到目前為止,我們已經學過資料處理、視覺化、框架選擇,以及神經網路的基本原理。
而在討論過大致上理論的東西後,我們今天就要邁出更實際的一步 -
使用 Keras 建立一個最基礎的神經網路,來解決分類問題。
在這個練習中,我希望能幫助我把前面學到的知識連結起來,
並且更直觀地去感受「神經網路」如何透過數據學會分辨不同類別。
這裡的範例會用經典的鳶尾花 (Iris) 資料集,
它是許多初學者用來練習分類問題的常見資料集。
接下來,我們將按照完整的實作流程來帶大家一步步走過。
那我們就馬上開始吧!!!
關於鳶尾花 (Iris) 資料集的參考資料:
https://zh.wikipedia.org/zh-tw/%E5%AE%89%E5%BE%B7%E6%A3%AE%E9%B8%A2%E5%B0%BE%E8%8A%B1%E5%8D%89%E6%95%B0%E6%8D%AE%E9%9B%86
(簡單來說它就是包含花的很多特徵,像是花瓣的長度、寬度等等所創建的資料集)
首先在這個步驟中,我們需要先準備好資料集。
鳶尾花資料集是一個內建於 scikit-learn 套件的資料集,因此不需要另外下載。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
這個資料集包含 150 筆資料,
每筆資料有 4 個特徵(花萼長度、花萼寬度、花瓣長度、花瓣寬度),
以及對應的標籤(花的種類,共三類:Setosa、Versicolor、Virginica)。
載入資料後,我們會將特徵存放在 X 變數中,把標籤存放在 y 變數中。
這樣做的好處是能清楚區分「模型的輸入」與「模型要學會預測的輸出」。
程式碼如下:
# 載入鳶尾花資料集
iris = load_iris()
X = iris.data # 特徵(花萼長、花萼寬、花瓣長、花瓣寬)
y = iris.target # 標籤(0=setosa, 1=versicolor, 2=virginica)
原始資料雖然已經整理得很乾淨,但我們仍然需要做一些前處理,
以下是我們要新增的程式碼:
# One-hot encoding:將 0,1,2 轉換成 [1,0,0], [0,1,0], [0,0,1]
y = to_categorical(y, num_classes=3)
# 切分資料集,80% 訓練、20% 測試
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
我將上面區分成兩部分來做解釋:
因為鳶尾花的標籤原本是數字 (0, 1, 2),我們需要把它
轉換成「One-hot encoding」的形式,才能讓神經網路理解。
(這個部分我們在前幾天的文章有講過了,這邊不再贅述,連結下收:
https://ithelp.ithome.com.tw/articles/10382388
接著我們也要把資料分成「訓練集」和「測試集」。
訓練集用來讓模型學習,而測試集則保留到最後檢驗模型的效果。
常見的比例是** 80% 作為訓練**,20% 作為測試。
這些前處理的目的是確保模型能在「看過的資料」中學習,
但我們還能用「沒看過的資料」來驗證它的泛化能力。
接下來進入重頭戲:建立我們的神經網路模型。
這裡我們使用 Keras 的 Sequential 模型,因為它可以讓我們去一層一層地堆疊網路結構。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 建立模型
model = Sequential([
Dense(10, activation='relu', input_shape=(4,)), # 隱藏層,10 個神經元
Dense(3, activation='softmax') # 輸出層,3 個神經元
])
而在這個範例中我們使用了「隱藏層」以及「輸出層」,以下也針對兩者的內容做介紹:
第一層:隱藏層 (Dense layer)
我們將神經元數量設為 10、輸入維度設為 4 (特徵數量 = 4)。
並使用 ReLU 作為啟用函數,因為它能有效解決梯度消失問題,
並且在許多情境下表現相對來說比較好,這也是我們挑選它的原因。
第二層:輸出層 (Dense layer)
神經元數量設為 3,對應到鳶尾花的三種類別。
啟用函數則是使用 Softmax,因為我們希望輸出是三個機率數值,
代表樣本屬於三個類別的「可能性」。
這樣,我們就完成了一個
「輸入層 → 隱藏層 → 輸出層」的簡單神經網路架構。
在我們將模型架構定義好之後,我們還需要告訴 Keras 如何訓練它。
在這裡,我們要指定三個重要的部分:
我們會使用 adam。它是一種自動調整學習率的優化器,
比單純的梯度下降更穩定,並且是初學者最常用的選擇。
由於這是一個多分類問題,我們會使用 categorical_crossentropy。
這個函數能計算出「模型輸出的機率分布」與
「正確答案分布」之間的差異,數值越小代表預測越準確。
我們會使用 accuracy,也就是正確率。
這能幫助我們追蹤模型在訓練過程中的表現。
新增的程式碼如下:
model.compile(
optimizer='adam', # 優化方法
loss='categorical_crossentropy', # 損失函數
metrics=['accuracy'] # 評估指標
)
這些編譯模型的方式之前文章也都有提過,有興趣的讀者可以去翻找之前的文章看看。
倒數第二步,我們就要讓模型真正開始學了。
過程很簡單,我們把訓練資料餵進去,並告訴模型要學習幾次,
然後就讓他開始跑跑跑跑跑,直到達到我們指定的數量。
程式碼如下:
history = model.fit(
X_train, y_train,
epochs=50, # 學習 50 次
batch_size=16, # 每批 16 筆資料
validation_split=0.2, # 從訓練集再切 20% 出來做驗證
verbose=1
)
下面也簡單介紹程式碼中的特殊函數定義:
epochs是代表完整跑過所有資料的次數,
我們在範例中設為 50,意思就是要讓模型從頭到尾學習資料 50 次。
batch size則是代表一次要丟多少筆資料進去學習。
我們在範例中的 batch size 設為 16,
就是把資料切成小份,讓模型分批更新權重。
我們把訓練資料的一部分(這邊是 20%)拿來當「驗證資料」。
這樣模型在每個 epoch 結束後,會同時回報「在訓練資料上的表現」
以及「在驗證資料上的表現」。
有助於我們檢查模型是否過度擬合。
這個過程就是所謂的「前向傳播 + 反向傳播」重複進行,
模型會逐步更新權重,並試圖讓損失函數變得越來越小。
最後一步!!!
我們就會使用一開始保留下來的測試資料(剛剛講的20%),
用來檢驗模型的最終表現。
在這個步驟中,我們只需要呼叫 model.evaluate(),
就能得到測試集的損失值和正確率。
這代表模型在「沒看過的資料」上表現如何。
程式碼!:
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f"測試集損失值: {loss:.4f}")
print(f"測試集正確率: {accuracy:.4f}")
接著我們就來看看執行後的成果吧:
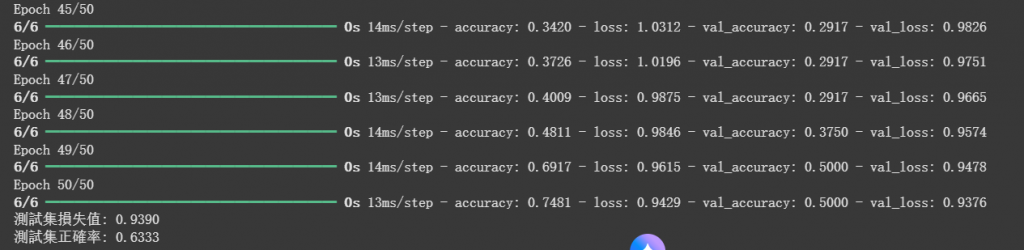
可以看到總共運行了50次訓練,但最後只得到了63%的正確率。
針對這個結果,有可能是以下原因導致:
我們用了只有 10 個神經元的單層隱藏層,可能不足以捕捉特徵。
我們只跑了 50 次,模型可能還沒完全收斂。
Iris 只有 150 筆資料,測試集只有 30 筆,一旦分配剛好不均,正確率就會受影響。
train_test_split 預設有隨機性,若分到比較「難分」的測資,就會降低表現。
但由於我們只是為了測試,要增加層數的話所需的時間也會大幅增加,
因此我們的實作就先到這邊,
若是有興趣的可以再透過增加層數、訓練次數等來提高正確率,
我也將完整程式碼放在下方,可自行取用。
# 匯入需要的套件
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 1. 載入資料
iris = load_iris()
X = iris.data # 特徵(花萼長、花萼寬、花瓣長、花瓣寬)
y = iris.target # 標籤(0=setosa, 1=versicolor, 2=virginica)
# 2. 資料前處理
y = to_categorical(y, num_classes=3) # one-hot encoding
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. 建立模型
model = Sequential([
Dense(10, activation='relu', input_shape=(4,)), # 隱藏層
Dense(3, activation='softmax') # 輸出層
])
# 4. 編譯模型
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 5. 訓練模型
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=16,
validation_split=0.2,
verbose=1
)
# 6. 評估模型
loss, accuracy = model.evaluate(X_test, y_test, verbose=0)
print(f"測試集損失值: {loss:.4f}")
print(f"測試集正確率: {accuracy:.4f}")

