想像你正在瀏覽 Netflix,系統精準地推薦了一部你從未聽過但完全符合品味的影集。或是在 YouTube 上,推薦算法總是能找到讓你一看再看的內容。這些看似魔法般的推薦背後,是一個結合了數據科學、系統工程與商業智慧的複雜系統。
今天,我們要深入探討如何設計一個能夠處理億級用戶、提供個人化推薦的內容推薦系統。推薦系統看似只是「猜測用戶喜好」,但實際上需要解決許多技術挑戰:如何在用戶還沒有任何行為數據時提供推薦?如何平衡推薦的準確性與多樣性?如何在毫秒級延遲內完成複雜的模型推理?這些問題的答案,將決定一個內容平台的成敗。
我們要設計的是一個通用內容推薦系統,可應用於新聞、影片、商品、音樂等多種內容類型。系統需要根據用戶的歷史行為、偏好設定、社交關係等多維度資訊,即時生成個人化的內容推薦列表。
這個系統不僅要提供準確的推薦,還要考慮商業目標(如提高用戶停留時間、增加付費轉換率)、內容生態健康(避免資訊繭房效應)以及技術可行性(即時性、可擴展性)。
功能性需求:
非功能性需求:
技術挑戰 1:冷啟動問題
新用戶沒有歷史行為數據,新內容沒有用戶互動記錄,如何提供有效推薦?這直接影響新用戶的首次體驗和新內容的曝光機會。
技術挑戰 2:即時性與準確性的平衡
複雜的深度學習模型能提供更準確的推薦,但推理時間較長。如何在毫秒級延遲要求下,提供高質量的推薦結果?
技術挑戰 3:推薦多樣性與相關性的權衡
過度個人化會導致資訊繭房,但過度多樣化又會降低用戶滿意度。如何找到最佳平衡點?
| 維度 | 純協同過濾 | 深度學習方案 | 混合推薦系統 |
|---|---|---|---|
| 核心特點 | 基於用戶-物品矩陣分解 | 使用深度神經網路建模 | 結合多種推薦算法 |
| 優勢 | 實現簡單、可解釋性強 | 準確度高、特徵學習能力強 | 靈活性高、效果穩定 |
| 劣勢 | 冷啟動問題嚴重、稀疏性問題 | 計算成本高、黑盒模型 | 系統複雜度高 |
| 適用場景 | 用戶行為密集的場景 | 大規模數據、高準確度要求 | 綜合性內容平台 |
| 複雜度 | 低 | 高 | 中高 |
| 成本 | 低 | 高(需要 GPU) | 中 |
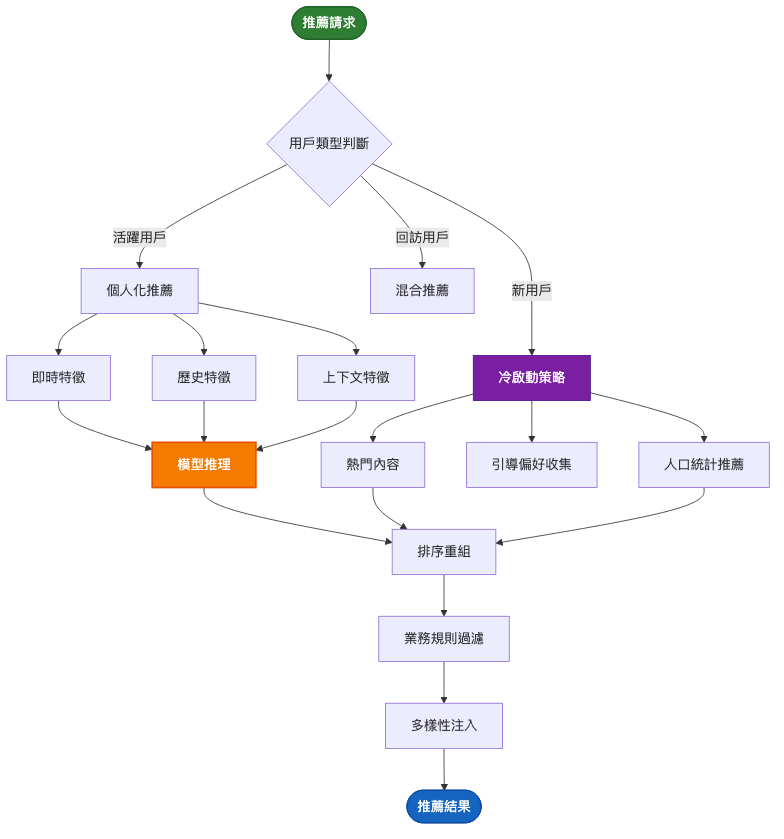
架構重點:
系統架構圖:
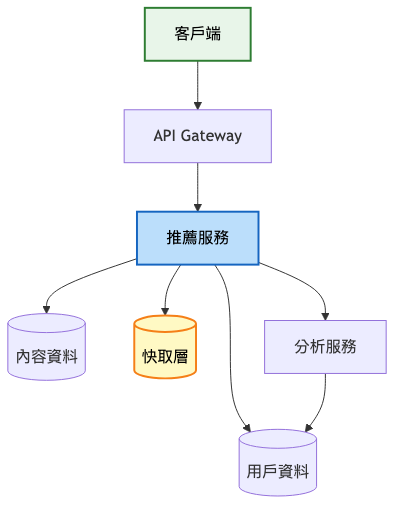
架構重點:
系統架構圖:
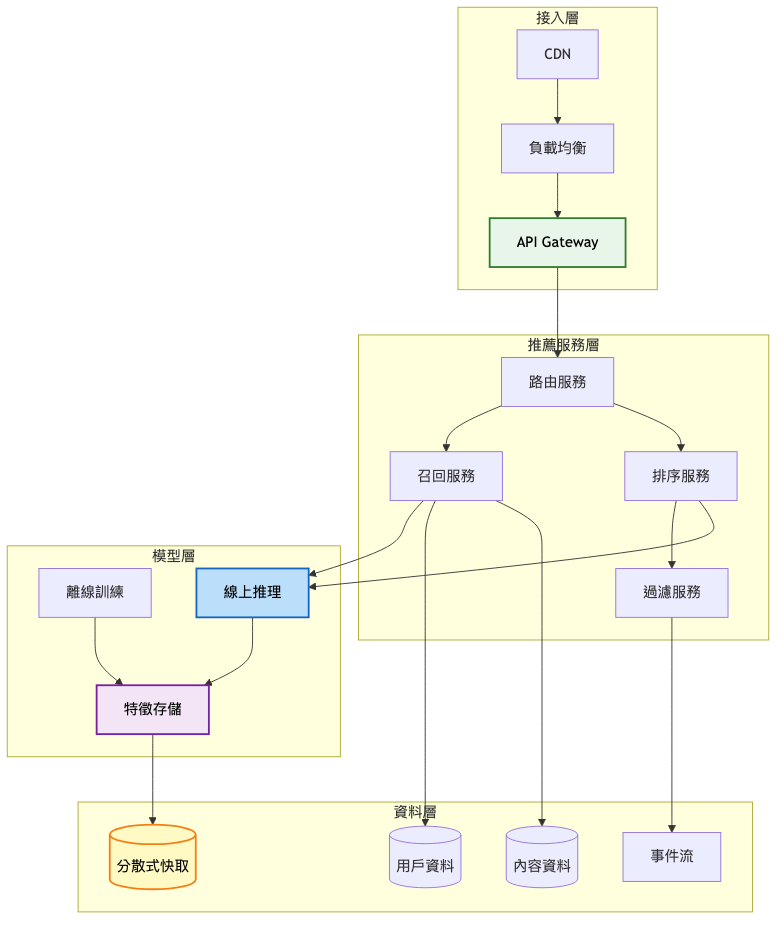
關鍵架構變更:
模型服務分離
多階段推薦流程
特徵工程平台
架構重點:
總覽架構圖:
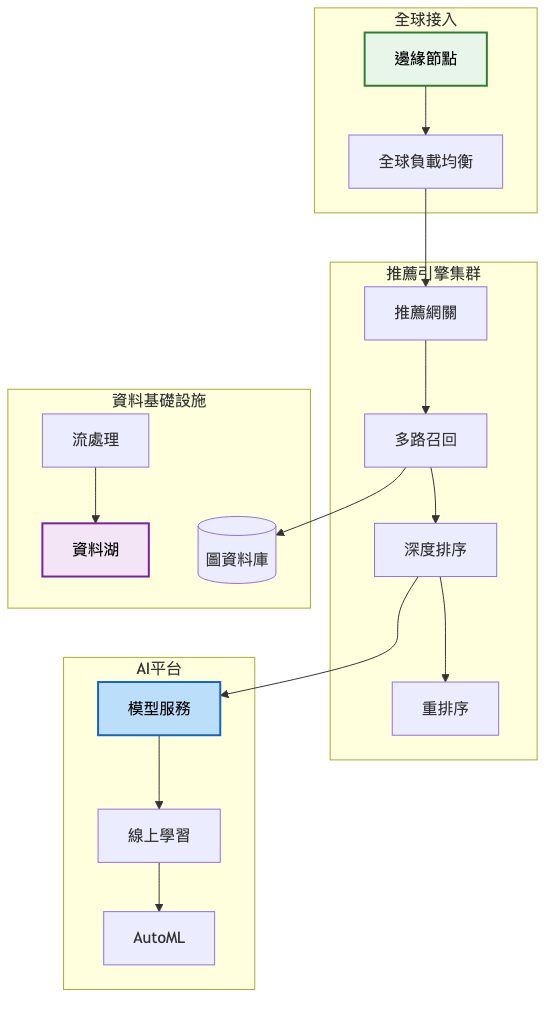
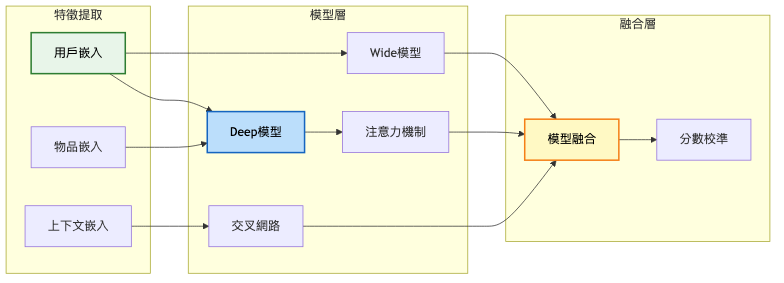
深度學習推薦架構詳細圖:
演進決策指南表:
| 觸發條件 | 採取行動 | 預期效果 |
|---|---|---|
| DAU > 10萬 | 引入機器學習模型 | CTR 提升 30% |
| 延遲 > 150ms | 部署邊緣計算節點 | P99 延遲降至 50ms |
| 模型更新週期 > 24小時 | 實施線上學習 | 模型新鮮度提升至小時級 |
| 冷啟動用戶占比 > 20% | 強化冷啟動策略 | 新用戶留存率提升 25% |
| 推薦同質化嚴重 | 引入探索機制 | 內容覆蓋率提升 40% |
推薦演算法選型:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| 協同過濾(CF) | 簡單有效、可解釋性強 | 冷啟動問題、稀疏性 | 用戶行為豐富 |
| 內容過濾(CBF) | 無冷啟動問題、推薦透明 | 難以發現新興趣 | 內容特徵明確 |
| 深度學習(DNN) | 特徵學習能力強、效果好 | 計算資源需求高 | 大規模數據 |
| 圖神經網路(GNN) | 捕捉複雜關係 | 訓練複雜度高 | 社交推薦場景 |
| 強化學習(RL) | 長期收益最優化 | 訓練不穩定 | 序列推薦 |
特徵存儲方案:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Redis | 極低延遲、簡單 | 容量受限、成本高 | 熱點數據 |
| HBase | 海量存儲、高吞吐 | 延遲較高 | 離線特徵 |
| Cassandra | 分散式、高可用 | 一致性較弱 | 寫密集場景 |
| Feature Store | 統一管理、版本控制 | 額外複雜度 | 企業級應用 |
推薦系統的技術選型需要根據業務發展階段靈活調整:
初期階段:快速驗證
成長階段:效果優化
成熟階段:精細運營
過早優化深度學習
忽視冷啟動問題
過度個人化
忽視業務規則
Netflix 的推薦系統演進 參考資料:Netflix Tech Blog - Foundation Model for Personalized Recommendation
初期(2000-2006)
成長期(2006-2015)
近期狀態(2015-至今)
1. 漏斗模式(Funnel Pattern)
2. 雙塔模式(Two-Tower Pattern)
3. 特徵交叉模式(Feature Cross Pattern)
技術指標:
業務指標:
推薦品質指標:
自動化模型管理
監控告警體系
持續優化流程
明天我們將探討「分散式快取系統」的設計。當推薦系統需要在毫秒內返回結果時,一個高效的快取層就變得至關重要。我們將深入探討如何設計一個能夠處理百萬 QPS、保證資料一致性、支援跨區域同步的分散式快取系統。從快取失效策略到資料分片方案,從熱點問題處理到快取預熱機制,明天將是一場關於「速度與一致性」的技術盛宴。
ACM Transactions - The Netflix Recommender System
Netflix Tech Blog - System Architectures for Personalization and Recommendation
Netflix Tech Blog - Netflix Recommendations: Beyond the 5 stars
Netflix Tech Blog - Artwork Personalization at Netflix
GitHub - Causal Inference for Recommendation Resources
IEEE TKDE - Survey on Federated Recommendation Systems


 iThome鐵人賽
iThome鐵人賽