在過去 28 天裡,我們完成了:
這些模組雖然各自獨立,但真正的價值在於它們被串聯起來,
形成「資料 → 訓練 → 部署 → 觀測」的完整流程。
今天,我們要讓這一切一次跑起來——一鍵啟動、一鍵提交、一鍵觀測。
| 步驟 | 功能說明 | 來源篇章 |
|---|---|---|
| 1️⃣ | 啟動整套服務(API / Worker / Redis / MLflow / Grafana) | Day 24 — Helm 部署 |
| 2️⃣ | 登入並取得 JWT Token | Day 16 — 認證與 RBAC |
| 3️⃣ | 提交訓練任務 | Day 12 — 任務佇列與 Celery |
| 4️⃣ | 產生 MLflow 實驗記錄 | Day 22 — 實驗追蹤 |
| 5️⃣ | 註冊與版本管理模型卡 | Day 23 — Model Registry |
| 6️⃣ | 進行推論與模型推薦 | Day 21 — 模型共享與推薦 |
| 7️⃣ | 即時監控整體效能與資源 | Day 26 — 可觀測性 |
整個流程會同時在終端、UI 與 Grafana 上發生。
系統不只是被動回應,而是「自己證明自己在運作」。
以下圖片展示了從登入到監控的整體過程:
1️⃣ 叢集啟動狀態圖
先執行 make helm-deploy 後,再透過 make k8s-status 查看所有服務狀態。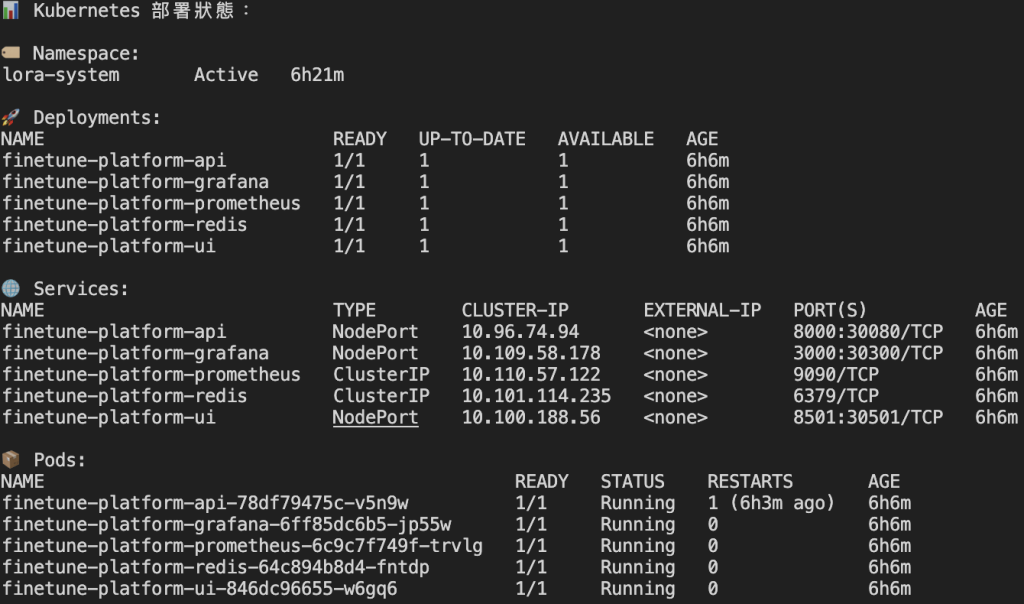
2️⃣ 登入畫面
:進入 UI 介面後,會預設跳轉至登入畫面,也可以選擇訪客登入。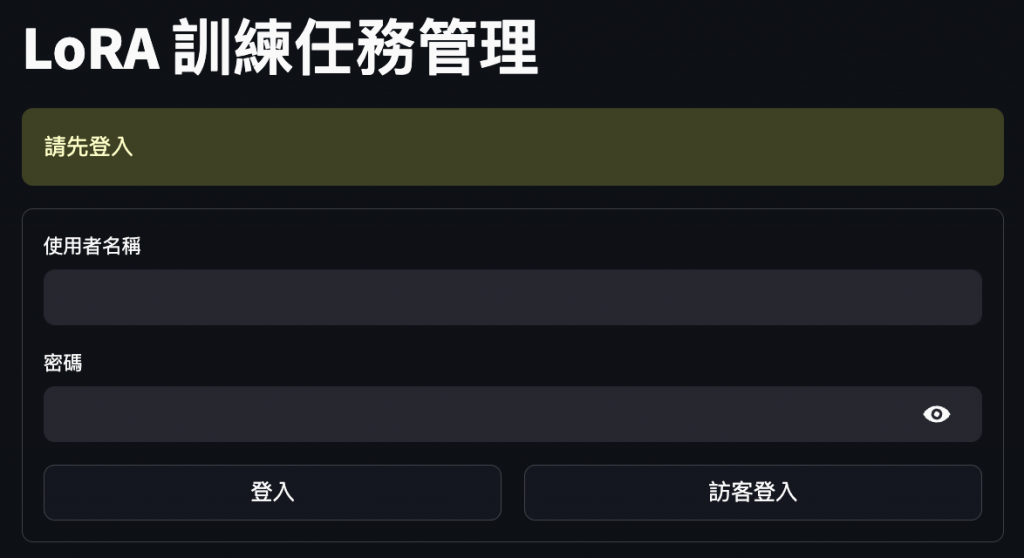
3️⃣ 訓練任務畫面
:可以建立訓練,管理頁面會自動帶入最新實驗 id,實時更新訓練進度。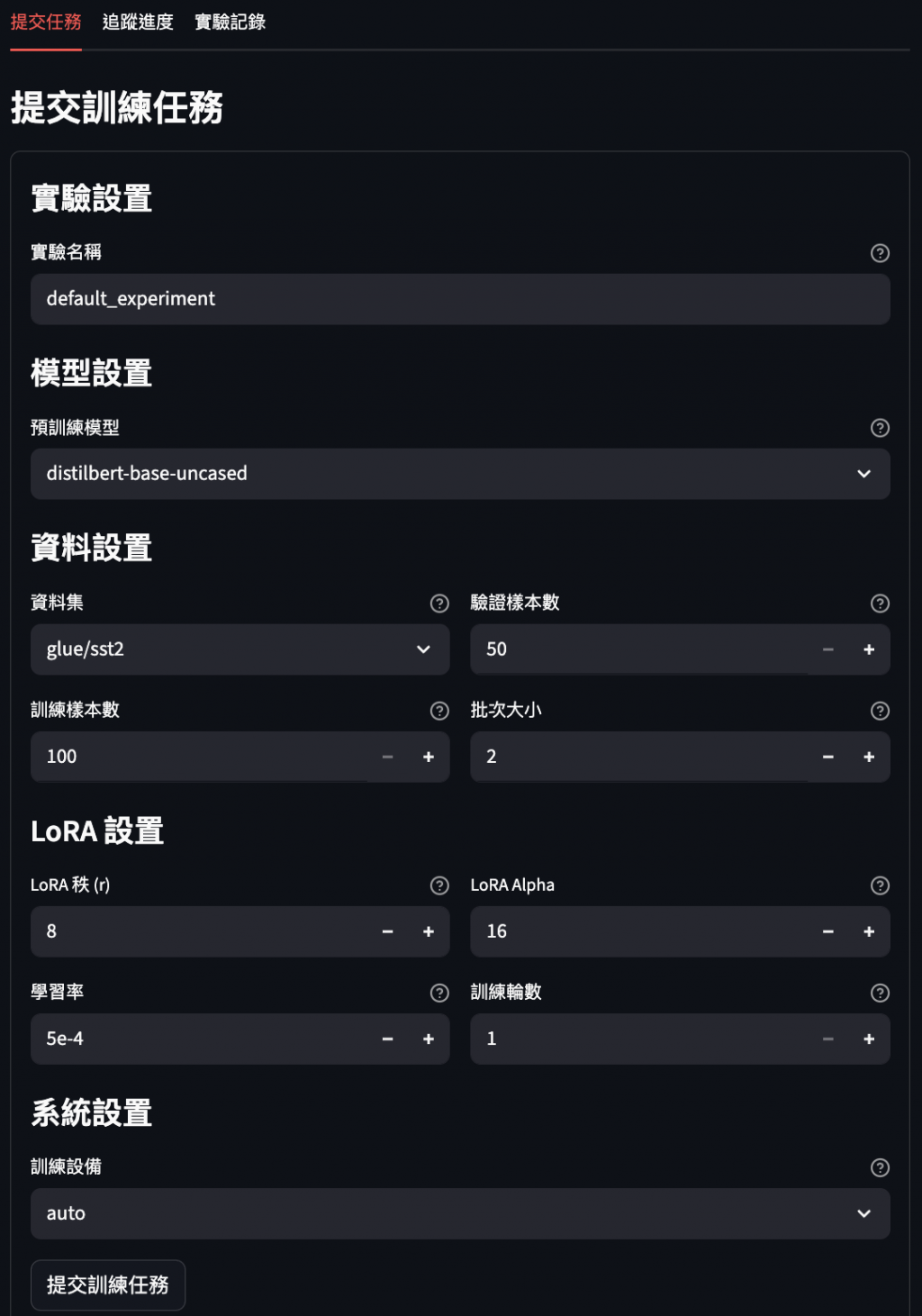
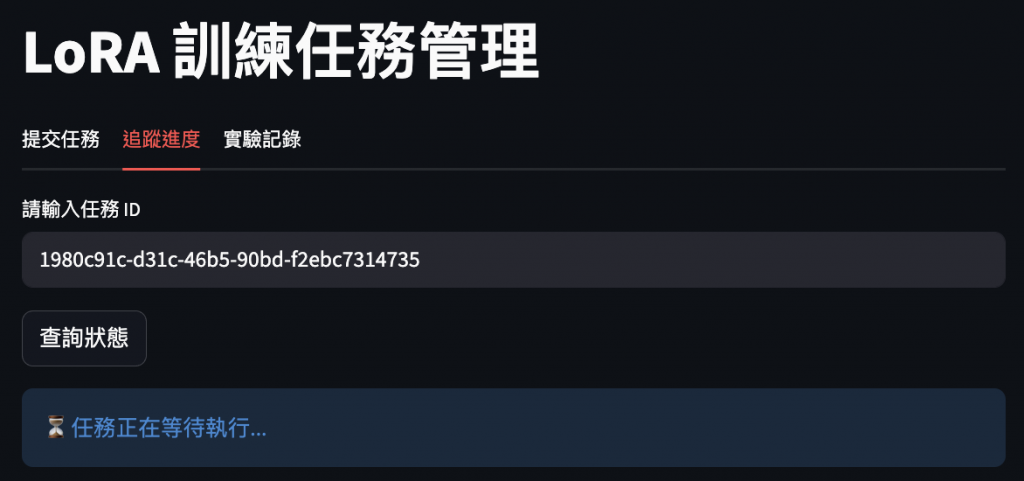
4️⃣ MLflow 實驗記錄頁面
:展示自動記錄的超參數、指標曲線與模型檔案。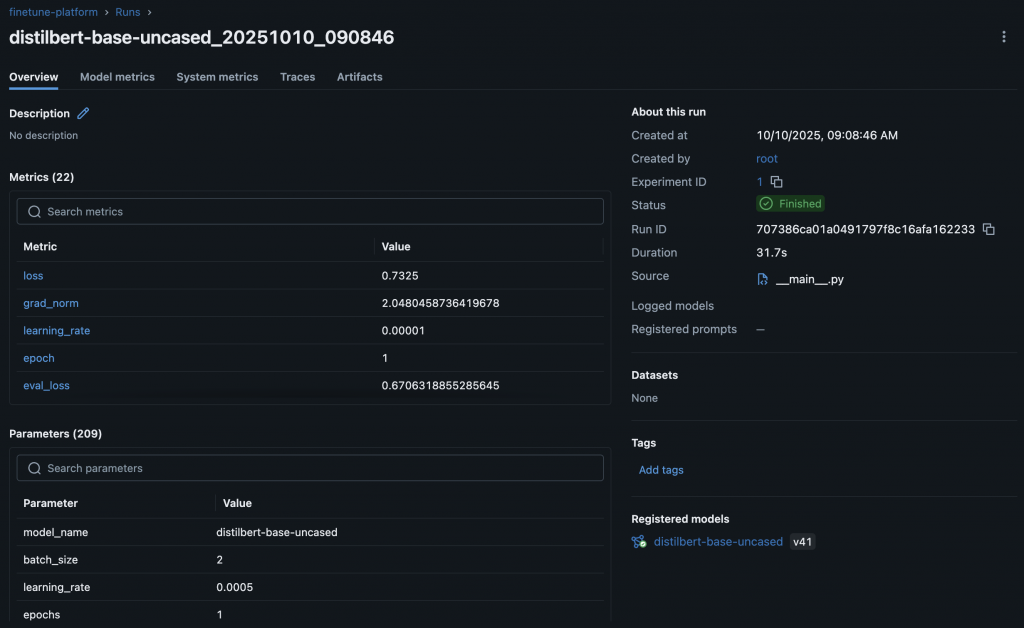
5️⃣ 模型卡與 Registry
:模型成功同步至 MLflow Model Registry,並生成對應的 JSON 卡片(這裡還沒整至 UI)。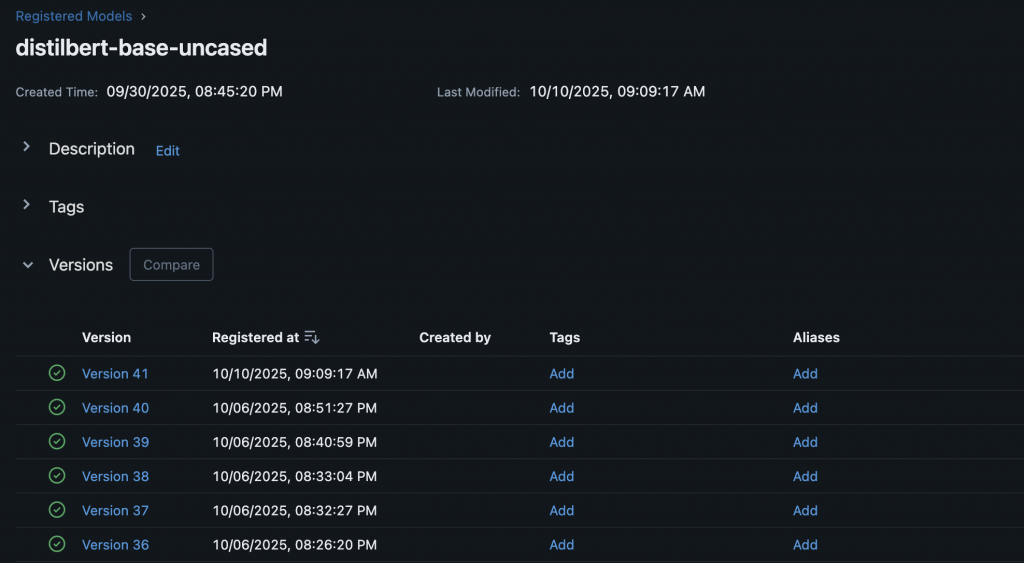

6️⃣ 推論與推薦結果
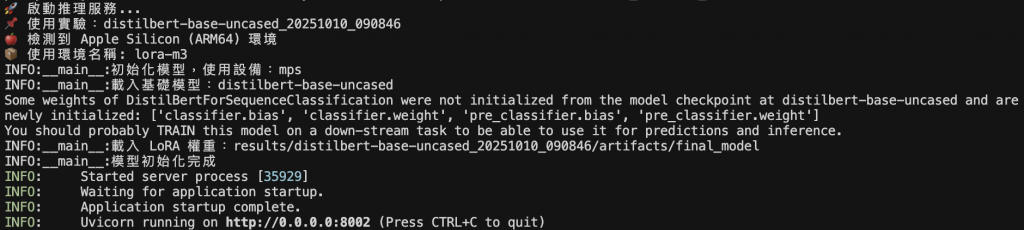
:接著可透過 make serve exp=<exp_id> 建立推論服務,並透過 make preidict text text='文字內容' 與模型溝通,因為資源關係這裡以輕量的分類模型示範。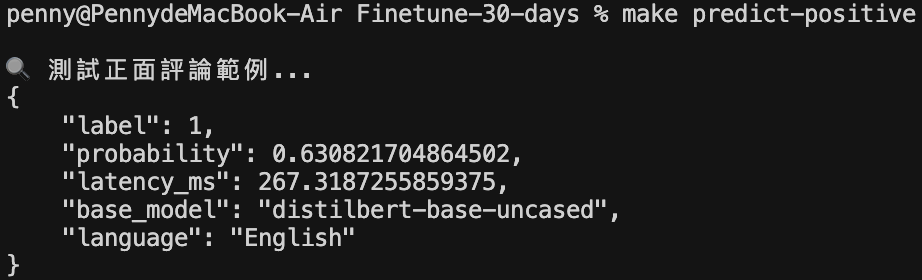
7️⃣ Grafana 監控儀表板
:另有 Grafana 頁面呈現任務成功/失敗計數、佇列長度、CPU/Mem 負載與任務耗時分佈。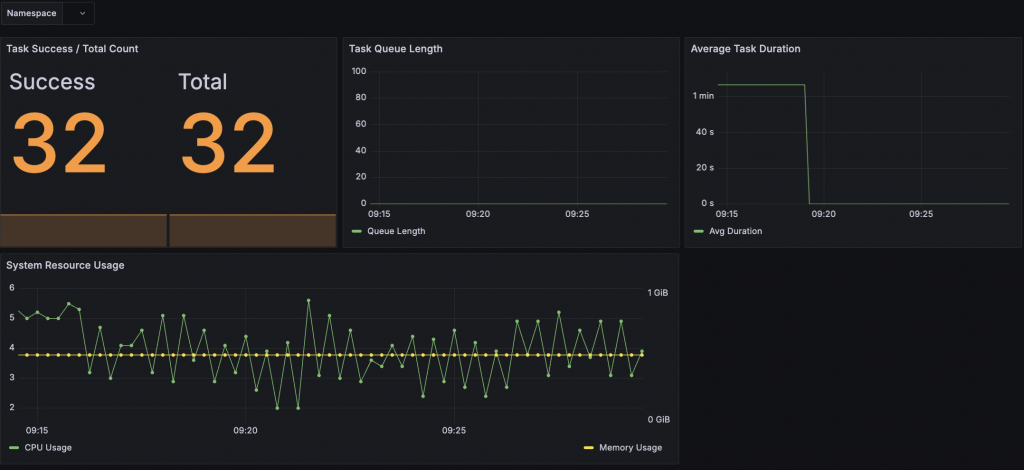
當這七個步驟串聯起來時,整個系統就能「自己說明自己正在運作」。
從登入開始,任務經由 API 提交至 Worker,MLflow 即時生成實驗記錄,
Model Registry 管理版本與階段,最終由 Grafana 呈現出任務吞吐與資源變化。
每一層都有對應的觀測點:
Celery 管理佇列、MLflow 追蹤實驗、Registry 管理模型、
Prometheus 與 Grafana 監控負載。
這不只是「能跑通」的系統,而是一個能解釋自己的 AI 平台——
開發者、使用者與維運者都能從同一條鏈路上看到自己的責任點與狀態。
這一步,代表整個 Finetune 平台第一次完整呼吸。


 iThome鐵人賽
iThome鐵人賽