在過去幾天,我們學會了什麼是神經元,以及激活函數的角色。
而在今天,
我們要來揭開一個神經網路
真正「動起來」的過程:前向傳播(Forward Propagation)。
這個流程就像是神經網路的心臟,
把資料一步步丟進去,最後得到我們要的結果。
今天我們就來詳細的剖析它吧!
在類神經網路的學習過程裡,前向傳播是一個核心的概念。
它的基本想法其實很直觀:
當我們把一筆輸入資料丟進網路裡,它會一層一層地被處理,
最後產生一個輸出。這個過程,就像資料在一條流水線上逐站加工,
每經過一層神經元,數值都會被加權、加總,
再通過一個非線性的函數轉換,接著再傳遞到下一層。
舉個例子來說,如果要建立一個影像辨識模型,
輸入可能是一張圖片,圖片的像素值會進到第一層神經元;
在經過計算後,這些數值會被轉換成更抽象的特徵(例如邊緣或顏色模式);
再經過幾層處理後,網路就能在最後的輸出層判斷這張圖片可能是一隻貓或一隻狗。
這個過程不僅在「訓練」的時候發生,在推論的時候更是核心。
有人會這樣描述:前向傳播就是當類神經網路已經訓練完成後,
我們將新的輸入丟進去,網路依照之前學到的權重和規則,幫我們計算出對應的輸出。
換句話說,在訓練過程中,前向傳播會計算出一個「暫時的輸出」,
讓我們拿去跟正確答案比較,進一步調整網路的參數;
而在訓練完成之後,前向傳播就轉換成一種「實際應用」:
我們只要把新的資料丟進去,它就能憑藉過去學到的知識,做出預測或分類。
如果我們用「生活化的比喻」,前向傳播就像是咖啡機的運作流程:
你把咖啡豆(輸入資料)放進去,經過磨豆、萃取(中間層的運算),
最後得到一杯咖啡(輸出結果)。
在咖啡機剛研發時,設計師會不斷試驗、
調整機器內部的數值設定(就像訓練網路的過程);
等到調整完成後,你就可以直接放入新的咖啡豆,
它就能自動幫你泡出一杯品質穩定的咖啡(就像已訓練好的模型用來推論)。
前面大概介紹完了前向傳播的概念,
接著我們來看看它的詳細步驟為何:
假設我們要辨識一張 28x28 的手寫數字圖片(總共 784 個像素點)。
每一個像素點都有一個數值(0 = 黑色,255 = 白色,中間值代表灰色)。
這些數字會「展平成一條長向量」,丟進輸入層。
也就是在程式裡,你可以想像 x = [0.0, 0.5, 1.0, ...],
而這就是一張圖片的數字形式。
接下來,輸入的每一個數字都會乘上一個「權重」(weight)。
它的數學公式是這樣:
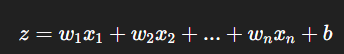
用白話一點的比喻來說:
這就像一份考卷,每題的分數不同(權重),
做對或做錯的分數會被加總起來,最後還可能有加分題(偏置)。
當我們得到加總後的數字,它還不能直接送到下一層,
因為這樣模型只會是一堆直線相加,太單調了。
因此我們要把它放進前面講過的「激活函數」中 (要講啟動函數也可以,不要挑語病)
例如:
ReLU:小於 0 的數字全部歸零,剩下的數字保持不變。
Sigmoid:把數字壓縮到 0 和 1 之間,適合做「是/否」判斷。
Softmax:把結果轉成機率,總和 = 1。(這些前面都介紹過了)
每一層神經元都會重複「加權 → 相加 → 激活(啟動)」這三個動作,
最後再把結果送到下一層。
最後,資料來到輸出層。
如果我們是要分辨「這張圖是 0–9 哪個數字」,輸出層通常會有 10 個神經元。
這時候會用 Softmax 函數,把最後的數字轉換成機率分布。
例如:
[0.05,0.01,0.88,0.02,0.04]
這就表示模型覺得 「88% 的可能性是 2」 。
如果最後要用一句話對前向傳播做總結,那我會覺得是:
-前向傳播就是資料在神經網路裡旅行的過程,
經過每一層加工,最後變成我們想要的答案。

