗,常見的做法則是使用「交叉熵損失」。
交叉熵損失的直覺想法是:
如果模型對正確答案給予高機率,就會得到較「低的損失」;
反之,如果模型把高機率分配給錯誤答案,損失就會變大。
它的公式如下: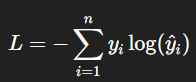
前面介紹完損失函數跟常見的使用方式,
接著我們來介紹第二個「方向盤」- 最佳化(Optimization)。
最佳化方法,簡單來說,就是一套用來「調整模型參數」的演算法。
因為我們已經有了損失函數,知道了模型目前的表現差距,
接下來就需要有一個方法來逐步改進。
最佳化方法的角色,
就是依照損失函數的指引,一次一次修正參數,讓損失慢慢下降。
以下我們也簡單介紹一些常見的最佳化方式來跟大家分享:
隨機梯度下降的做法是將資料集切成一小批一小批,
每次更新時只用一批資料來計算梯度,這樣雖然有些隨機性,
但可以讓訓練變得更快,不需要等到整份資料都算完才進行一次更新。
這種方法就像邊執行邊修正,不需要等到流程運行完才檢討錯誤。
研究者在後來發現單純的 SGD 容易在更新時來回震盪,
就好像你下山時一直左右搖擺,走得不穩定。
於是就出現了 Momentum 方法,它在梯度更新中引入「慣性」的概念。
這表示如果前幾步一直往某個方向走,後續就會帶著一點速度繼續往那個方向,
而不是每次都完全重新計算。這樣可以減少震盪,讓模型的學習更平滑。
最後,最廣為使用的就是 Adam(Adaptive Moment Estimation)。
它同時結合了 Momentum 的想法,以及對學習率(也就是每一步更新幅度)的自動調整。
這讓 Adam 在多數情境下能快速收斂,也不需要研究者手動花很多時間調整參數。
比較三種類型來說,它是一個比較「聰明」的最佳化方法,
能在多數任務中表現穩定,因此成為目前深度學習領域的常見選擇。
今天我們從兩個關鍵角度理解了模型學習的基礎:
損失函數:量化錯誤,提供學習方向。
最佳化:透過數學方法一步步修正模型,讓誤差下降。
這也是我們學習關於模型訓練很重要的一步。

