在過去的幾天,我們一步步認識了神經網路的基本組件,
並且在第7天時透過 MNIST 的手寫數字辨識體驗了第一個深度學習實作。
而在今天,我們要更進一步挑戰更貼近現實世界的影像資料集 - CIFAR-10。
這是一個常見於研究與教學的影像分類資料集,
它比 MNIST 更複雜,因為資料不是黑白的數字,而是彩色的真實物件。
我們將會用 Keras 建立一個簡單的卷積神經網路(CNN),體驗影像分類的第一步。
CIFAR-10 是由加拿大多倫多大學機器學習研究所(CIFAR)提供的一個公開影像資料集。
它包含了 60,000 張 32x32 彩色圖片,分為 10 個類別,每個類別有 6,000 張圖片。
這些類別包含了日常生活常見的東西,例如:飛機(airplane)、汽車(automobile)、
鳥(bird)、貓(cat)、鹿(deer)、狗(dog)等等 ,如下圖:

相較於 MNIST 的手寫數字,CIFAR-10 的挑戰更高,
因為資料是彩色的(RGB 三通道),不像 MNIST 是單色灰階。
圖片內容相較文字更複雜,有背景、形狀差異,甚至角度也會有不同。
除此之外,辨識的對象從單純數字變成了生活中會見到的物體,
也是一個用膝蓋想也清楚的難度躍升。
深度學習的第一步當然就是載入資料了,我們的程式碼如下:
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
# 載入 CIFAR-10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
print("訓練資料形狀:", x_train.shape)
print("測試資料形狀:", x_test.shape)
在這段程式碼中,我們會得到 50,000 張訓練圖片 與 10,000 張測試圖片。
每張圖片的尺寸是 (32, 32, 3),
也就是高 32、寬 32、3 個顏色通道(RGB)。
對於資料前處理部分,我們先看程式碼,後解釋:
from tensorflow.keras.utils import to_categorical
# 標籤轉換成 one-hot encoding
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 正規化圖片像素值到 [0,1]
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
在這段程式碼中,我們做了兩件事:
第一個就是我們講過好幾次的「one-hot encoding」,
就是讓標籤變成像 [0,0,0,1,0,0,0,0,0,0] 的形式,方便模型處理分類問題。
詳細解釋也可以去翻閱我之前的文章,這裡省略一萬字。
再者,我們一樣對數值進行「正規化」,避免數值太過分散導致不好訓練。
這也是我們每次執行實作都會進行的前置作業。
接著就是建立模型啦!!!
話不多說,上程式碼:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
model = Sequential([model = models.Sequential([
layers.Conv2D(32, (3, 3), padding='same', input_shape=(32, 32, 3)),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), padding='same'),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), padding='same'),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Flatten(),
layers.Dense(64),
layers.BatchNormalization(),
layers.Activation('relu'),
layers.Dense(10, activation='softmax')
])
Conv2D(32, (3,3), activation='relu', input_shape=(32,32,3)),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
上面的程式碼就是一個簡單的卷積神經網路(CNN)
這裡的資訊比較多一點,就稍微解釋一下:
在這一層中,我們使用 32 個「濾鏡」去掃描輸入的彩色圖片。
每個濾鏡的大小是 3x3,用來捕捉圖片最基本的特徵,例如邊緣、線條或顏色的變化。
而在這一層中也設定了 nput_shape=(32, 32, 3),代表輸入的影像大小是 32x32 ,
且有三個顏色通道 (RGB)。
激活函數則是使用 relu
(在「神經元大解密」那篇文章有詳細介紹過,可點選下方連結前往),
神經元大解密:
https://ithelp.ithome.com.tw/articles/10383027
在這一層,我們對卷積層的輸出進行「正規化」,也就是讓數值分布維持在比較穩定的範圍。
這個是我們前一篇文章就討論過的概念,這樣做的好處就是
能加快訓練速度,並且減少梯度消失或梯度爆炸的問題。
(文章連結: )
這一層則會將特徵圖縮小。具體做法是取 2x2 的小區塊,
並從中選出一個代表值 (最大值)。
這樣能保留主要特徵,同時降低運算量,讓後續的計算更有效率。
接下來再加入一個卷積層,這次使用 64 個濾鏡。
這時候模型已經能從圖片中抽取更進一步的特徵,
例如形狀或紋理,而不只是單純的顏色變化。
我們再堆疊一層卷積層,依舊使用 64 個濾鏡。
這時候模型會更聚焦於影像中的細節與更高階的模式,
例如某些物體的局部結構。
這一步將 2D 的特徵圖「攤平」成一個一維的向量,
方便送入後面的全連接層(Dense 層)。
這就像是把圖片拆解後的一堆特徵,全部排成一列。
這是一個全連接層,擁有 64 個神經元。
它的工作是將前面抽取到的特徵進行組合,
進一步學習圖片中更抽象的表示方式。
激活函數同樣使用 ReLU,能有效提升模型的表現能力。
最後是輸出層,擁有 10 個神經元,分別對應 CIFAR-10 資料集中 10 個類別。
激活函數則是 Softmax,會將輸出的數值轉換成機率分布,
讓我們可以知道圖片屬於每一個類別的可能性。
以上的結構就是一個最基本的 CNN 架構,能夠處理彩色影像並做分類,
我們之後也會繼續做相關的內容創作,還請大家期待。
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
參數解釋:
Adam 是一種自動調整學習率的最佳化方法,通常收斂快且表現穩定。
分類任務常用的損失函數,會量化模型預測機率與真實標籤差多少。
訓練/驗證時會顯示正確率(accuracy)作為衡量指標。
history = model.fit(x_train, y_train,
epochs=50,
batch_size=64,
validation_split=0.2,
verbose=2)
接著在這裡就是正式開始訓練了,
我們分別要設定訓練次數(epochs)、訓練數量(batch_size)、
驗證集比率(validation_split),
以及訓練過程的進度資訊(verbose)。
以上四個也分別代表從上到下的參數。
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print("測試集損失:", test_loss)
print("測試集正確率:", test_acc)
最後我們用測試資料來檢驗模型的表現,
會使用到前面介紹過的「loss」以及「accuracy」,
分別代表損失值(越低越好)以及正確率(越高越好)。
其實原本只有到上一步就結束了,
但我想到似乎前幾天才做過可視化的相關介紹,不如也融入到今天的內容中,
於是乎我新增了以下程式碼:
# 繪製 Loss 與 Accuracy 曲線
plt.figure(figsize=(12, 5))
# Loss 曲線
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='訓練 Loss')
plt.plot(history.history['val_loss'], label='驗證 Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss 曲線')
plt.legend()
# Accuracy 曲線
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='訓練 Accuracy')
plt.plot(history.history['val_accuracy'], label='驗證 Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Accuracy 曲線')
plt.legend()
plt.show()
最後最後,我們就來看成果吧:
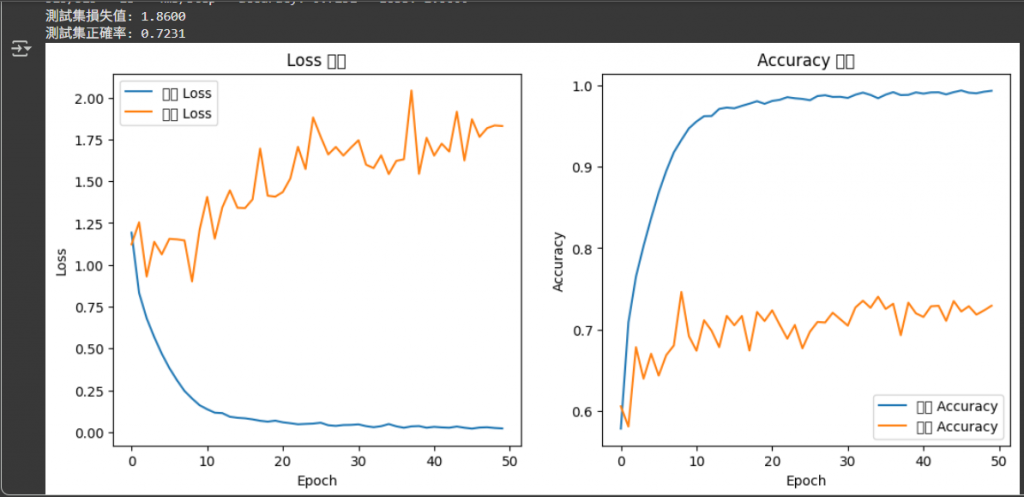
可以看到,由於是訓練較複雜的模型,我們的準確率只有約72%,
算是還有很大的進步空間。
在參考其他的資訊後,我認為還有幾個可以加入實作的地方:
Dropout 是一種常見的正則化方法,用來減少過擬合(overfitting)。
它的做法是在訓練過程中,隨機「關閉」部分神經元,讓網路不能過度依賴某些特定的特徵。
這樣的隨機屏蔽會迫使模型學習到更普遍、更穩健的特徵,而不是只記住訓練資料。
資料增強的目的是「讓訓練資料變多、變多樣化」,
而且這些資料是透過對原始圖片進行合理變形而來的。
在 CIFAR-10 中,雖然原始有 5 萬張訓練圖片,但對於深度學習模型來說仍然可能不足。
藉由隨機旋轉、平移、翻轉、亮度或對比度調整,
我們能模擬不同的攝影條件或角度,讓模型學會更強的辨識能力。
這些我查閱到的內容似乎可以幫助我的模型訓練得更好,但這篇篇幅炸了,
所以請容許我在下次實作時再加入這些東西,抱歉啦......
參考資料:
https://medium.com/@charlie910417/cifar10-classifer-using-vgg19-d948a4df6b20](http://)
https://medium.com/%E6%89%8B%E5%AF%AB%E7%AD%86%E8%A8%98/%E4%BD%BF%E7%94%A8-tensorflow-%E4%BA%86%E8%A7%A3-dropout-bf64a6785431
https://chtseng.wordpress.com/2017/11/11/data-augmentation-%E8%B3%87%E6%96%99%E5%A2%9E%E5%BC%B7/
https://yhhuang1966.blogspot.com/2018/04/keras-cifar-10.html

