經過 Day 8 的小批次訓練和正規化,我們的神經網路冒險隊伍已經擁有了強大的穩定術。現在,隊伍已經穩定,接下來要解決的核心問題是:模型要採取什麼樣的策略來執行修正,才能更快、更聰明地抵達 Loss 的最低點?
今天我們就要來拆解優化器(Optimizer),它是 Day 7 談到的梯度的執行者,也是決定訓練效率的核心關鍵。優化器的唯一目標,就是利用梯度下降法 找到損失函數曲面上的最低點。
不同優化器在 Loss 曲面上的收斂路徑對比。可以看到,SGD 路線曲折且震盪;而 Adam 與 Momentum 則能利用更智慧的策略,以更穩定、更高效的路徑逼近 Loss 谷底。
📌 執行修正的原則
整個學習過程的修正迴路由三個核心要素組成:
損失函數 Loss Function:告訴模型「錯了多少」,是衡量當前錯誤程度的指標。
梯度 Gradient:指出 Loss 上升最快的方向(熱區)。
優化器 Optimizer:沿著梯度的反方向移動,負責實際調整權重。
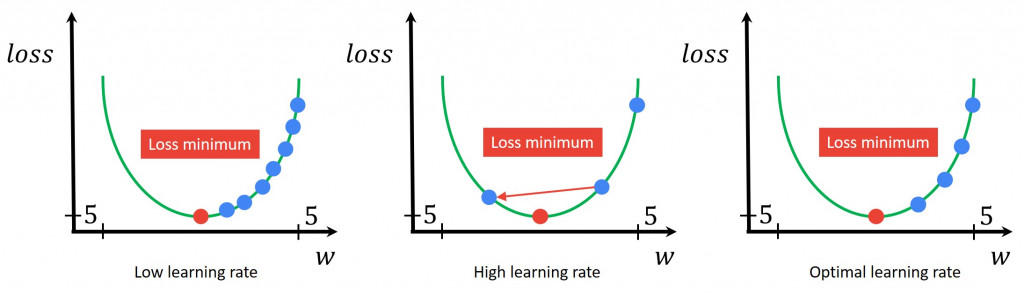
👣 學習率 Learning Rate,𝜂
η:步長決定成敗
定義:學習率決定了優化器在梯度方向上更新權重的幅度。
挑戰:
η 的選擇是訓練中最難平衡的環節。
| η 選擇 | 訓練結果 | 潛在問題 |
|---|---|---|
| 太高 (η ↑) | 步幅過大 | 模型在 Loss 谷底附近劇烈震盪,可能跳過最低點而發散,最終無法收斂 |
| 太低 (η ↓) | 步幅過小 | 收斂極慢,如烏龜爬行,浪費大量時間 |
💡 實務習慣:很少使用單一固定的學習率,通常搭配學習率排程 Scheduler 逐步調整。
二、三種經典優化器策略:從簡單到高效
優化器的演進,就是讓「移動腳步」更聰明、更有效率的過程。以下是深度學習中三種最具代表性的策略:
🚶 SGD (Stochastic Gradient Descent):簡單直接,但方向噪音大
SGD 是所有優化器的基石,但它的策略也最為單純。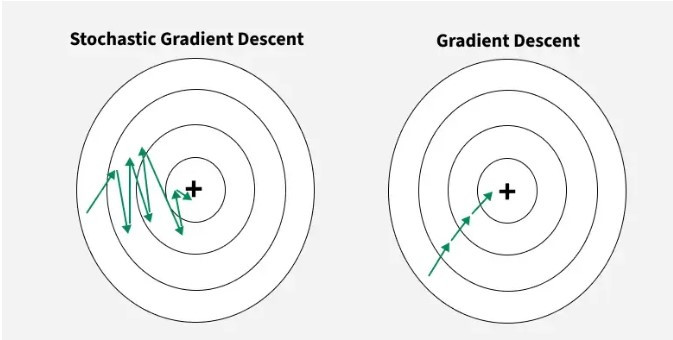
SGD 的運作核心是:每次僅用一個小批量 mini-batch 的梯度來更新權重;因此它計算量小、速度快、記憶體負擔低,也相對好實作。然而因為只依賴當前這一小批資料的梯度,訊號中噪音極高,更新方向容易忽左忽右,導致在損失曲面上像醉漢走路一樣劇烈震盪,往往難以穩定且高效地逼近最低點。
🏂 Momentum (動量):加上「慣性」,減少來回震盪
Momentum 的出現,是為了讓 SGD 變得更「清醒」、更有效率。
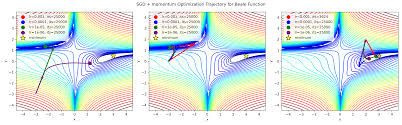
Momentum 的概念是在梯度下降中引入動量,借鑒物理慣性:不僅看當前一步的梯度方向,還綜合前幾次更新的方向與速度,讓每次權重更新都帶有明顯的慣性;這像在滑雪——遇到陡峭區域時,慣性能幫你穿透梯度噪音、減少來回震盪、行進更穩定;到了平坦區域時,慣性又能推著你加速前進,避免在接近低谷時龜速爬行。
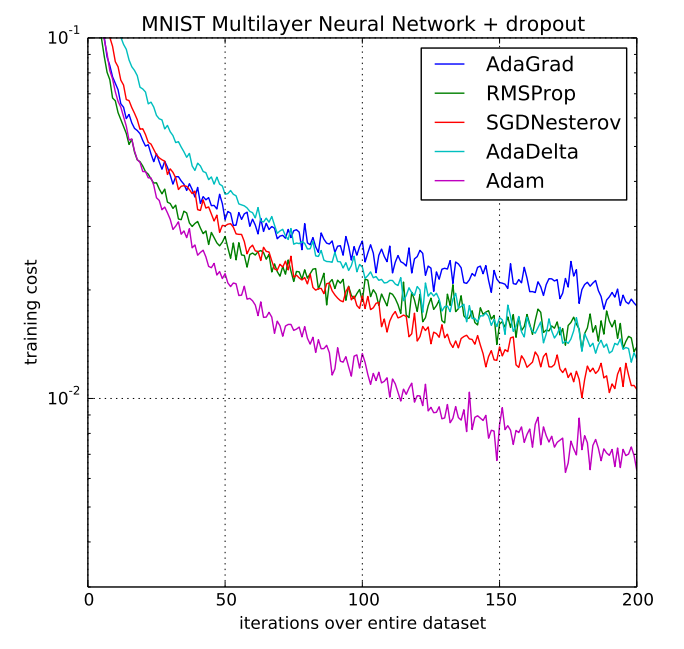
Adam 的精髓在於結合兩大智慧機制:一階矩估計承接動量的慣性,二階矩估計引入 RMSprop 的自適應特性;因此它能為網路中的每個權重獨立調整最合適的學習率,對不同參數採用不同的移動速度,讓模型在各種複雜的損失地形中依然收斂又穩又快,常以更短路徑高效逼近損失谷底。
三、視覺化:不同優化器的收斂路徑
圖說:不同優化器在 Loss 曲面上的收斂路徑對比。Momentum 與 Adam 較能穩定避開震盪並快速逼近低點,相較基礎的 SGD 更高效。
| 優化器 | 核心策略 | 實戰表現 |
|---|---|---|
| SGD | 僅依賴當前梯度 | 易震盪,收斂較慢 |
| Momentum | 考慮歷史移動方向 慣性 | 減少震盪,加速平坦區域的收斂 |
| Adam | 為每個參數自適應調整學習率 | 高效穩定,多數任務的常用首選 |
這些optimizer 有很多更詳細的內容礙於篇幅我無法全部放上來,有興趣可以去參考這些網站:
https://www.geeksforgeeks.org/machine-learning/ml-stochastic-gradient-descent-sgd/
https://datahacker.rs/016-pytorch-three-hacks-for-improving-the-performance-of-deep-neural-networks-transfer-learning-data-augmentation-and-scheduling-the-learning-rate-in-pytorch/

