
接下來我們這篇文章的重點就是 :
省錢 !
錢錢真的很重要,尤其當主管後每一件事情都要算錢錢,然後再 AI 的世界中省錢的重點就在於 :
節省 Token
至於 Token 是什麼,我自已是覺得的到了 2025 年時,應該已經不太需要說了……
首先 prompt cache 這個東西不敢保證每個 model 都有支援,但應該我們常用的是都有而且每個機制都有些不同,我這裡列出比較常用的 OpenAI 來看 :
🤔 省錢的機制 + 省多少 ?
它的省錢機制主要在於 :
Input 的 token 中,如果有部份是已經 cached 的 token,則會比正常價格更便宜。
https://platform.openai.com/docs/models/gpt-5
例如以 gpt-5 上面這個網站上來看,input 正常是 1.25$,然後右邊有寫 cache 的是 $0.125,所以是指 cache 的 token 只收 0.125$ 而不是 1.25$ 。
以 GPT-5 為例,Input 的花費最多可以省 90% 左右,如果 cache 都有命中。
🤔 要如何觸發呢 ? 條件如下,基本上每個都要中
條件有點多,但也不是說不好中。
🤔 程式碼實測
import OpenAI from "openai";
const client = new OpenAI();
// 一個固定的 system 指令(長度夠大才能觸發快取)
const longSystemPrompt = `
You are an expert math tutor.
Your job is to help students understand complex mathematical concepts
with clear explanations and step-by-step examples.
Always explain your reasoning thoroughly.
(This section is intentionally long to exceed 1024 tokens when combined.)
Repeat some filler text to simulate length.
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
Lorem ipsum dolor sit amet, consectetur adipiscing elit.
`.repeat(20); // 重複 20 次,保證超過 1024 tokens
async function run() {
// 第一次請求 (Cache Miss, 會建立快取)
const first = await client.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: longSystemPrompt },
{ role: "user", content: "解釋畢氏定理" }
],
// 啟用 prompt caching(Beta 功能)
store: true
});
console.log("第一次請求 usage:", first.usage);
// 等待一下確保快取生效
await new Promise(resolve => setTimeout(resolve, 1000));
// 第二次請求 (Cache Hit, 前綴相同,只換 user 問題)
const second = await client.chat.completions.create({
model: "gpt-4o-mini",
messages: [
{ role: "system", content: longSystemPrompt }, // 前綴完全一樣
{ role: "user", content: "解釋牛頓第一運動定律" }
],
store: true
});
console.log("第二次請求 usage:", second.usage);
}
run();
這個是有觸發的情況,可以看到第二次有 cached_tokens 為 2176。
第一次請求 cached_tokens: {
input_tokens: 2319,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 1311,
output_tokens_details: { reasoning_tokens: 320 },
total_tokens: 3630
}
第二次請求 cached_tokens: {
input_tokens: 2322,
input_tokens_details: { cached_tokens: 2176 },
output_tokens: 1158,
output_tokens_details: { reasoning_tokens: 384 },
total_tokens: 3480
}
然後這是沒有觸發的情況,你看 cached_tokens 就為 0。
第一次請求 cached_tokens: {
input_tokens: 134,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 2142,
output_tokens_details: { reasoning_tokens: 704 },
total_tokens: 2276
}
第二次請求 cached_tokens: {
input_tokens: 137,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 1092,
output_tokens_details: { reasoning_tokens: 320 },
total_tokens: 1229
}
在剛剛上面測試的結果中,有沒有注意到 reasoning_tokens ? 我將上面的結果拉下來一個看,你看 reasoning_tokens 它會算在 output token 的 $$ 喔。
{
input_tokens: 137,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 1092,
output_tokens_details: { reasoning_tokens: 320 },
total_tokens: 1229
}
所以這裡的策略就是 :
不要讓它想太多 !
https://platform.openai.com/docs/guides/reasoning-best-practices
這裡我自已想了一下,有以下幾個手法:
🤔 在不需要動腦的情況下,強制降低智商
OpenAI 的 Model 事實上有一個參數可以用,如下範例程式碼中的reasoning,你設定後會強制降低它的思考。
import OpenAI from "openai";
const client = new OpenAI();
const response = await client.responses.create({
model: "gpt-5-mini",
reasoning: { effort: "high" },
input: "我是馬克大人,你好",
});
console.log(response);
以下範例分別是high與low的差別,你看同一個問題 reasoning_tokens 差了多少。
// high high high
usage: {
input_tokens: 13,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 420,
output_tokens_details: { reasoning_tokens: 384 },
total_tokens: 433
},
// low low low low
usage: {
input_tokens: 13,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 95,
output_tokens_details: { reasoning_tokens: 64 },
total_tokens: 108
},
🤔 透過 Prompt Techniques 來讓他腦袋變的很思考很簡單
這個手法的概念就像是有個老師引導你,不要讓你在碰到問題時,想東想西,然後最後結果還是很爛,還花了很多錢 ( 我指 reasoning token )。
例如我們下面用上一章學到的 few-shot 和沒有用的比較。雖然我自已沒有做很嚴格的驗證,但我自已試了大約 10 次以上,然後不同問題,結構一樣,然後結果都是用了 few-shot 的 reasoning token 較低 ( goodInput 的那個結果就是用 few-shot ) 。
import OpenAI from "openai";
const client = new OpenAI();
const goodInput = `## Instructions (明確指令)
- 學習以下的範例
- 然後回答實際的問題: "人工智慧在醫療領域的最新應用這個是屬於那個類別"
## Example
標題:央行宣布調整利率政策
類別:財經
標題:新型疫苗研發取得重大突破
類別:健康
標題:NBA總冠軍賽精彩對決
類別:體育`
const badInput = '請回答以下問題: "人工智慧在醫療領域的最新應用這個是屬於那個類別,請回答 2 個字的"'
const response = await client.responses.create({
model: "gpt-5-mini",
reasoning: { effort: "low" },
input: badInput,
});
console.log(response);
// goodInput
usage: {
input_tokens: 114,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 74,
output_tokens_details: { reasoning_tokens: 64 },
total_tokens: 188
},
// badInput
usage: {
input_tokens: 42,
input_tokens_details: { cached_tokens: 0 },
output_tokens: 200,
output_tokens_details: { reasoning_tokens: 192 },
total_tokens: 242
},
這個應該很好理解,每個模型有不同的價格,也有不同的使用時機。
對了但是還有一種情況,那就是我們在和 AI 溝通時,事實上在不同的情境溝通,我們可能就會需要不同的 model,例如如果你只是簡單的翻譯,那是不是直接用最便宜的模型就好,但如果你是要深度推理的問題,那這時就會需要很強的模型。
所以這裡會用這種策略來打 :
先說第一個簡單的說就是一開始的問題會先進入到小模型,然後當小模型產生出來的結果信心度不足(你就叫他多回傳個信心度,最簡單的信心度做法,但這個是最簡單的),然後接下來我們就可以根據信心度,來判斷是否要在呼叫一次大模型。
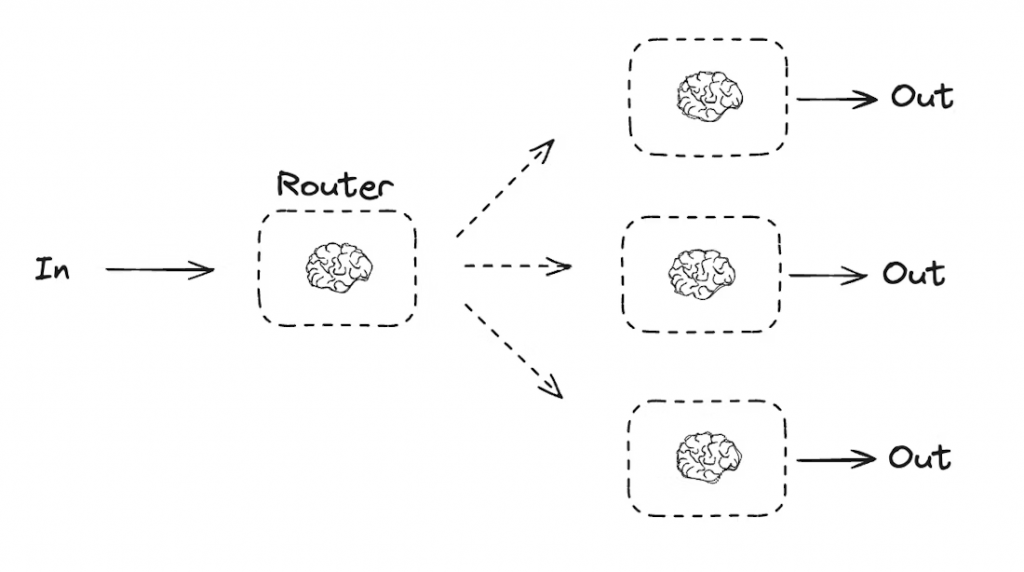
第二種實作上就有點像 LangGraph 提出的這個的這個流程,會在 RouteAI 那來判斷要叫誰做,當然 RouteAI 就是先用最便宜的。
以下為 LangGraph 的範例程式碼。
function routeDecision(state: typeof StateAnnotation.State) {
// Return the node name you want to visit next
if (state.decision === "story") {
return "llmCall1";
} else if (state.decision === "joke") {
return "llmCall2";
} else if (state.decision === "poem") {
return "llmCall3";
}
}
// Build workflow
const routerWorkflow = new StateGraph(StateAnnotation)
.addNode("llmCall1", llmCall1)
.addNode("llmCall2", llmCall2)
.addNode("llmCall3", llmCall3)
.addNode("llmCallRouter", llmCallRouter)
.addEdge("__start__", "llmCallRouter")
.addConditionalEdges(
"llmCallRouter",
routeDecision,
["llmCall1", "llmCall2", "llmCall3"],
)
.addEdge("llmCall1", "__end__")
.addEdge("llmCall2", "__end__")
.addEdge("llmCall3", "__end__")
.compile();
// Invoke
const state = await routerWorkflow.invoke({
input: "Write me a joke about cats"
});
console.log(state.output);
就 OpenAI 事實上有提到所謂的 Batch API,然後啊他可
https://platform.openai.com/docs/guides/batch

重點是『 輸入 』與『 輸出 』都可以省 50%。
但他的缺點就是非即時,所以這個功能大部份的情況都是在非即時聊天的功能用到,像是如果我們 RAG 要用的 embeddings 啊,或是預期產生每堂課程的學習摘要之類的都很適合。
但他好像不能和上面的策略 1 一起用。
OpenAI 好像大約在 2025.04 左右有出了一個叫 Flex processing 還在 Beta 中,簡單的說就是可以同時有 Batch 的價格,還可以使用 Cache 的價格優惠,但問題就是有以下的缺點 :
所以我自已想了一下,如果模型 OK,他應該是可以替代一部份的 Batch 的工作,例如一些前處理相關的東西,然後下面是我請 AI 產生適合的地方,我自已覺得都算合理,可以參考看看
然後使用的方法很簡單,就是多個 flex 就好。
import OpenAI from "openai";
const client = new OpenAI({
timeout: 15 * 1000 * 60, // Increase default timeout to 15 minutes
});
const response = await client.responses.create({
model: "o3",
instructions: "List and describe all the metaphors used in this book.",
input: "<very long text of book here>",
service_tier: "flex",
}, { timeout: 15 * 1000 * 60 });
console.log(response.output_text);
就是不要讓他廢話太話,限制他的格式與大小
這個真的要限制,不讓真的 output 會噴很多錢錢。
在這一篇文章我們有提到記憶的功能,就是我們會在 AI Application 管理整個對話的上下文,然後再每一次給 Prompt 時,再加入到它的裡面,這樣就可以讓 LLM 知道我們整個對話的脈絡,你就可以問他說,我剛剛供啥小之類的。
如果只記短時間當然沒問題,但如果時間很長那就真的會讓你的 Token 噴到和飛的一樣。
所以只要你有做記憶上下文功能,就一定要考慮選擇那些上下文 ( 例如前 N 筆之類 ? )
反正就是要處理就對了,手法就看你的情境了。
這篇文章中,咱們研究了幾個省錢大作戰的策略,然後上面沒寫但我這裡標注一下那些是其它 model 也通用的 :
所以事實上這篇文章要說事實上應該也適合大部份的模型 ~

 iThome鐵人賽
iThome鐵人賽