完整程式碼可在 GitHub 專案中找到:Finetune-30-days-demo / day-26
在前 25 天,我們的系統已能從訓練到部署完整運作,但如果某個 Worker 異常、任務延遲或 Redis 塞滿,開發者往往要「猜」問題在哪。
要讓平台真正具備「產品級穩定性」,就必須能 觀測 — 讓系統的健康狀態被看見、被量化、被預警。
今天,我們導入 Prometheus + Grafana,建立平台的可觀測性基礎,讓系統從「能跑起來」進化成「能自己報警」。
| 功能面向 | MLflow Tracking | Prometheus + Grafana |
|---|---|---|
| 目的 | 追蹤訓練實驗與模型表現 | 監控系統運作與任務狀態 |
| 資料性質 | 離線紀錄(每次實驗結束) | 即時監控(每幾秒抓取一次) |
| 資料儲存 | SQLite / S3 | 時序資料庫(TSDB) |
| 典型指標 | accuracy、loss、lr | CPU、Mem、queue length、任務成功率 |
| 呈現介面 | MLflow UI | Grafana Dashboard |
| 決策用途 | 模型好不好 | 系統穩不穩 |
兩者並行使用:
FastAPI / Worker → /metrics (Prometheus Client)
│
▼
Prometheus (pull metrics every 5s)
│
▼
Grafana (visualize dashboards)
Exporter 會定期輸出最新指標,Prometheus 抓取後儲存成時序資料,Grafana 再將結果轉為圖表與趨勢。
這樣你不需 SSH 登伺服器看 log,就能知道整個平台的運行健康度。
| 指標名稱 | 說明 | 主要用途 |
|---|---|---|
| Task Success / Total Count | 累計成功任務(task_success_total)與總任務數(task_success_total + task_failure_total) |
評估任務成功率與可靠性 |
| Task Queue Length | 目前待處理任務數(task_queue_length) |
反映 Celery/Redis 佇列壅塞情況 |
| Average Task Duration | 由 task_duration_seconds 直方圖計算的平均耗時 |
分析任務效能與延遲趨勢 |
| System Resource Usage | CPU 百分比(system_cpu_percent)、記憶體用量(system_memory_usage_gigabytes) |
評估 API / Worker 負載 |
這四類指標覆蓋了 任務層(Task) 與 系統層(System) 的觀測需求。
它們共同回答:「任務順不順?系統撐不撐?」
record_task_success() / record_task_failure() 累積到 Redis。/metrics 端點被 Prometheus 抓取時,會讀取 Redis 中的統計值。task_queue_length 則直接使用 Redis 的 LLEN,即時反映排隊情況。這樣能在任務量激增時即時看到 queue 堆積,及早調整 Worker 數量。
每次任務完成時,系統會記錄其耗時(秒)並更新直方圖 task_duration_seconds。
Grafana 查詢:
rate(task_duration_seconds_sum[5m]) / rate(task_duration_seconds_count[5m])
即「過去 5 分鐘內的耗時增量 ÷ 任務數增量」= 平均任務耗時。
這樣可平滑掉突發尖峰,只要有新任務完成,數據就會更新。
psutil.cpu_percent(interval=1),直接輸出 0–100%。psutil.Process().memory_info().rss / 1024**3,轉為 GB。max without(pid) 聚合,顯示整體使用情況。這讓你能清楚觀察 API/Worker 是否出現過載、記憶體外洩等現象。
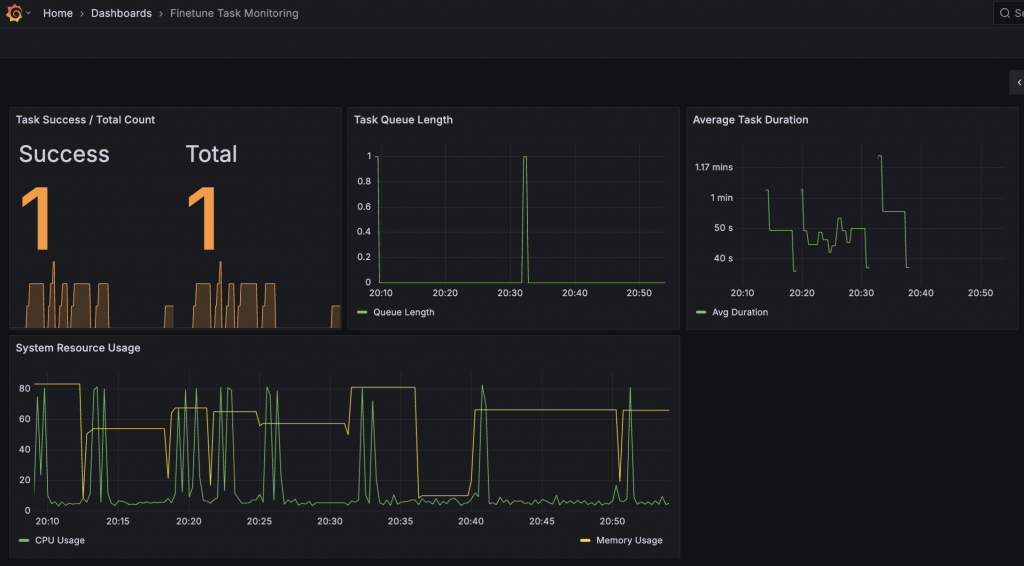
我建立了一份「最小監控儀表板」,以 3–5 張圖呈現系統核心指標,聚焦在任務執行狀態與系統資源負載:
| 圖表名稱 | 查詢公式 | 監控目的 |
|---|---|---|
| 任務成功 / 失敗計數 | task_success_total、task_success_total + task_failure_total |
觀察任務執行結果是否穩定、有無異常 spike |
| 任務佇列長度 | task_queue_length |
即時反映 Celery/Redis 是否壅塞 |
| 平均任務耗時 | rate(task_duration_seconds_sum[5m]) / rate(task_duration_seconds_count[5m]) |
監控任務效能與延遲變化趨勢 |
| CPU 使用率 | max without(pid)(system_cpu_percent) |
評估系統整體負載 |
| 記憶體使用量 (GB) | max without(pid)(system_memory_usage_gigabytes) |
追蹤 API / Worker 的記憶體健康狀態 |
當「任務失敗數」上升且「佇列長度」持續攀升、同時「CPU 使用率」偏高,
通常代表 Worker 過載或 Redis 延遲。
反之,如果成功數穩定上升且平均耗時下降,代表系統效能逐步優化。
導入 Prometheus + Grafana 之後,我們終於能回答:
「系統現在健康嗎?」、「任務在塞哪裡?」、「是否該擴容?」
MLflow 管實驗,Prometheus 管生命體徵,兩者一靜一動,共同構成平台的「腦」與「神經」。
從今天起,我們不再只關注模型效能,而是 全面掌握平台健康狀態,
讓整個微調平台正式具備 自我觀測與診斷能力(self-observability)。
📎 AI 協作記錄:今日開發指令
# Day 26: 可觀測性實作
請在專案中完成以下任務:
1. 建立 src/metrics/exporter.py
- 使用 prometheus_client
- 指標包含:
- task_success_total, task_failure_total, task_queue_length
- task_duration_seconds (Histogram)
- system_cpu_percent, system_memory_usage_gigabytes
- 新增 /metrics 端點供 Prometheus 抓取
2. 整合 FastAPI
- 在 main.py 中引入 exporter
- 確保 /metrics 可被 Prometheus 收集
3. 建立 grafana/dashboard.json
- 含 Task Success Rate、Queue Length、Average Duration、System Usage 四張圖
- 使用 rate() 與 max without(pid) 聚合查詢
4. 測試驗證
- curl localhost:8000/metrics
- 驗證 Prometheus 指標更新
- 匯入 dashboard.json 到 Grafana 驗證可視化結果


 iThome鐵人賽
iThome鐵人賽