昨天 (Day 7) 我們介紹了 Planning Pattern:AI 會先生成一份完整的計劃,再依序執行。
這種模式雖然條理清楚,但有一個限制:計劃在一開始就固定,無法靈活應變。
例如景點臨時休館,AI 只能刪掉該步驟,而無法動態調整或找替代方案。
昨天的 Planning 屬於「先想完再做」;而今天要介紹的 ReAct,則是「邊做邊想」。這樣的對比,正好補足 Planning 缺乏的彈性。
這就是今天的主角 ReAct Pattern:Reason + Act。
ReAct 的精神是 邊推理 (Reason),邊行動 (Act)。
它不像 Planning Pattern 那樣一次性產出完整的靜態計劃(Planning),ReAct 會在每一步驟中交替進行「思考」與「行動」,直到找到最終答案。
這個循環通常被簡稱為 TAO 流程:
Thought(思考)
Action(行動)
Observation(觀察)
Final Answer(最終答案)
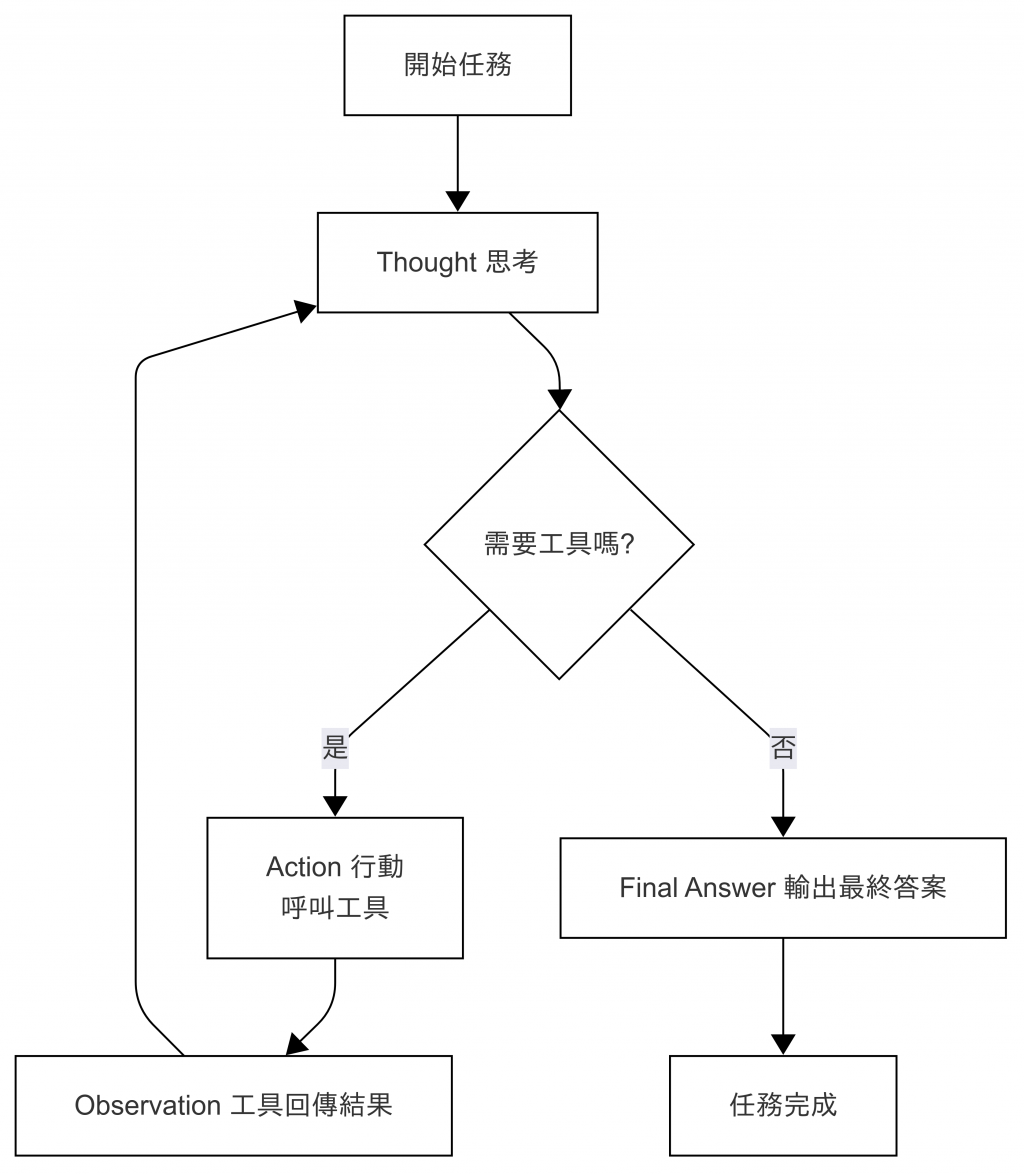
圖:ReAct Pattern 流程圖。AI 交替進行「推理」與「行動」,直到得到最終答案。
Yao, et al. ReAct: Synergizing reasoning and acting in language models. (ICLR 2023)
這篇是 ReAct 模式的原始論文,重點概念就是將 推理 (Reasoning) 與 行動 (Acting) 融合在同一流程中,透過交替的 Thought → Action → Observation 循環,讓語言模型能夠一邊思考、一邊互動,最終得到更靈活與可靠的解答。
我們延續昨天的例子:規劃一日三景點(美泉宮、美景宮、聖史蒂芬大教堂)。
不同的是,這次 AI 不會一次性輸出完整行程,而是透過 ReAct 過程逐步完成。
import google.generativeai as genai
import json
import re
from datetime import datetime, timedelta
# ---- 初始化 LLM ----
genai.configure(api_key="你的_API_KEY")
llm = genai.GenerativeModel("gemini-2.5-flash")
# ---- 模擬工具 ----
def get_weather(city: str):
return "今天維也納是下雨天" # 假設今天下雨
def check_open(place: str):
closed_places = ["美景宮"] # 假設美景宮休館
return f"{place} 正常開放" if place not in closed_places else f"{place} 今日休館"
# ---- 工具路由表 ----
TOOLS = {
"查天氣": get_weather,
"查詢開放狀態": check_open,
}
# ---- ReAct 循環 ----
def react_loop():
prompt = """你是一個旅行規劃助理,使用 ReAct 模式回答問題,思考請用繁體中文。
格式必須包含以下幾種:
Thought: 你的推理
Action: 你要執行的工具(格式:查天氣(city) 或 查詢開放狀態(place))
Observation: 工具回傳的結果
Final Answer: 請用 JSON 格式輸出最終行程,例如:
[
{"place": "美泉宮", "minutes": 120},
{"place": "聖史蒂芬大教堂", "minutes": 120}
]
現在任務:幫我規劃今天去美泉宮、美景宮、聖史蒂芬大教堂的一日行程。"""
for step in range(8): # 最多 8 回合
response = llm.generate_content(prompt).text
print(response)
# ---- 如果是最終答案 ----
if "Final Answer" in response:
try:
json_str = response.split("Final Answer:")[-1].strip()
if json_str.startswith("```"):
json_str = json_str.split("```")[1]
json_str = json_str.replace("json", "", 1).strip()
plan = json.loads(json_str)
print("\n最終解析後的行程:", plan)
return plan
except Exception as e:
print("\nJSON 解析失敗:", e)
return []
# ---- 嘗試解析 Action ----
match = re.search(r"Action:\s*([^\(]+)\((.+)\)", response)
if match:
action, arg = match.groups()
action = action.strip()
arg = arg.strip()
if action in TOOLS:
print(f"\n>> 執行工具:{action}({arg})")
obs = TOOLS[action](arg)
print(f">> 工具回傳:{obs}\n")
prompt += f"\nObservation: {obs}"
else:
print(f"\n>> 無效的工具動作:{action}")
prompt += "\nObservation: 無效的動作"
else:
print("\n>> 無法解析動作")
prompt += "\nObservation: 無法解析動作"
# ---- 執行行程模擬 ----
def simulate_schedule(plan, weather="rain"):
print("\n=== 行程時間模擬 ===")
time = datetime.strptime("09:00", "%H:%M")
end = datetime.strptime("18:00", "%H:%M")
for i, task in enumerate(plan):
duration = task["minutes"]
finish = time + timedelta(minutes=duration)
print(f"{time.strftime('%H:%M')}–{finish.strftime('%H:%M')} 參觀 {task['place']}")
time = finish
if i < len(plan) - 1: # 景點之間交通
travel_time = int(30 * (1.5 if weather == "rain" else 1))
finish = time + timedelta(minutes=travel_time)
if weather == "rain":
print(f"{time.strftime('%H:%M')}–{finish.strftime('%H:%M')} 前往下一景點(因下雨延誤)")
else:
print(f"{time.strftime('%H:%M')}–{finish.strftime('%H:%M')} 前往下一景點")
time = finish
print("行程可行!" if time <= end else "行程超時!")
# ---- 主程式 ----
if __name__ == "__main__":
plan = react_loop()
if plan:
simulate_schedule(plan, weather="rain")
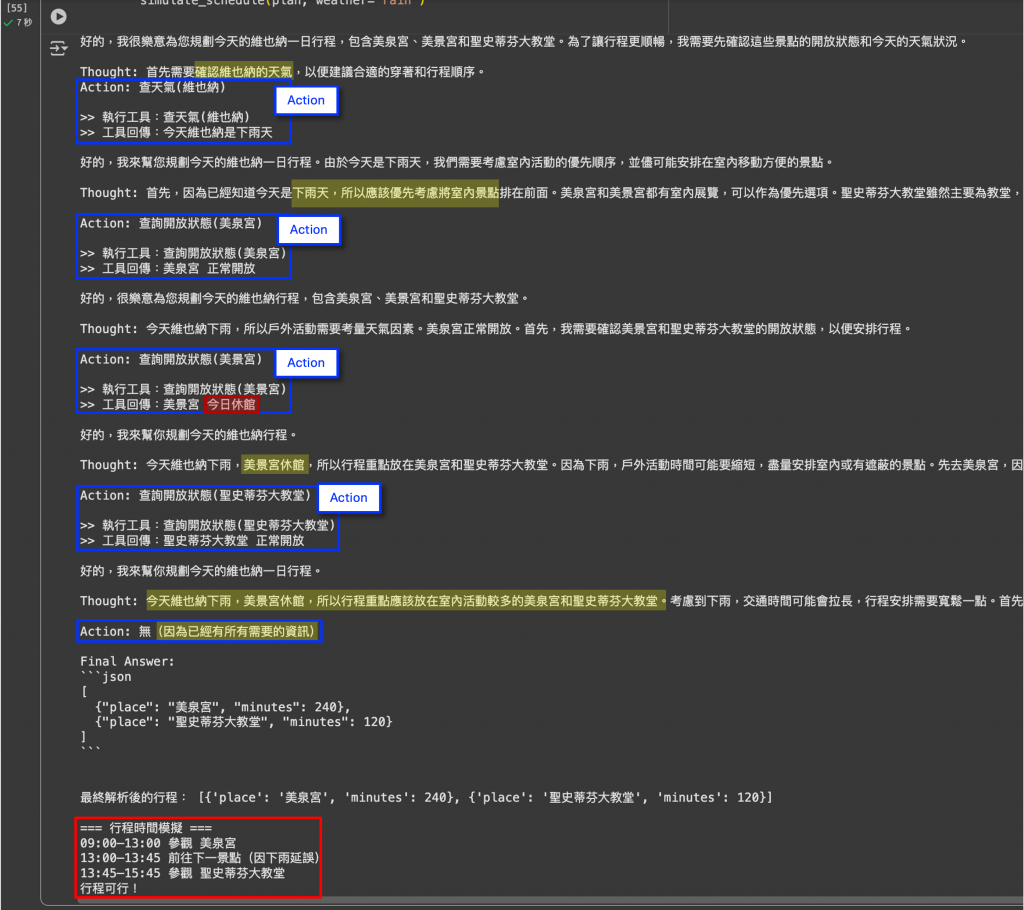
圖:ReAct Demo 實際輸出結果。AI 先逐步推理 (Thought),再選擇行動 (Action) 呼叫工具,取得觀察結果 (Observation),並根據外部資訊不斷修正計劃。最後產生 Final Answer(JSON 格式的行程),並進一步模擬完整時間表。
Thought → Action → Observation 循環
動態應變
最終輸出
執行結果清楚展現 ReAct 與 Planning 的差異:
Planning 是先給定靜態藍圖,遇到變數只能刪掉步驟;而 ReAct 則能邊查邊想,讓行程動態調整。
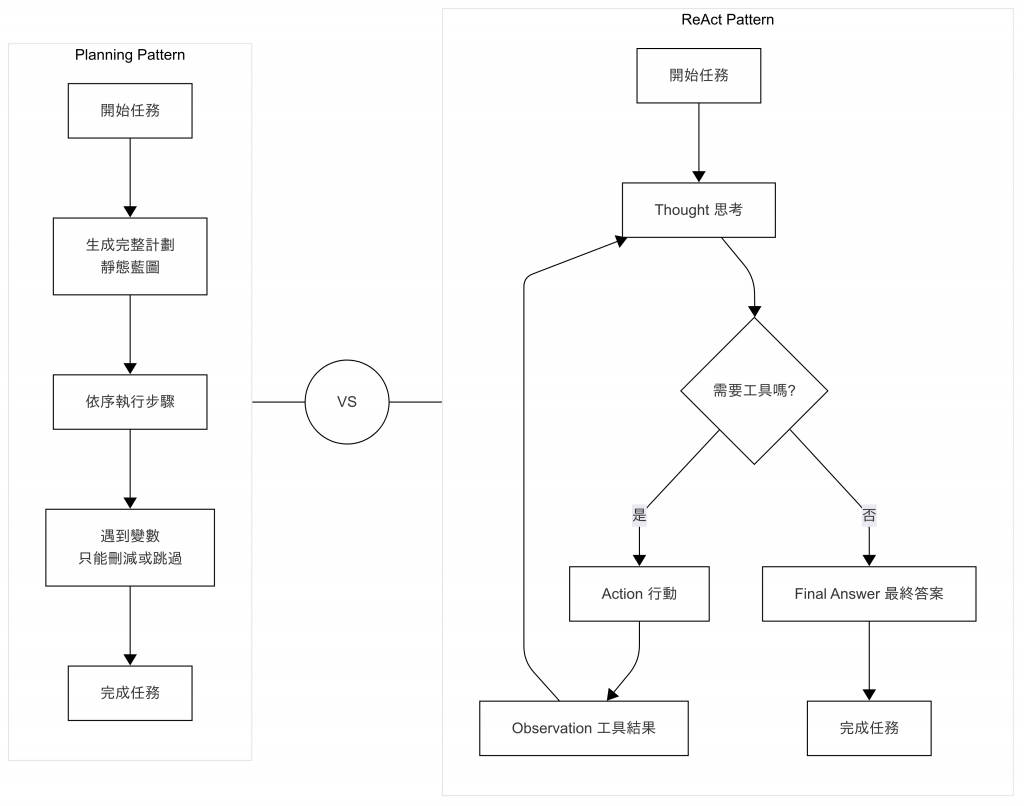
圖:Planning 與 ReAct 的對比。前者靜態、清晰;後者動態、靈活。
接著我們會進一步探討 Reflection(反思),讓 AI 不只是當下靈活應變,還能記取經驗、避免重蹈覆轍。
如果 ReAct 是讓 AI 能在當下隨情境調整,那麼下一步的 Reflection,則是讓 AI 從過去學會改進。

圖:維也納國立歌劇院(Wiener Staatsoper)。巴洛克華麗的階梯與穹頂燈光,是電影《不可能的任務:失控國度》著名的歌劇院段落中,阿湯哥與女主角在此相會並臨機應變尋找出路的經典場景。舞台上的情境變化莫測,需要臨場反應與即時調度,如同 ReAct Pattern 強調的「邊想邊做」:AI 不僅能規劃,更能在情境中不斷調整,學會臨機應變。(攝影:作者自攝)


 iThome鐵人賽
iThome鐵人賽