想像一下,你正坐在智慧城市的控制中心,螢幕上顯示著來自十萬個感測器的即時數據——交通流量、空氣品質、電力消耗、水位監測。突然,系統檢測到某區域的異常震動模式,可能是地震前兆。在接下來的幾秒鐘內,系統必須分析數據、確認威脅、發出警報。
這就是現代IoT資料收集系統每天面對的挑戰:在海量數據中找到關鍵訊號,並在毫秒內做出反應。IoT系統看似只是「收集數據、存儲、分析」這麼簡單,但當設備數量從幾百個擴展到幾百萬個時,每個設計決策都會被無限放大。
一個錯誤的協議選擇可能導致網路癱瘓,一個不當的存儲策略可能讓成本失控,一個疏忽的安全漏洞可能讓整個城市的基礎設施暴露在風險中。今天,我們將深入探討如何設計一個能夠處理百萬級設備、每秒數百萬訊息的物聯網資料收集系統,從協議選擇到即時處理,從邊緣運算到異常檢測,一步步構建起現代物聯網的資料基礎設施。
讓我們以一個智慧工廠為例。這個工廠有 50,000 個感測器,監測著生產線上的每個環節——溫度、壓力、振動、電流、產品品質。每個感測器每秒產生 1-10 個數據點,意味著系統需要處理每秒 50 萬到 500 萬個數據點。
更重要的是,這些數據不只是要收集和存儲。系統需要在毫秒內檢測異常(比如設備即將故障的徵兆),需要提供即時的生產線狀態儀表板,需要支援歷史數據分析來優化生產流程,還需要確保即使網路中斷,關鍵的安全監控也能繼續運作。
數據收集能力
數據處理功能
數據存儲與查詢
效能要求
可用性要求
擴展性要求
安全性要求
成本限制
技術挑戰 1:協議選擇的權衡
物聯網設備的多樣性帶來了協議選擇的複雜性。工業設備可能使用 Modbus,智慧感測器偏好 MQTT,而資源受限的設備則需要 CoAP。錯誤的協議選擇會直接影響系統的效能、可靠性和電池壽命。
技術挑戰 2:海量數據的即時處理
當每秒有數百萬個數據點湧入時,傳統的請求-響應模式會徹底崩潰。系統需要採用串流處理架構,但如何在保證低延遲的同時處理複雜的業務邏輯,是一個巨大的挑戰。
技術挑戰 3:邊緣與雲端的協同
並非所有數據都需要上傳到雲端。邊緣運算可以減少延遲和頻寬成本,但如何設計邊緣與雲端的分工,如何處理斷網情況,如何保證數據一致性,都需要精心設計。
| 維度 | 純雲端架構 | 純邊緣架構 | 混合架構 |
|---|---|---|---|
| 核心特點 | 所有處理在雲端 | 所有處理在本地 | 分層處理模式 |
| 優勢 | 集中管理、無限擴展 | 低延遲、離線運作 | 平衡效能與成本 |
| 劣勢 | 高延遲、頻寬成本高 | 管理複雜、擴展受限 | 架構複雜度高 |
| 適用場景 | 非即時應用 | 關鍵任務系統 | 大規模物聯網 |
| 複雜度 | 低 | 中 | 高 |
| 成本 | 高(頻寬) | 高(硬體) | 中等 |
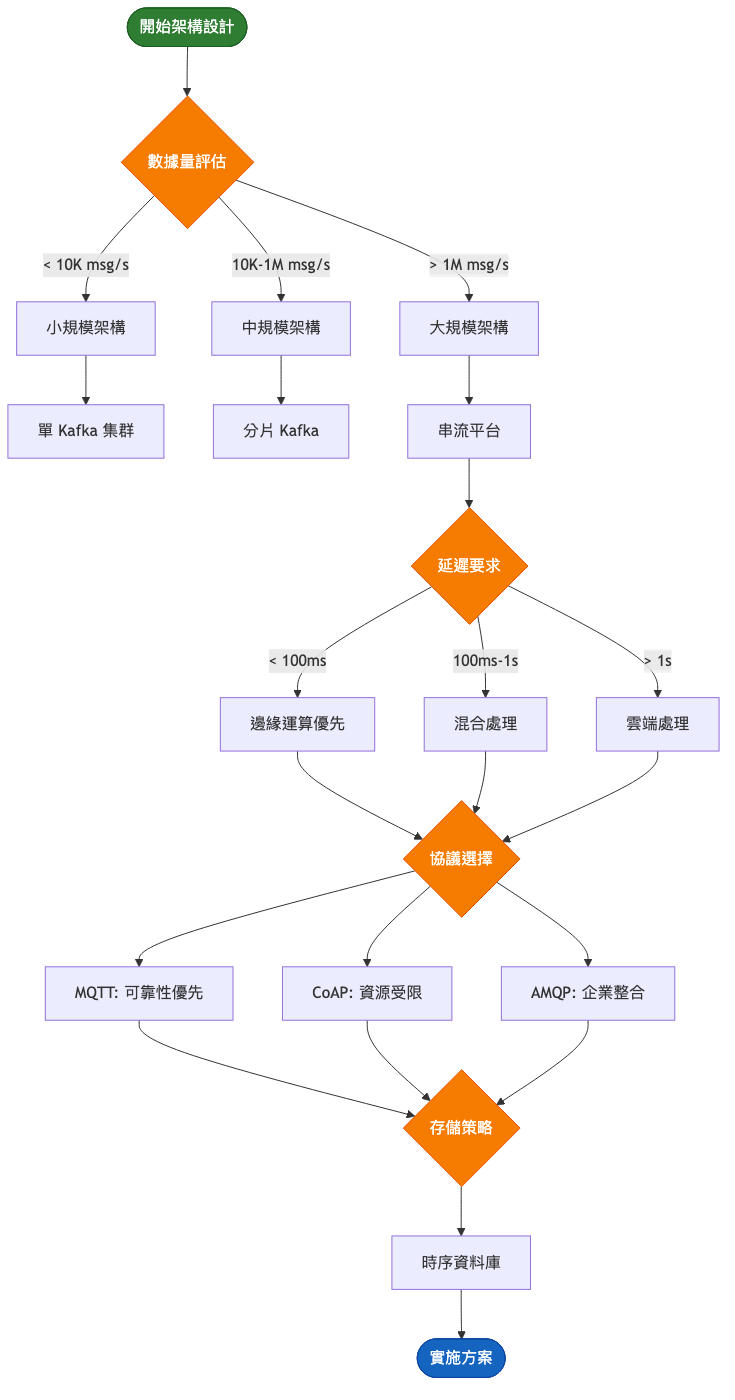
架構重點:
系統架構圖:
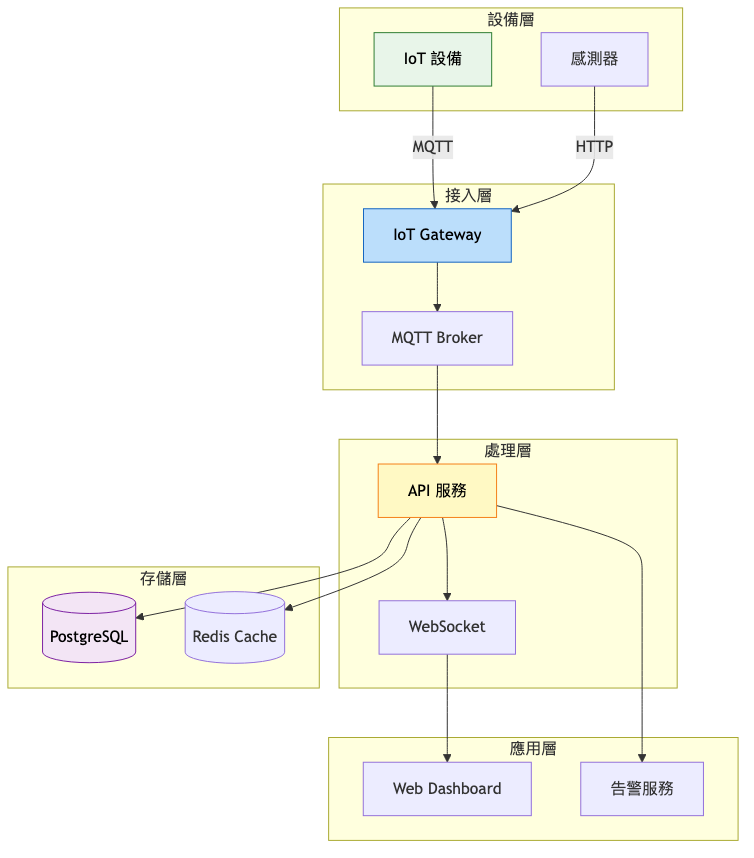
關鍵設計選擇:
架構重點:
系統架構圖:
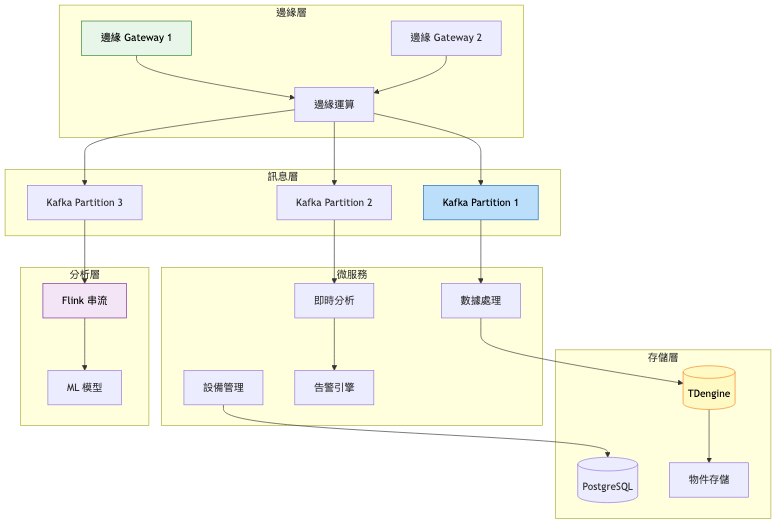
關鍵架構變更:
引入 Apache Kafka
邊緣運算層
時序資料庫遷移
預期效能提升對比表:
| 指標 | MVP 階段 | 成長期 | 改善幅度 |
|---|---|---|---|
| 吞吐量 | 1K msg/s | 100K msg/s | 100x |
| 延遲 | 1-5s | 100-500ms | 10x |
| 存儲成本 | $500/TB | $100/TB | 5x |
| 可用性 | 99.5% | 99.9% | 4x |
架構重點:
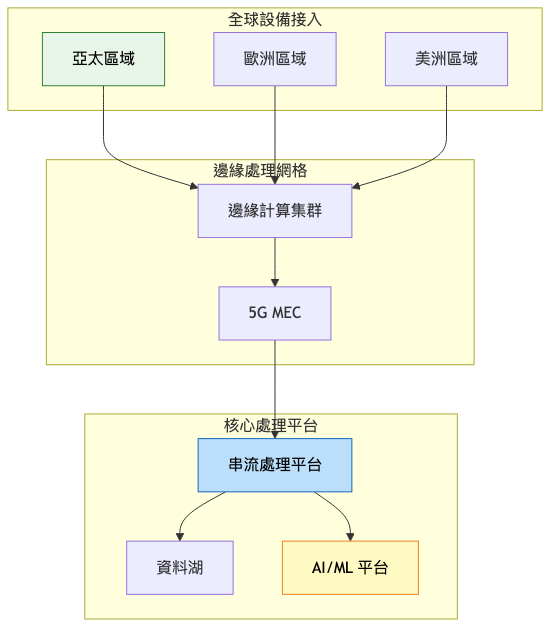
總覽架構圖:
數據處理細節圖:
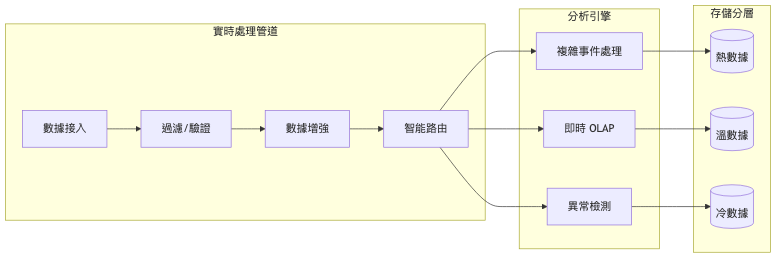
演進決策指南表:
| 觸發條件 | 採取行動 | 預期效果 |
|---|---|---|
| 訊息延遲 > 1s | 增加 Kafka 分區 | 延遲降低 50% |
| CPU 使用率 > 70% | 水平擴展處理節點 | 處理能力提升 80% |
| 存儲成本 > $10K/月 | 啟用數據壓縮和分層 | 成本降低 60% |
| 設備數 > 500K | 部署新區域節點 | 延遲降低 70% |
訊息佇列選擇:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Apache Kafka | 最高吞吐量(605 MB/s)最低延遲(5ms P99)成熟生態系 | 運維複雜不支援優先級佇列 | 大規模 IoT即時串流處理 |
| Apache Pulsar | 存儲計算分離多租戶支援地理複製 | 效能較低(305 MB/s)社區較小 | 多租戶 SaaS跨區域部署 |
| RabbitMQ | 最低延遲(1ms)豐富路由功能易於使用 | 吞吐量受限(38 MB/s)擴展性有限 | 小規模部署複雜路由需求 |
時序資料庫選擇:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| TDengine | 最佳效能(16x 寫入速度)最高壓縮率(12x)最低成本 | 生態系統較新文檔相對較少 | 大規模 IoT成本敏感項目 |
| Apache IoTDB | 原生 IoT 設計設備模型支援邊緣部署友好 | 查詢功能受限工具較少 | 工業 IoT邊緣運算場景 |
| InfluxDB | 成熟生態豐富查詢語言良好工具支援 | 效能瓶頸成本較高 | 中小規模快速原型開發 |
| TimescaleDB | SQL 相容PostgreSQL 生態事務支援 | IoT 優化有限壓縮率較低 | 需要 SQL混合工作負載 |
物聯網系統的技術選型不應該是一次性決策,而是隨著業務成長不斷演進的過程:
初期階段(POC):
選擇熟悉的技術棧,比如 PostgreSQL + Redis,重點是快速驗證業務邏輯。這個階段不要過度設計,單體應用完全可以滿足需求。
成長階段(生產):
當數據量達到 TB 級別時,考慮遷移到專業的時序資料庫。引入訊息佇列(Kafka)來解耦系統組件,開始構建微服務架構。
成熟階段(規模化):
採用雲原生架構,利用 Kubernetes 實現彈性伸縮。引入機器學習進行預測性維護和異常檢測。考慮多雲或混合雲策略以提高可用性。
過早優化陷阱
協議選擇錯誤
忽視邊緣處理
數據模型設計不當
可口可樂飲料公司的 IoT 數位轉型 AWS Case Study、AWS Blog
初期挑戰(2020-2021)
快速部署期(2021)
規模擴展期(2022-2025)
福斯汽車集團的工業雲平台演進 AWS Case Study、Technology Magazine
初期(2019-2020)
成長期(2020-2024)
成熟期(2024-2025)
1. 發布-訂閱模式(Pub-Sub)
2. 命令查詢職責分離(CQRS)
3. 斷路器模式(Circuit Breaker)
設備管理最佳實踐:
數據處理最佳實踐:
安全最佳實踐:
技術指標:
業務指標:
自動化運維
監控告警
持續優化
物聯網資料收集系統的設計是一個需要平衡多個維度的複雜工程。
協議選擇 決定了系統的基礎特性——MQTT 提供可靠性,CoAP 優化資源使用,選擇需要基於實際場景。
架構演進 應該是漸進式的,從簡單的單體應用開始,隨著規模增長逐步引入複雜性。
邊緣運算 不是可選項,而是大規模 IoT 系統的必需品,可以顯著降低延遲和成本。
時序資料庫 的選擇會深刻影響系統的效能和成本,TDengine 在大規模場景下展現出顯著優勢。
安全性 必須從設計之初就納入考慮,而不是事後補充。
從這個系統設計中,我們可以提煉出幾個通用原則:
針對今天探討的物聯網資料收集系統,建議從以下關鍵字或概念深化研究與實踐,以擴展技術視野與解決方案能力:
LoRaWAN 和 NB-IoT:探索低功耗廣域網路技術,理解如何構建覆蓋城市級別的 IoT 網路,特別適合智慧城市和農業物聯網應用。
數位孿生(Digital Twin):學習如何構建物理世界的數位映射,結合即時數據和模擬技術進行預測性分析,這是工業 4.0 的核心技術。
時序資料庫內部原理:深入理解 LSM-Tree、列式存儲、時間分區等核心技術,有助於優化數據模型設計和查詢效能。
MQTT 5.0 和 CoAP observe:掌握最新協議特性,如 MQTT 5.0 的請求響應模式、共享訂閱,以及 CoAP 的觀察模式,提升系統設計的靈活性。
邊緣 AI 框架:研究 TensorFlow Lite、ONNX Runtime、OpenVINO 等邊緣推理框架,實現智能化的本地決策能力。
可根據自身興趣,針對上述關鍵字搜尋最新技術文章、專業書籍或參加線上課程,逐步累積專業知識和實踐經驗。
明天我們將深入探討「內容推薦系統的設計」。當數億用戶每天產生數十億次互動時,如何在毫秒內為每個用戶找到最相關的內容?我們將揭開 Netflix、YouTube 背後的推薦引擎秘密,探討協同過濾、深度學習、實時特徵工程等核心技術,以及如何解決冷啟動、資料稀疏性、公平性等挑戰。準備好進入個性化推薦的精彩世界了嗎?


 iThome鐵人賽
iThome鐵人賽