你有沒有過這種經驗:做菜時明明是照食譜放材料,但最後味道卻總是不盡人意?
(時常下廚的我非常有感觸 = =)
而你知道其實在訓練神經網路時也可能常遇到類似的問題嗎?
網路在學習的過程中,因為每一層的輸入數據分布不斷改變,
就可能導致模型時快時慢、難以收斂,甚至學到一半「卡住」。
這就是所謂的 內部協變偏移(Internal Covariate Shift) 問題。
而為了改善這種「不穩定的味道」,有研究者提出了一個很實用的小秘訣
在今天的學習中,我們就會專注介紹這個可以讓
模型更加穩定的小工具。
Batch Normalization(簡稱 BN)是一種深度學習中常用的技巧,
它的主要目的就是:
在神經網路的每一層中,對小批次(mini-batch)的輸入數據進行標準化處理。
簡單來說,就是把這批輸入調整成:
這樣做的好處是,輸入到每一層神經元的數據比較穩定,
將數值收斂在0-1中,相對於原本的大數值一定是比較好處理的,
也不會因為上一層權重更新太大而「忽冷忽熱」。
BN 也不是單純地固定標準化,它還加入了可學習的縮放(scale)參數 γ 和
位移(shift)參數 β,讓網路仍然能根據需求調整分布,
不會限制模型的表現力。
在訓練深度神經網路時,每一層的輸入分布都會隨著上一層參數的更新而不斷改變。
這會帶來兩個麻煩:
數值在傳遞過程中可能變得過小或過大,導致學習困難。
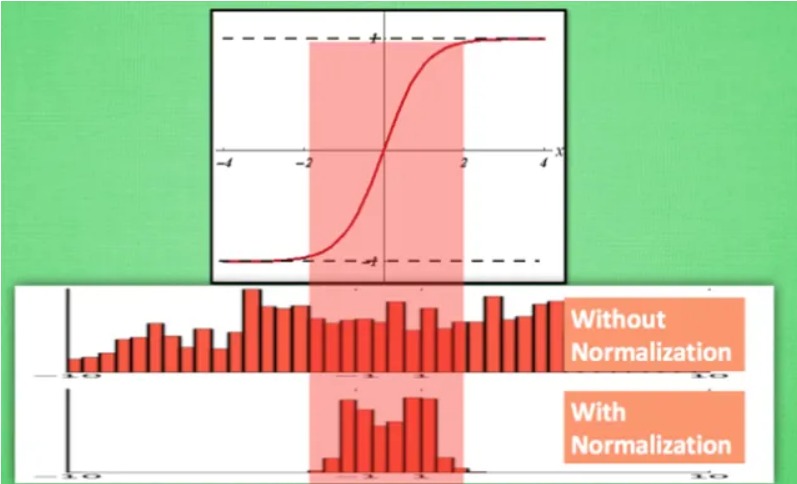
由上圖也可以看到,沒有使用 Normalization 的數據則是在通過激活函數後,
大部分值都到達了飽和區,容易導致梯度消失的問題
因為每次輸入分布都變動,模型需要不斷「重新適應」。
而 BN 的想法就很直觀:
「既然輸入分布不穩定,那我就乾脆把它們統一「規範化」一下,讓每一層輸入都比較穩定。」
Batch Normalization 的想法其實很簡單:
在每一層的輸入進到激活(啟動)函數之前,先做一次「規格化」。
流程大致是:
這樣一來,每層的輸入就比較「乾淨」,不會因為前面權重更新太劇烈而導致整個分布大亂。
在神經網路的訓練過程中,我們希望每一層的輸入分布能保持穩定,
而 Batch Normalization 就是透過計算平均值與標準差,把資料做正規化。
而問題在於,這個平均值與標準差要怎麼算?
如果我們用整個資料集去算,雖然數字最精準,
但每次計算都要讀取整批資料,效率非常低。
更麻煩的是,因為每次結果都固定,訓練就會失去隨機性,
模型的學習反而容易變死板,缺乏泛化能力。
如果反過來只用單筆資料來算,狀況就更糟了。
單筆資料的平均值就是它自己,標準差會變成零,根本沒有辦法完成標準化。
而且單一數據本來就太過極端,這樣做會讓模型的輸入非常不穩定,甚至無法收斂。
於是,小批次資料就成為了最適合的選擇。
它不像整個資料集那麼龐大,計算上效率高得多;
與此同時,它也不像單筆資料那樣極端,而是能夠在
每一批裡提供一個合理的平均值與標準差,讓標準化有意義。
更重要的是,每一個小批次的組成都不一樣,這樣模型在訓練過程中
會不斷面對不同的資料分布,逐步學會在各種情況下都能保持穩定。
這樣的隨機性,反而成為一種助力,幫助模型更具泛化能力。
所以為什麼是選擇小部分的資料,用一句話總結就是:
相對於一筆資料跟全部資料,綜合起來小批次資料是最有CP值的選擇。
在使用 Batch Normalization 後,我們就可以減少剛剛上述所講到的問題,
與此同時,他也會帶來以下的好處:
因為我們讓每層輸入變的比較穩定了,因此學習率可以設定得更大,收斂速度也更快。
將輸入規範化到類似於標準常態分布的數值,會使得數值更穩定。
在每個 batch 都進行「隨機的正規化」,等於有點像一種正規化效果,可以減少過擬合。
不需要再非常小心地挑選初始化方法,BN 就會幫忙把數值拉回穩定範圍。
Batch Normalization 就像是幫神經網路「校正味道」的小秘訣,
透過對每批資料做正規化,讓訓練過程更快、更穩定,也能減少過擬合。
幾乎所有現代的深度學習模型都離不開它。
https://medium.com/ching-i/batch-normalization-%E4%BB%8B%E7%B4%B9-135a24928f12
https://ithelp.ithome.com.tw/articles/10204106

