完整程式碼可在 GitHub 專案中找到:Finetune-30-days-demo / day-27
在前一天,我們已經能用 Prometheus + Grafana 看到平台的任務與系統指標。
但這些數字的意義只有在真實負載下才成立。
因此,今天的目標是模擬真實使用者的行為,觀察整個系統在壓力下的反應。
傳統的壓測工具多半只是「打 API」,而我們的目標更進一步:
不只是測試 FastAPI 的吞吐量,而是驗證整個 任務系統鏈路(API → Celery → Redis → Worker)。
這樣才能知道:
/train 任務能否被正確排入佇列?使用 Locust 建立 TrainUser 類別,模擬一般使用者的行為循環:
/auth/login
/train 提交任務這樣的壓測能驗證整個認證與任務流程,而不是單純的 API 打點。
設定使用者數量(例如 50 位)、任務間隔(1–3 秒),並限制最大請求數。
測試目標不是「讓系統崩潰」,而是觀察系統何時開始出現延遲,並找出穩定區間。
範例邏輯(簡化):
class TrainUser(HttpUser):
def on_start(self):
# 登入一次並保存 Token
response = self.client.post("/auth/login", json={"username": "demo", "password": "demo"})
token = response.json()["token"]
self.client.headers.update({"Authorization": f"Bearer {token}"})
@task
def submit_train_job(self):
# 提交訓練任務
payload = {"config_path": "config/default.yaml"}
self.client.post("/train", json=payload)
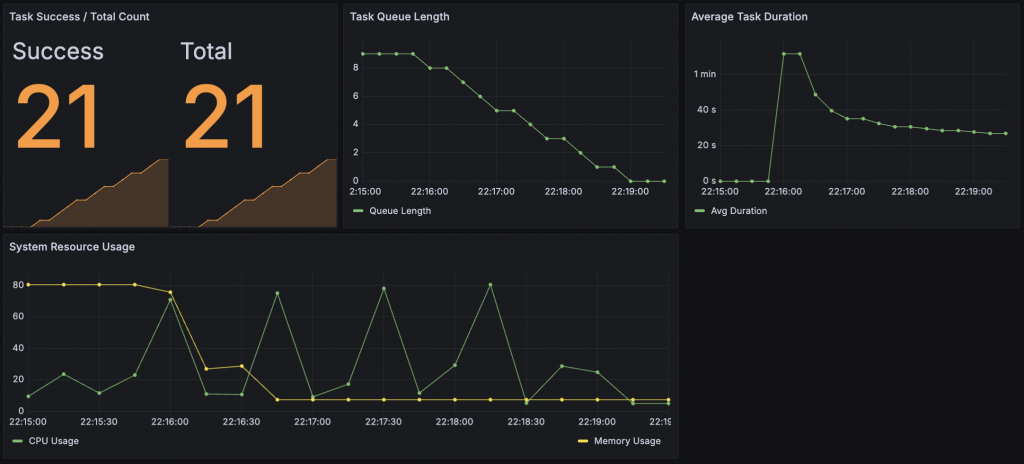
這張圖板整合了 任務執行效率 與 系統資源使用狀況,
可以在一次壓測後直觀看出整個平台的「穩定度」。
整體分為四個指標區塊:
Task Success / Total Count
Task Queue Length
Average Task Duration
在這裡,為了方便觀察,我將指標顯示內容改為平均任務耗時
System Resource Usage (CPU / Memory)
整體觀察顯示,平台在 高併發 + 重複提交訓練任務 的情境下表現穩定:
這次壓測證明了整個訓練與任務系統具備「穩定消化任務、可預期資源使用」的特性,
是進入 Day 28 多租戶與治理階段前,系統可靠性驗證 的重要里程碑。
這一天的成果,讓我們從「觀測系統」進化為「理解系統」。
壓測不只是找出誰慢,而是讓工程師能夠預測系統在壓力下的行為。
Prometheus 是眼睛,Grafana 是儀表板,而 Locust 就是風洞。
三者合在一起,讓平台從「能跑起來」變成「跑得穩」。
📎 AI 協作記錄:今日開發指令
# 1️⃣ 建立壓測腳本
請幫我建立 tests/load_test.py:
- 使用 Locust
- 模擬 50 位使用者,每 1~3 秒送一次 /train 任務
- 持續 5 分鐘
- 無介面模式運行,輸出平均響應時間與成功率
# 2️⃣ Makefile 新增
make load-test:
locust -f tests/load_test.py --headless -u 50 -r 5 -t 5m
# 3️⃣ 壓測後分析
請幫我在 Grafana 中設定 dashboard 查詢:
- task_success_total / task_failure_total
- task_queue_length
- task_duration_seconds 平均值
- system_cpu_percent / system_memory_usage_gigabytes


 iThome鐵人賽
iThome鐵人賽