今天換個輕鬆的方式:用 TensorFlow Playground 來「看見」神經網路怎麼學習。這個互動平台就像一個神經網路戰鬥地圖,你可以自由調整參數,然後立刻看到模型的決策邊界如何改變。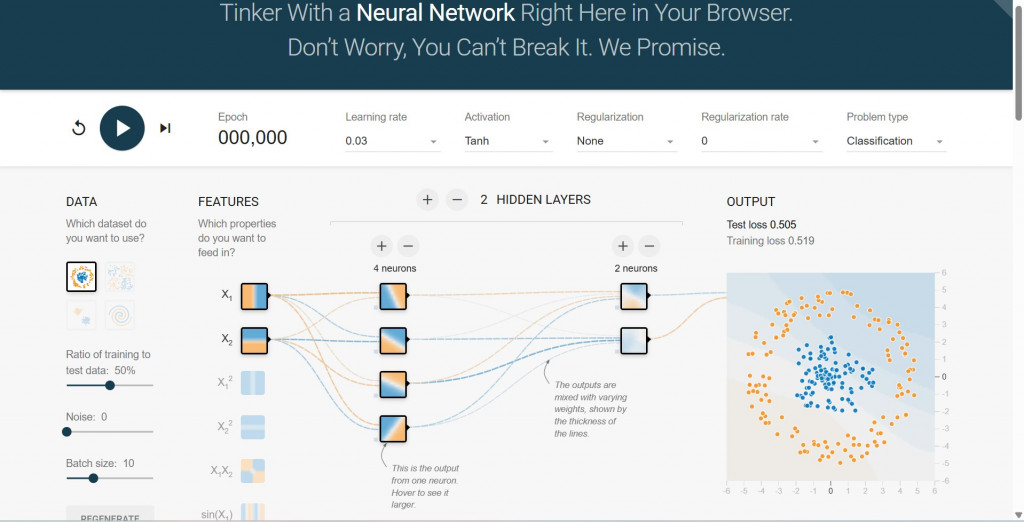
下面我用這張圖,把介面分區講解:
神經網路互動平台介紹
這個互動平台讓你像玩遊戲一樣,親手體驗神經網路的運作原理。整個介面可以分為幾個主要部分:
資料集 (DATA)
在左下角的區域,你可以選擇不同的資料類型,這就像在挑選遊戲關卡的難度:
雙環 (circles):典型的非線性問題。
雙月 (moons):一個常見的玩具數據集。
螺旋 (spiral):需要深層模型才能解決的高難度挑戰。
棋盤 (grid):測試模型劃分複雜邊界的能力。
你還可以調整訓練/測試的比例、資料噪聲 (Noise),以及每次訓練處理的批次大小 (Batch size),來模擬不同現實情境下的資料複雜度。
特徵 (FEATURES)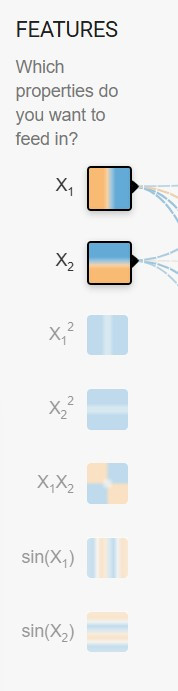
位於左中區,這個部分就像是模型的「裝備庫」。除了基本的輸入 X1 X2 之外,你還可以勾選二次方、乘積或三角函數等高階特徵。啟用這些選項後,輸入資料將帶有更多資訊,這能幫助模型更快地捕捉到資料中隱藏的模式,解決更複雜的問題。
隱藏層 (HIDDEN LAYERS)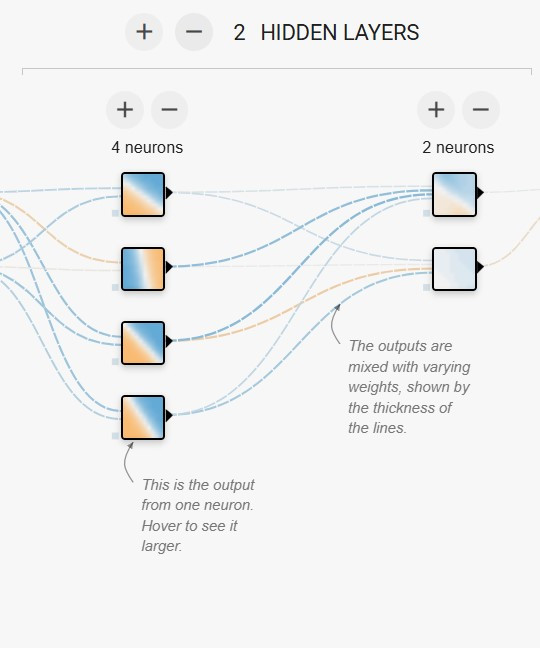
畫面中央是神經網路的「核心隊伍」。你可以自由增加或刪除層數,並調整每層的神經元數量。這就像在配置你的戰隊:更多層次和神經元通常能提升模型的解決能力,但也會增加運算成本。神經元之間的連線顏色代表權重:藍色是正權重,橘色是負權重,而線條的粗細則表示權重的大小。
訓練設定
位於畫面上方,這裡決定了模型的「訓練節奏」。學習率 (Learning rate) 決定了模型每次更新的速度;激活函數 (Activation),如 Tanh、Sigmoid 或 ReLU,則控制了神經元的輸出。正規化 (Regularization) (L1 或 L2) 可以幫助模型避免過度擬合,確保它在面對新資料時也能表現良好。
輸出 (OUTPUT)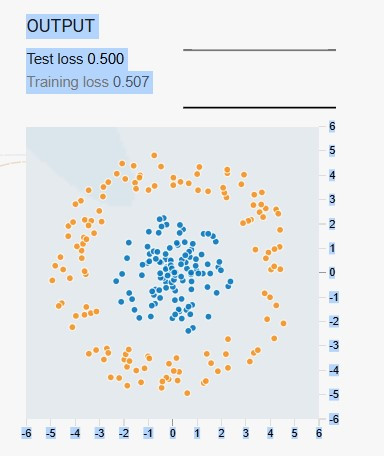
在右下角,你會看到模型的「戰鬥結果」。背景顏色代表模型預測出的分類邊界,顏色越深,代表模型的預測信心越高。橘色和藍色的資料點則是實際的類別分佈。你可以透過右上方顯示的Test loss 和 Training loss,來即時觀察模型在訓練過程中的誤差變化。
這個平台提供了一個直觀且互動的方式,讓你親手操作神經網路,深入理解它如何從數據中學習和分類。接下來打開 TensorFlow Playground,用手感驗證我們學到的觀念:非線性、過度擬合、與優化器效率~
| 任務 | 觀念重點 | 數據集 | 核心操作 | 觀察重點 |
|---|---|---|---|---|
| 1 | 非線性 | Moons | A 移除隱藏層;B 增加 2–3 層 | 決策邊界由直線變曲線 |
| 2 | 過度擬合 | Spiral | Noise 調到最高;無正規化 | Train Loss 低、Test Loss 高 |
| 3 | 優化器 | Circles | LR = 0.0001;SGD ↔ Adam | Adam 收斂 Epoch 大幅減少 |

