想像一下,你需要在不到 100 毫秒內,從數十億個網頁中找出最相關的結果。這不僅要處理拼寫錯誤、理解語意,還要考慮個人化偏好。更困難的是,每秒有數千個新內容產生,同時有上萬個查詢湧入。
這就是現代搜尋引擎每天面對的挑戰。搜尋看似簡單——輸入關鍵字,得到結果,但背後的系統設計卻是分散式系統、機器學習與資訊檢索理論的極致展現。
今天我們將從一個企業知識搜尋平台開始,逐步探索如何建構一個可擴展到億級文件規模的搜尋系統。
場景定義與需求分析
業務場景描述
一家科技公司需要建立內部知識搜尋平台,整合所有技術文件、程式碼庫、會議記錄與專案資料。員工經常抱怨找不到需要的資訊,重複解決相同問題。系統需要理解技術術語、支援多語言查詢,並根據使用者角色提供個人化結果。這個平台將成為知識管理的核心基礎設施,直接影響團隊生產力。
核心需求分析
功能性需求
- 全文搜尋:支援關鍵字、片語、布林運算、萬用字元查詢
- 語意理解:處理同義詞、縮寫、拼寫錯誤、相似概念
- 多格式支援:索引 PDF、Word、Markdown、程式碼、影片字幕
- 即時更新:新文件在 5 秒內可被搜尋到
- 權限控制:根據使用者部門、角色過濾搜尋結果
- 搜尋建議:自動完成、拼寫糾正、相關搜尋推薦
- 結果排序:綜合相關性、時效性、作者權威度、使用頻率
非功能性需求
- 效能要求:p50 < 50ms、p95 < 100ms、p99 < 200ms
- 併發量:日常 500 QPS、尖峰 2000 QPS
- 可用性:99.9% SLA(每月停機 < 43 分鐘)
- 擴展性:支援從 100 萬到 1 億文件平滑擴展
- 準確性:搜尋結果 MRR@10 > 0.8、DCG@10 > 0.7
- 安全性:端到端加密、完整審計日誌、GDPR 合規
- 成本限制:初期 < $5,000/月,規模化 < $50,000/月
核心架構決策
識別關鍵問題
技術挑戰 1:即時性與一致性的權衡
文件頻繁更新要求近即時索引,但過於頻繁的索引更新會產生大量小段(segments),影響查詢效能。如何在即時性與查詢效能間找到平衡點?
技術挑戰 2:多維度相關性排序
不同使用者搜尋「Python 錯誤」時期望不同——新手要教學文件、資深工程師要源碼、DevOps 要錯誤日誌。如何實現個人化排序同時保持低延遲?
技術挑戰 3:異質資料源整合
資料散落在 GitHub、Confluence、Slack、資料庫等多個系統。如何統一索引格式、處理更新通知、維護資料新鮮度?
架構方案比較
| 維度 |
單體 Lucene 方案 |
Elasticsearch 叢集 |
混合架構(ES + 向量DB) |
| 核心特點 |
單機部署,直接使用 Lucene |
分散式全文搜尋 |
關鍵字 + 語意雙路檢索 |
| 優勢 |
延遲極低、完全控制、成本低 |
成熟生態、易擴展、功能豐富 |
語意理解強、效果最佳 |
| 劣勢 |
擴展受限、開發成本高 |
運維複雜、資源消耗大 |
架構複雜、成本高 |
| 適用場景 |
< 100 萬文件、特殊需求 |
通用搜尋、100萬-10億文件 |
智慧搜尋、高品質要求 |
| 複雜度 |
低 |
中 |
高 |
決策思考框架
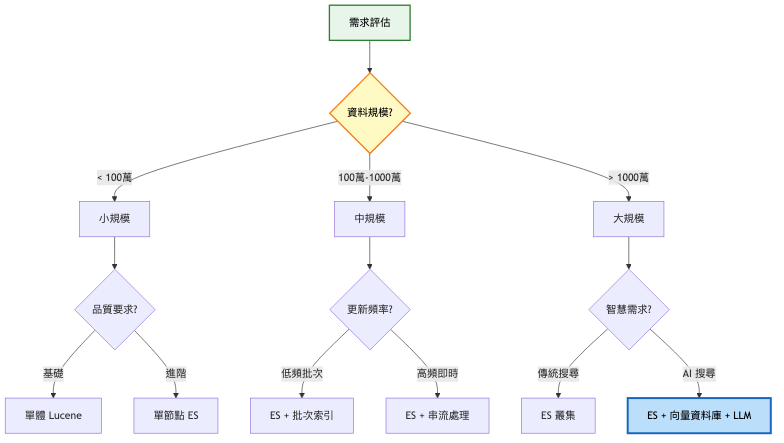
系統演進路徑
第一階段:MVP(0-1,000 使用者)
架構重點:
- 單一 Elasticsearch 節點處理所有功能
- 基本的 BM25 排序演算法
- 簡單的檔案處理管線
- 定時批次索引更新
系統架構圖:
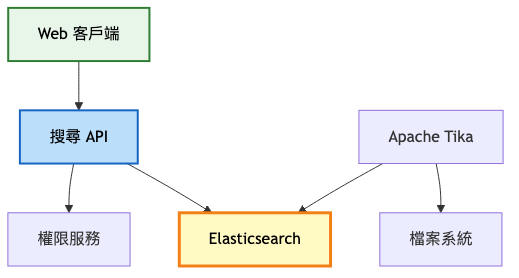
技術實現要點:
- 使用 Elasticsearch 單節點部署
- Apache Tika 處理多格式檔案解析
- 每小時執行批次索引更新
- 簡單的 JWT 權限驗證
第二階段:成長期(1,000-10,000 使用者)
架構重點:
- Elasticsearch 3 節點叢集提供高可用
- Redis 多層快取加速熱門查詢
- Kafka 訊息佇列實現即時索引
- 向量搜尋增強語意理解
- 基礎的個人化排序
系統架構圖:
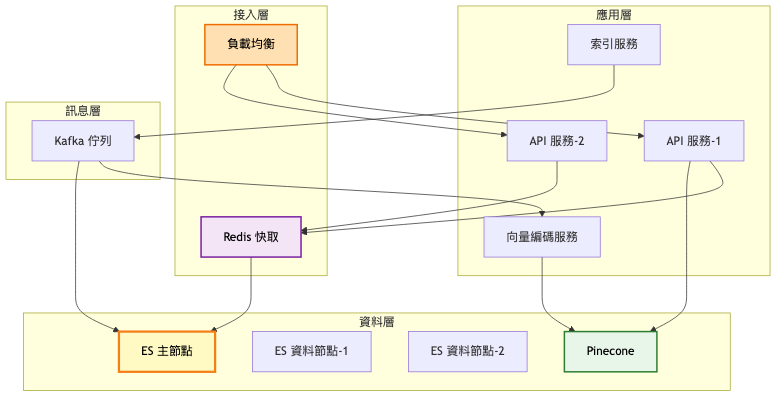
關鍵架構變更:
-
分散式索引架構
- 3 個主分片,每個 1 個副本
- 自動故障轉移機制
- 讀寫分離優化
-
快取策略優化
- L1:應用層本地快取(10MB)
- L2:Redis 分散式快取(1GB)
- L3:ES 查詢快取(堆記憶體 25%)
-
向量搜尋整合
- 使用 Sentence-BERT 生成 384 維向量
- Pinecone 託管向量索引
- 混合評分:0.7 × BM25 + 0.3 × 餘弦相似度
預期效能提升對比表:
| 指標 |
第一階段 |
本階段 |
改善幅度 |
| 查詢延遲 p95 |
150ms |
80ms |
-47% |
| 吞吐量 QPS |
200 |
1000 |
+400% |
| 索引延遲 |
1 小時 |
30 秒 |
-99% |
| 搜尋準確率 MRR@10 |
0.65 |
0.82 |
+26% |
第三階段:規模化(10,000+ 使用者)
架構重點:
- 微服務架構實現關注點分離
- 機器學習排序模型提升相關性
- Lambda 架構處理批次與即時資料
- 多區域部署降低延遲
- 完整的可觀測性平台
總覽架構圖:
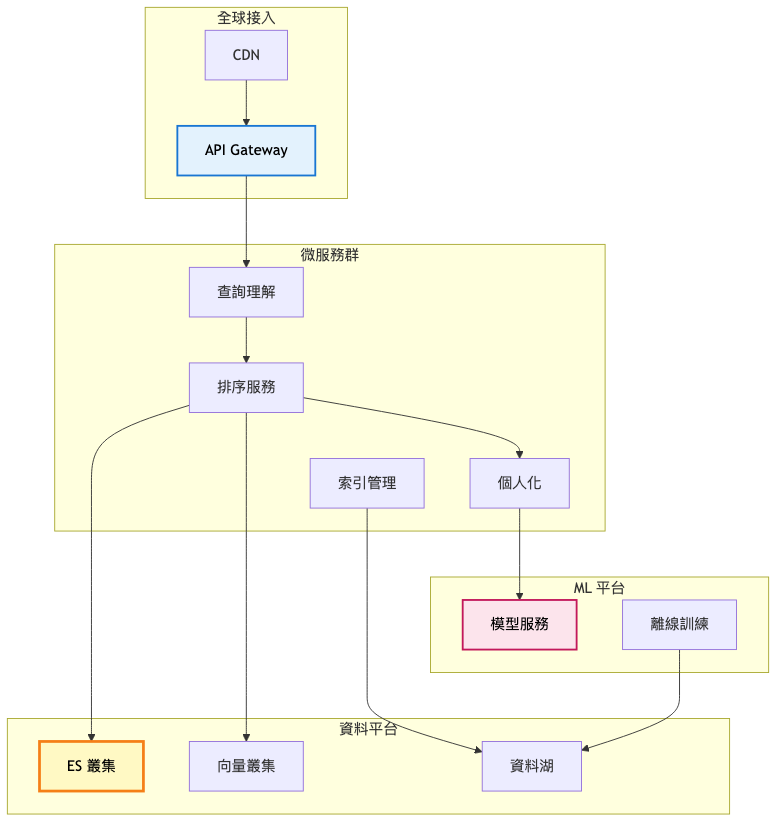
核心資料流架構(細節圖):
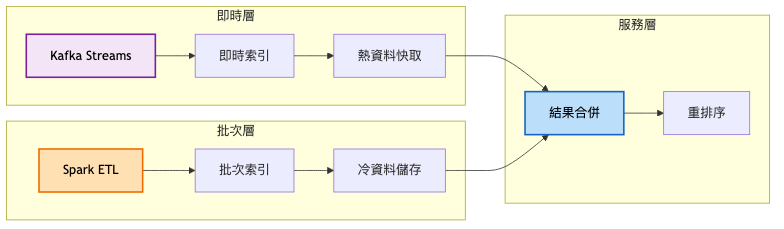
關鍵架構變更:
-
微服務拆分
- 查詢理解:意圖識別、實體抽取、查詢改寫
- 排序服務:多階段排序、Learning to Rank
- 個人化:使用者畫像、點擊預測、結果調整
-
機器學習整合
- XGBoost 排序模型,特徵維度 200+
- BERT 語意理解模型,處理複雜查詢
- 協同過濾推薦相關內容
-
多區域部署
- 主區域:完整服務部署
- 邊緣節點:快取 + 查詢服務
- 跨區域資料同步 < 1 秒
演進決策指南表:
| 觸發條件 |
採取行動 |
預期效果 |
| QPS > 1000 |
增加 ES 資料節點 |
查詢吞吐量 +80% |
| 文件數 > 1000 萬 |
啟用分片分裂 |
索引效能維持穩定 |
| 延遲 p99 > 200ms |
擴展快取容量 |
延遲降低 30-40% |
| 準確率 < 0.75 |
引入 ML 排序 |
MRR@10 提升 15-20% |
技術選型深度分析
關鍵技術組件比較
搜尋引擎核心
| 技術選項 |
優勢 |
劣勢 |
適用場景 |
| Elasticsearch |
生態完整、REST API、分析功能強 |
資源消耗大、JVM 調優複雜 |
通用搜尋、日誌分析 |
| Apache Solr |
配置靈活、細粒度控制 |
社群活躍度降低、學習曲線陡 |
企業搜尋、遺留系統 |
| Typesense |
輕量快速、開箱即用 |
功能受限、擴展性弱 |
小型應用、快速原型 |
| MeiliSearch |
簡單易用、內建 UI |
不支援分散式、功能基礎 |
產品搜尋、內部工具 |
向量資料庫選型
| 技術選項 |
優勢 |
劣勢 |
適用場景 |
| Pinecone |
全託管、自動優化、SLA 保證 |
成本高、vendor lock-in |
快速上線、中小規模 |
| Weaviate |
開源、GraphQL API、混合搜尋 |
資源需求高、運維複雜 |
知識圖譜、語意搜尋 |
| Qdrant |
Rust 實現、效能極佳、支援過濾 |
生態較新、工具鏈不完整 |
高效能需求、大規模 |
| Milvus |
功能完整、GPU 加速、雲原生 |
配置複雜、資源消耗大 |
企業級部署、混合雲 |
技術演進策略
-
初期快速驗證:Elasticsearch + PostgreSQL,專注業務邏輯
-
成長期增強能力:加入向量搜尋、快取層、訊息佇列
-
成熟期精細優化:微服務拆分、機器學習、多區域部署
實戰經驗與教訓
常見架構陷阱
-
過度分片導致性能下降
- 錯誤:創建 100 個分片「為未來準備」
- 正確:從 3-5 個分片開始,監控後逐步調整
- 原因:過多分片增加協調成本,小分片快取效率低
-
忽視 Mapping 設計影響
- 錯誤:使用動態 mapping,任由欄位自動創建
- 正確:預先定義 mapping,控制分詞器與索引選項
- 原因:錯誤的 mapping 無法修改,只能重建索引
-
快取雪崩風險
- 錯誤:所有快取同時過期,大量請求直擊資料庫
- 正確:隨機化 TTL、熱點資料預載入、多級快取
- 原因:瞬間流量可能擊垮後端服務
業界案例分析
案例:Elasticsearch 的 Serverless 架構演進 參考文章
發展歷程
-
初期(2010-2015)
- 架構特點:基於 Lucene 的分散式包裝,節點本地儲存
- 技術:Master-Data 節點架構、分片與副本機制
- 規模:單叢集支援數十節點、TB 級資料
-
成長期(2015-2021)
- 主要改進:跨叢集複製(CCR)、索引生命週期管理(ILM)
- 遇到的挑戰:節點故障恢復慢、擴縮容影響服務
- 解決方案:Snapshot/Restore、冷熱資料分層
-
近期狀態(2021-2025)
- 無狀態架構:計算與儲存分離,使用 S3 作為主儲存
- 效能提升:索引吞吐量提升 75%、成本降低 50%
- 未來方向:Serverless 彈性計費、智慧資源調度
關鍵學習點
- 狀態分離簡化運維:無需擔心資料遺失,節點可隨意替換
- 物件儲存需要智慧快取:本地 SSD 快取熱資料,S3 儲存全量資料
- 成本與效能可以兼得:通過分層儲存與智慧調度達到最佳平衡
關鍵設計模式
設計模式應用
CQRS 模式(命令查詢責任分離)
寫入路徑與查詢路徑完全分離,各自優化:
- 寫入路徑:批次處理、非同步索引、最終一致性
- 查詢路徑:多級快取、預先計算、結果預取
- 實施方式:不同的資料模型、獨立的擴展策略
Scatter-Gather 模式
分散查詢請求到多個節點,收集並合併結果:
- 應用場景:分片查詢、聯邦搜尋
- 實施要點:並行請求、超時控制、部分失敗處理
- 注意事項:避免扇出過大、合理設定超時時間
最佳實踐
-
索引設計:預先規劃 mapping、合理設定分片數、使用別名切換
-
查詢優化:使用 filter 代替 query、善用 aggregation 快取、避免深度分頁
-
運維策略:監控 JVM 記憶體、定期強制合併段、設定慢查詢日誌
監控與維護策略
關鍵指標體系
技術指標:
- 查詢延遲分佈(p50/p95/p99):目標 30ms/80ms/150ms
- 索引延遲(文件可搜尋時間):目標 < 5 秒
- 叢集健康狀態(green/yellow/red):目標 100% green
- JVM 堆使用率:目標 < 75%
業務指標:
- 點擊率 CTR(前 3 結果):目標 > 40%
- 平均互惠排名 MRR@10:目標 > 0.85
- 零結果查詢率:目標 < 3%
- 查詢放棄率(無點擊):目標 < 20%
維護最佳實踐
-
自動化運維
- 自動段合併減少碎片
- 根據查詢模式調整分片路由
- 基於 ILM 自動歸檔冷資料
-
監控告警
- 設定多維度告警規則
- 建立 on-call 輪值制度
- 定期演練故障恢復流程
-
持續優化
- 每週分析慢查詢日誌
- A/B 測試新排序策略
- 收集使用者反饋改進結果
總結
核心要點回顧
- 搜尋引擎設計需要平衡即時性、準確性、效能與成本
- 從單體到分散式的演進應該基於實際需求而非技術炫技
- 混合檢索(BM25 + 向量搜尋)提供最佳搜尋品質
- 快取策略與索引優化對效能影響巨大
- 可觀測性與反饋循環是持續改進的基礎
設計原則提煉
-
漸進演化原則:從簡單開始,根據實際需求逐步演進
-
分離關注點:索引、查詢、排序各自獨立優化
-
資料驅動決策:基於監控指標與使用者行為優化
-
容錯設計思維:假設任何元件都可能失敗並設計應對策略
-
成本效益平衡:不是所有資料都需要即時索引與高效能查詢
進階延伸關鍵字
針對今日探討的搜尋引擎系統設計,建議從以下關鍵字深化研究:
-
Learning to Rank (LTR):深入研究排序學習演算法,掌握特徵工程與模型訓練技巧,提升搜尋相關性。
-
Neural Information Retrieval:探索 BERT、ColBERT 等神經網路檢索模型,理解密集檢索的原理與實踐。
-
Query Understanding:學習查詢意圖識別、實體連結、查詢擴展等技術,提升系統理解能力。
-
Federated Search:了解跨異質資料源的聯邦搜尋架構,解決企業多系統整合挑戰。
-
Index Compression:研究倒排索引壓縮演算法如 PForDelta,優化儲存與查詢效能。
可根據興趣選擇深入方向,透過閱讀論文、參與開源專案、實作原型系統來累積經驗。
下期預告
明天我們將探討「即時通訊系統」的設計。當億級使用者同時線上,每秒產生百萬則訊息,如何確保訊息不丟失、順序正確、延遲極低?
我們將深入 WebSocket 長連接管理、訊息可靠投遞、端到端加密等核心挑戰,準備好了嗎?
後記
說實話,這是我第一次認真去了解搜尋引擎。雖然大部分是靠跟 AI 對話,一點一滴拼湊、構建出自己的理解,但還是很多地方只是模糊地懂,新的知識像海潮一樣湧進來,現在還沒完全理清楚。希望以後有機會能多花點時間好好鑽研搜尋引擎的技術,也想親自摸摸看向量資料庫怎麼運作。眼下嘛,我還是在傳統的關聯式資料庫裡打轉。
參考資源

