當我們在訓練神經網路時,其實模型就像是一個學生在學習。
我們給它資料、給它目標答案,它就一步步調整自己,希望能越來越聰明。
但問題來了:我們怎麼知道它到底學得好不好?
是不是有過度學習(overfitting),又或根本還沒學會(underfitting)
,還是其實是在偷玩遊戲?
在這時候,「訓練過程可視化」就派上用場了。
顧名思義,就是要讓我們的眼睛可以看到它的學習過程,而不是只透過冷冰冰的文字。
我們會透過把 Loss (損失值)和 Accuracy (正確率)隨著訓練回合(epoch)的變化畫出來,
就能夠清楚地看到模型的學習曲線。
而今天,我們就會著重在介紹以下兩種曲線形式:
**「Loss 曲線」**與 「Accuracy 曲線」,
並針對這兩個呈現方式與實作結合,進行可視化呈現。
事不宜遲,馬上開始!!!
那接著,我們就先來介紹一下這兩個曲線所代表的含意:
Loss 就像是「考卷上總共扣了幾分」。它不是單純的對或錯,
而是衡量「模型的答案和正確答案之間的差距」。
如果 Loss 很高,代表模型答得很離譜,學得不好。
如果 Loss 越來越低,代表模型正在逐漸掌握規則,答案越來越接近正確。
Loss 曲線 就是把這個「扣分情況」隨著學習時間(Epoch 數)畫出來。
通常我們希望 Loss 曲線能夠隨著訓練逐步下降,
越來越靠近零,代表模型真的有在進步。
Accuracy 就比較直觀,它就是「考試答對的題目比例」。
如果 Accuracy 是 0.8,代表有 80% 的題目答對了。
Accuracy 越高,模型的表現就越接近我們的目標。
Accuracy 曲線 就是把這個「答對比例」隨著學習時間畫出來。
通常我們希望 Accuracy 曲線能一路往上升,最後穩定在一個較高的數字,
代表模型學到了一個可靠的規則。
光看訓練的 Loss 和 Accuracy,有時會誤導我們。
因為模型有可能只是「死記」訓練資料,導致在新的資料上表現不好。
因此我們會同時畫兩條曲線:
訓練曲線 → 告訴我們模型在「課堂作業」的表現。
驗證曲線 → 告訴我們模型在「模擬考」的表現。
大家上過課也都知道,作業通常都是很經典的題型或考古題,
有時候多花一點時間就能把大概的計算方式記起來,甚至一看到題目就知道答案了。
但模擬考就是完全不一樣的世界了,總是會有你沒有接觸過的題目類型,
這也就是為什麼考試才是比較有鑑別度的方式。
這個邏輯也可以套用到我們的訓練過程中,
如果訓練 Accuracy 越來越高,但驗證 Accuracy 卻停滯甚至下降,
這就好像剛剛我們說到的情況:
學生背熟了練習題,卻無法靈活應用,這就是典型的**「過度學習」**(Overfitting)。
在今天的實作中,我們將會延續第 13 天的 Keras 程式,
只是這次需要在訓練後多加上「繪製曲線」的程式碼。
以下就直上程式碼了,請看:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import to_categorical
# 1. 載入資料
iris = load_iris()
X = iris.data
y = iris.target
# 2. 資料前處理
y = to_categorical(y, 3)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 3. 建立模型
model = Sequential([
Dense(10, activation='relu', input_shape=(4,)),
Dense(8, activation='relu'),
Dense(3, activation='softmax')
])
# 4. 編譯模型
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
# 5. 訓練模型(保留訓練紀錄)
history = model.fit(
X_train, y_train,
epochs=50,
batch_size=5,
validation_split=0.2,
verbose=1
)
# 6. 繪製訓練過程圖表
plt.figure(figsize=(12, 5))
# 損失曲線
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='訓練 Loss')
plt.plot(history.history['val_loss'], label='驗證 Loss')
plt.title('Loss 曲線')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# 正確率曲線
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='訓練 Accuracy')
plt.plot(history.history['val_accuracy'], label='驗證 Accuracy')
plt.title('Accuracy 曲線')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# 7. 評估模型
loss, acc = model.evaluate(X_test, y_test, verbose=0)
print(f"測試集損失值: {loss:.4f}")
print(f"測試集正確率: {acc:.4f}")
以下則是產生出的結果: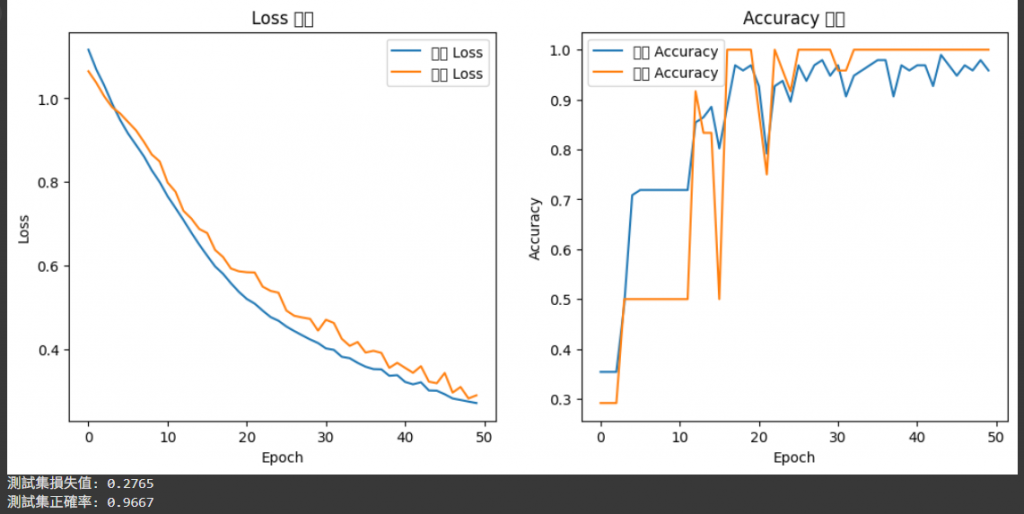
我們可以發現,Loss(損失值)在不斷降低,
而Accuracy(正確率)則在不斷攀升。
同時我們看到最後的結果也可以發現最終的準確率是非常高的,
符合我們期望的結果。
除此之外,驗證與訓練曲線的貼近,也代表模型沒有嚴重過擬合,泛化效果良好。
透過這個幾乎滿分的結果,
我們也可以宣布:完成了這次訓練過程可視化的實作了!

