完整程式碼可在 GitHub 專案中找到:Finetune-30-days-demo / day-20
在 Day 19 ,我們畫出了專案的 依賴關係圖,赫然發現 train_lora_v2.py 幾乎連接所有模組,是最大的耦合點。這樣的設計帶來了兩個問題:
因此,在今天的工作中,我針對這些耦合點進行 重構,並設計了 整合測試 來驗證成果。
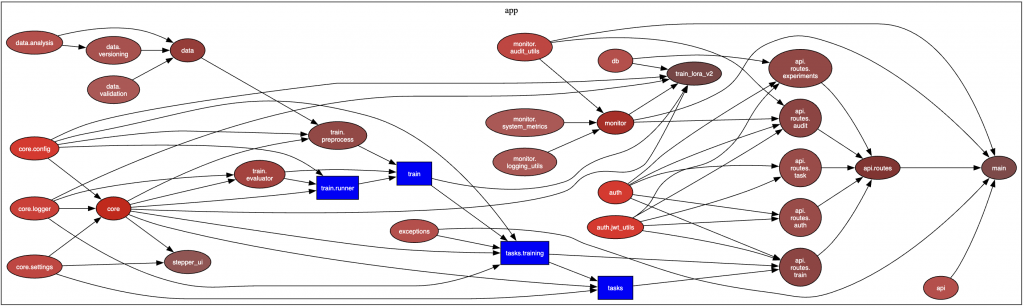
train/preprocess.py:負責資料前處理train/runner.py:核心訓練流程train/evaluator.py:模型評估👉 每個模組責任單一,維護更簡單。
monitor/system_metrics.py:CPU、記憶體、tokens/sec 監控monitor/logging_utils.py:訓練日誌monitor/audit_utils.py:操作審計👉 原本雜亂的依賴,現在變得清晰許多。
根據依賴圖,我挑選了兩條最關鍵的路徑,設計了 end-to-end 測試:
路徑:api.routes.train → tasks.training → train.runner → db → results
驗證內容:
/train 提交一個訓練任務train.runner
results/{exp}/metrics.json 是否正確寫入✅ 測試結果:順利通過,驗證了「提交 → 訓練 → 記錄」的完整流程。
路徑:api.routes.auth → auth.jwt_utils → api.routes.task
驗證內容:
/login 登入取得 token✅ 測試結果:RBAC(基於角色的權限控制)運作正常。
這次的重構與整合測試,讓專案從「能跑」逐漸邁向「能維護」。依賴圖揭示了最大的耦合點,拆分後的模組責任更加單一,系統邊界也更清晰。搭配整合測試,我們不僅確保了訓練流程與認證授權能完整串接,也降低了未來修改帶來的風險。
最終成果包括重構後的依賴圖 (docs/deps.svg) 與整合測試 (tests/test_integration.py),它們不只是驗證今天的成果,更是日後持續擴展與優化的基石。平台從此不僅可運行,更能長期穩健演進。
📎 AI 協作記錄:今日開發指令
今天的開發目標是 降低耦合度 + 建立整合測試。由於這兩個任務都相對龐大,若一次下指令可能會造成反覆修改、不易追蹤,因此我將它們拆成 兩次獨立指令:
第一次指令 → 專注於重構
先把 train_lora_v2.py 和 monitor/ 拆分,讓系統結構更乾淨,責任更單一。這一步完成後,確保功能與 import 都能正常運作。
請幫我針對專案做以下修改:
1. 拆分訓練模組 `train_lora_v2.py`:
- 新增資料夾 `app/train/`,並分成以下模組:
- `preprocess.py`:資料處理(驗證、tokenization)
- `runner.py`:訓練主流程(模型載入、optimizer、訓練 loop)
- `evaluator.py`:評估流程(驗證集、metrics)
- 原本的 `train_lora_v2.py` 改成一個「入口點」,只負責呼叫這些子模組。
2. 重構監控模組 `monitor/`:
- 拆分為以下檔案:
- `logging_utils.py`:訓練 log 與進度追蹤
- `system_metrics.py`:CPU、memory 資源監控
- `audit_utils.py`:稽核紀錄(保留與 audit_log 的整合)
- 修改相關 import,避免所有監控邏輯都集中在單一檔案。
3. 更新 import:
- 修改 `tasks/training.py` 與 `api/routes/train.py` 的引用,確保能正確呼叫新的模組結構。
請保留原有功能,但降低 `train_lora_v2` 與 `monitor` 的耦合度。
第二次指令 → 專注於測試
在重構完成並確認穩定後,再補上 整合測試,驗證新的模組邊界與核心流程是否正常運作。這樣可以避免「邊重構邊測試」導致不斷修正,讓開發流程更清晰。
請幫我新增一個整合測試檔案 `tests/test_integration.py`,包含以下兩條主要路徑:
1. **訓練流程整合測試**
- API: 呼叫 `/train` 提交任務
- Worker: 等待 Celery 任務完成
- DB: 驗證實驗記錄已寫入 SQLite
- File: 驗證對應 `results/{experiment}/metrics.json` 存在且格式正確
- 驗證點:
- response status = 200
- DB entry 存在,包含 experiment_name
- metrics.json 有 `accuracy` 與 `runtime`
2. **認證 + 任務存取測試**
- API: 呼叫 `/login` 取得 JWT token
- API: 使用 token 呼叫 `/task/{id}`
- 驗證權限:
- 自己的任務 → 200 成功
- 存取其他人任務 → 403 Forbidden
- 未帶 token → 401 Unauthorized
測試需使用 pytest,並加上合理的 mock(例如 mock Celery 執行結果),避免真的觸發完整訓練。
這樣拆分的好處是:


 iThome鐵人賽
iThome鐵人賽