前情提要:從 JSON 到 SQLite
在 Day 8,我們完成了 Notion Pipeline,可以一次抓取多個 Database → Page → Block,並輸出成乾淨 JSON。
在 Day 9,我們設計了 SQLite Schema,並繪製了 ERD,把 Notion 的三層結構整理成關聯式資料表:
notion_databases
├── database_id (PK) # Notion Database UUID,唯一識別碼
├── database_name # Database 名稱(例如 PythonBasicNotes)
├── category # 自訂分類:Life / Work / Learning
├── created_time # Database 建立時間(ISO 8601 格式)
└── last_edited_time # Database 最後編輯時間
│
│ 1:N (一個 Database 對應多個 Page)
▼
notion_pages
├── page_id (PK) # Notion Page UUID,唯一識別碼
├── page_name # Page 標題(通常是 Database 的 title 欄位)
├── database_id (FK) # 所屬的 Database ID(外鍵)
├── created_time # Page 建立時間
└── last_edited_time # Page 最後編輯時間
│
│ 1:N (一個 Page 對應多個 Block)
▼
notion_blocks
├── block_id (PK) # Notion Block UUID,唯一識別碼
├── page_id (FK) # 所屬的 Page ID(外鍵)
├── order_index # Block 在 Page 裡的順序(流水號,從 0 開始)
├── block_type # Block 類型(paragraph, heading, code...)
├── block_text # Block 主要文字內容(如段落、程式碼內容)
├── code_language # 程式碼區塊語言(僅 type=code 時有值)
├── created_time # Block 建立時間
└── last_edited_time # Block 最後編輯時間
問題回顧:JSON 與 Schema 的落差
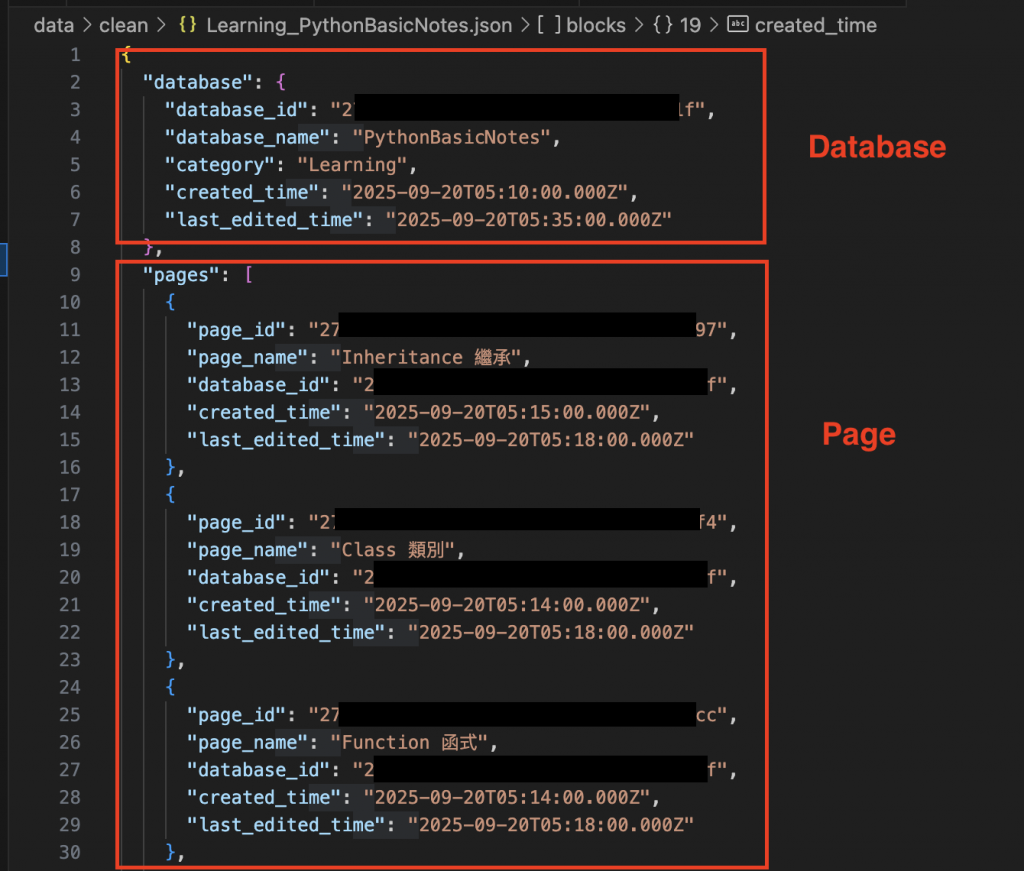
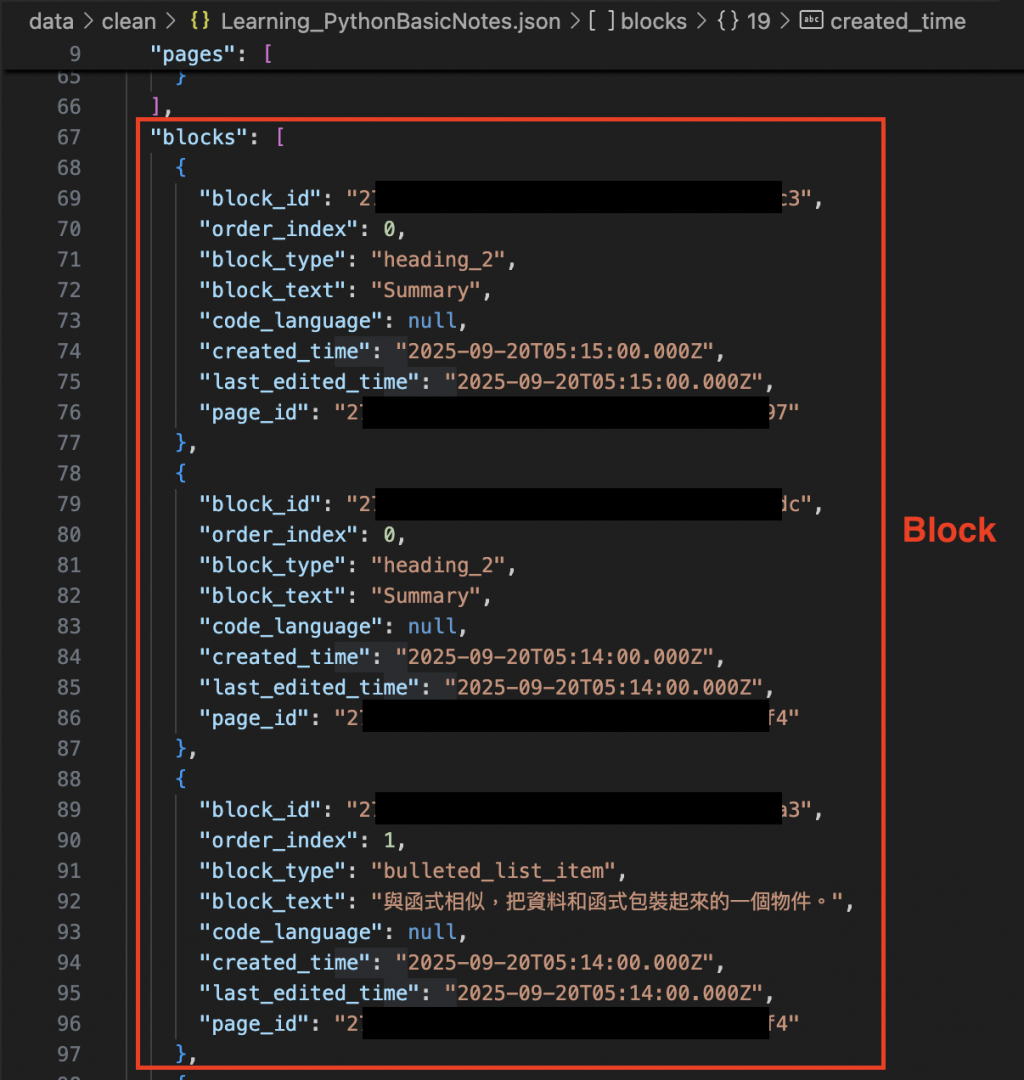
在 Day 8 的 Pipeline,我們得到的 JSON 格式大致如下:
{
"db_id": "xxx",
"db_name": "Learning_PythonBasicNotes",
"page_id": "ooo",
"blocks": [
{ "type": "heading_2", "text": "Summary" },
{ "type": "bulleted_list_item", "text": "類別就像是物件的設計藍圖..." }
]
}
如果對應到 SQLite Schema 就會發現 JSON 還缺少了一些 Columns:
| Table Name | 缺少欄位 |
|---|---|
notion_databases |
category、created_time、last_edited_time |
notion_pages |
page_name、created_time、last_edited_time |
notion_blocks |
block_id、order_index、code_language、created_time、last_edited_time |
因此今天的實作目標是調整 Pipeline 輸出 JSON,補齊 Schema 需要的欄位。
category 欄位(例如:Learning、Life…),會寫入 notion_databases.category。databases:
- id: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
name: "Learning_PythonBasicNotes"
category: "Learning"
- id: "yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy"
name: "Life_BusanTravelPlan"
category: "Life"
fetch_learning_database.py ➜ fetch_database.py
fetch_learning_page.py ➜ fetch_page.py
parse_learning_blocks.py ➜ parse_blocks.py
run_pipeline.py ➜ run_notion_pipeline.py
/databases/{id} 取 created_time/last_edited_time,DB 名稱以 YAML 的 name 為主。/databases/{id}/query 的每筆 row 中,找第一個 title property 做為 page_name,同時取 created_time/last_edited_time。/blocks/{page_id}/children 遞迴抓子層;每個 block 帶 block_id/created_time/last_edited_time,交給 parser 解析 block_text 與 code_language;外層用 enumerate 產生 order_index。
- 讀取 Database meta(含
created_time、last_edited_time)。- 抓取 rows(Page),補
page_name、created_time、last_edited_time。
import os, requests
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv("NOTION_TOKEN")
HEADERS = {
"Authorization": f"Bearer {TOKEN}",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json",
}
BASE = "https://api.notion.com/v1"
def join_text(arr):
"""將 rich_text / title 陣列合併成單一字串"""
if not arr:
return ""
return "".join([t.get("plain_text", "") for t in arr]).strip()
def fetch_database_meta(database_id: str) -> dict:
"""
取得 Database 本體的中繼資料(含 created_time / last_edited_time / 名稱)
"""
url = f"{BASE}/databases/{database_id}"
res = requests.get(url, headers=HEADERS)
res.raise_for_status()
data = res.json()
# 嘗試抓 database 名稱(有些 DB 會把名稱放在 title 陣列)
db_name = join_text(data.get("title", [])) or data.get("id")
return {
"database_id": data["id"].replace("-", ""),
"database_name": db_name,
"created_time": data.get("created_time"),
"last_edited_time": data.get("last_edited_time"),
"raw": data, # 保留原始,方便除錯(寫檔時可忽略)
}
def query_database_all(database_id: str, page_size: int = 100) -> list:
"""
查詢 Database 的 rows(每筆 row 實際上是一個 Page)
並補上 page_name / created_time / last_edited_time
"""
url = f"{BASE}/databases/{database_id}/query"
payload = {"page_size": page_size}
results = []
while True:
res = requests.post(url, headers=HEADERS, json=payload)
res.raise_for_status()
data = res.json()
for row in data.get("results", []):
page_id = row["id"]
created_time = row.get("created_time")
last_edited_time = row.get("last_edited_time")
# 找出第一個 title 欄位當作 page_name
page_name = None
for prop in row["properties"].values():
if prop["type"] == "title":
page_name = join_text(prop.get("title", []))
break
results.append({
"id": page_id,
"page_id": page_id, # 方便下游語意一致
"page_name": page_name,
"created_time": created_time,
"last_edited_time": last_edited_time,
"properties": row["properties"], # 保留原始屬性
})
if not data.get("has_more"):
break
payload["start_cursor"] = data["next_cursor"]
return results
- 遞迴抓 Page blocks,保留
block_id/created_time/last_edited_time。
import os, requests
from dotenv import load_dotenv
load_dotenv()
TOKEN = os.getenv("NOTION_TOKEN")
HEADERS = {
"Authorization": f"Bearer {TOKEN}",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json",
}
BASE = "https://api.notion.com/v1"
def fetch_block_children(block_id: str, page_size: int = 100):
"""抓取某個 block 的 children(單層)"""
url = f"{BASE}/blocks/{block_id}/children?page_size={page_size}"
res = requests.get(url, headers=HEADERS)
res.raise_for_status()
return res.json().get("results", [])
def fetch_page_blocks(page_id: str) -> list:
"""
遞迴抓取整個 Page 下的所有 blocks,
並保留 block_id / created_time / last_edited_time / type / 原始資料
"""
all_blocks = []
def _walk(block_id: str):
children = fetch_block_children(block_id)
for b in children:
btype = b.get("type")
all_blocks.append({
"block_id": b.get("id"),
"type": btype,
"created_time": b.get("created_time"),
"last_edited_time": b.get("last_edited_time"),
"raw": b, # 先保留原始,parse 再抽取 text / code_language
})
if b.get("has_children"):
_walk(b.get("id"))
# Page 本身也是一個 block 容器,page_id 可以直接拿來當 root block
_walk(page_id)
return all_blocks
- 解析 block,補
order_index/code_language。
def join_text(arr):
if not arr:
return ""
return "".join([t.get("plain_text", "") for t in arr]).strip()
def parse_block(block: dict, order_index: int) -> dict:
"""
將 raw block 解析為一致格式:
- block_id / type / block_text / code_language / created_time / last_edited_time / order_index
"""
raw = block.get("raw", {})
btype = block.get("type", raw.get("type"))
text = ""
code_language = None
# 依型別抽取內容
if btype in ("paragraph", "heading_1", "heading_2", "heading_3",
"bulleted_list_item", "numbered_list_item", "quote",
"to_do", "toggle", "callout"):
content = raw.get(btype, {})
text = join_text(content.get("rich_text", []))
# to_do 可依需要加上 checked 狀態
if btype == "to_do":
checked = content.get("checked", False)
# 也可附加到 text 或另開欄位,這裡先不動
elif btype == "code":
content = raw.get("code", {})
text = join_text(content.get("rich_text", []))
code_language = content.get("language")
else:
# 其他型別(divider、image、video、child_database…)
# 先以占位文字或空字串處理,避免中斷
text = ""
return {
"block_id": block.get("block_id"),
"order_index": order_index,
"block_type": btype,
"block_text": text,
"code_language": code_language,
"created_time": block.get("created_time"),
"last_edited_time": block.get("last_edited_time"),
}
- 串接所有模組,依 DB 輸出 JSON。
import os, json, yaml
from dotenv import load_dotenv
from fetch_database import fetch_database_meta, query_database_all
from fetch_page import fetch_page_blocks
from parse_blocks import parse_block
load_dotenv()
def run_pipeline(config_path="config/databases.yml"):
with open(config_path, "r", encoding="utf-8") as f:
config = yaml.safe_load(f)
os.makedirs("data/clean", exist_ok=True)
for db in config["databases"]:
db_id = db["id"]
db_name = db["name"]
category = db.get("category")
print(f"=== 處理 Database: {db_name} ===")
# A) 讀取 Database 中繼資料
meta = fetch_database_meta(db_id) # 含 database_name / created_time / last_edited_time
# 以 YAML 中的 name 蓋過 meta 的 title(可自行選擇是否覆蓋)
meta["database_name"] = db_name
meta["category"] = category
# B) 查詢 rows → Page 清單(含 page_name / created_time / last_edited_time)
rows = query_database_all(db_id)
print(f" Rows: {len(rows)}")
db_pages = []
db_blocks = []
for row in rows:
page_id = row["page_id"]
page_name = row.get("page_name")
page_created = row.get("created_time")
page_edited = row.get("last_edited_time")
# C) 抓該 Page 的 blocks(含 block_id / created / edited)
blocks_raw = fetch_page_blocks(page_id)
# D) 解析 block,補上 order_index
parsed_blocks = [
parse_block(b, idx) for idx, b in enumerate(blocks_raw)
]
# 收集頁面與區塊
db_pages.append({
"page_id": page_id,
"page_name": page_name,
"database_id": meta["database_id"], # 注意:已去掉 "-"
"created_time": page_created,
"last_edited_time": page_edited,
})
for pb in parsed_blocks:
# 附上 page_id 以便後續寫入 notion_blocks
pb["page_id"] = page_id
db_blocks.append(pb)
# E) 以 db_name 分檔輸出
safe_name = category + "_" + db_name.replace(" ", "_")
out_path = f"data/clean/{safe_name}.json"
payload = {
"database": {
"database_id": meta["database_id"],
"database_name": meta["database_name"],
"category": meta.get("category"),
"created_time": meta.get("created_time"),
"last_edited_time": meta.get("last_edited_time"),
},
"pages": db_pages,
"blocks": db_blocks,
}
with open(out_path, "w", encoding="utf-8") as f:
json.dump(payload, f, ensure_ascii=False, indent=2)
print(f"Saved results for {db_name} → {out_path}")
if __name__ == "__main__":
run_pipeline()
今天我們讓 Notion JSON 與 Table Schema 對齊:
Pipeline 輸出的 JSON 不再只是「筆記內容」,而是完整帶上 Database、Page、Block 的中繼資訊,已經能直接落地到關聯式資料庫使用。這代表未來不論是查詢程式碼段落、統計學習進度,甚至做增量更新,都具備了基礎資料。
在 Day 11,我們將實作把這些 JSON 匯入 SQLite,並示範如何用 SQL 查詢與分析 Notion 筆記。這將是從「抓資料」到「用資料」的一個重要轉折。


 iThome鐵人賽
iThome鐵人賽