在 Day 11,我們成功地讓 Notion 筆記存進了 SQLite 資料庫。這就像是為我們的「第二大腦」建立了記憶中樞,我們可以透過 SQL 精準地存取資料。
但我們很快就發現,這個大腦只擁有「記憶力」,卻缺乏「理解力」。
它只認得精準的關鍵字。當我們想知道:「物件導向是什麼?」,它只能用 LIKE '%物件導向%' 這樣死板的方式去尋找完全符合的字串。如果我的筆記寫的是:「類別,是物件的設計藍圖…」,即使語意完全相關,傳統的搜尋方式也會無法搜尋到。
這時 Embedding 就派上用場。Embedding 會把「物件導向是什麼?」這個問題轉成數字向量(座標),再到資料庫裡找「語意最接近」的內容,就能找到那段關於「類別與藍圖」的筆記。
這就是為什麼我們需要向量化 (Embedding) —— 讓機器能用「語意」來理解資料。
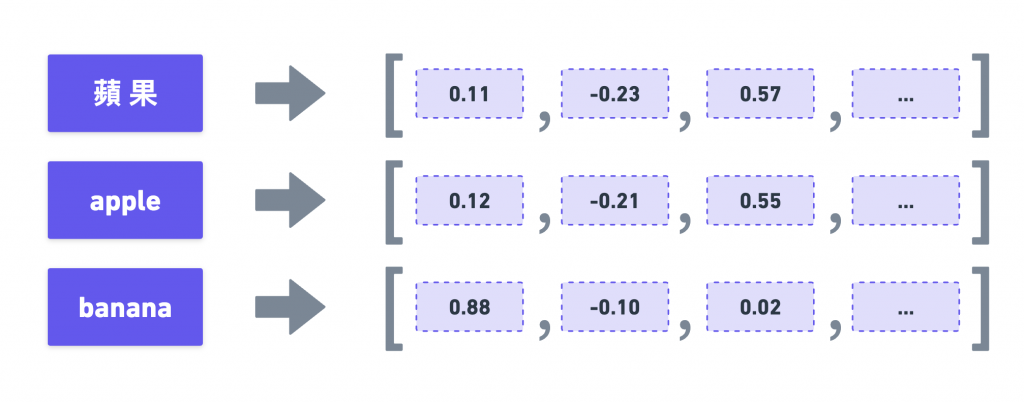
簡單來說,Embedding 就是把一段文字變成一組「數字座標」(向量 (vector)),放進一個高維度的「語意空間」,語意相近的句子,向量之間的距離也會接近。
舉個經典的例子,蘋果、apple 和 banana 這三個詞:
如果我們的筆記只有幾百則,理論上可以直接在程式裡計算所有向量之間的距離,找出最接近的結果。
但當筆記達到數千、數萬筆的規模時,逐一計算將會非常耗效能。這時,我們就需要專門的向量資料庫 (Vector Database) 來加速查詢。
常見選項與選擇考量:
| 向量資料庫 | 特點 | 最適用場景 |
|---|---|---|
| FAISS | Facebook 開源函式庫,速度快、輕量。 | 本地端、學術研究、需要高度客製化。 |
| Chroma | API 設計簡潔,與 Python 生態整合佳。 | 個人專案、中小型知識庫、快速原型開發。 |
| Pinecone | 全託管雲端服務,穩定、可擴展性強。 | 企業級應用、需要處理超大規模數據。 |
現在,我們從 Notion 到 AI 問答的完整流程變得更加清晰了:
Notion API
│
▼
JSON (data/clean)
│
▼
SQLite (notion.db)
│
▼
Embedding Model
│
▼
Vector DB
notion_blocks.block_text 中挑出有內容的段落、程式碼、標題。text-embedding-3-small / sentence-transformers。block_id 存進 Vector DB,並保留 SQLite 的結構化查詢。今天,我們用白話理解了 Embedding 的概念:
它就像在地圖上找到最近的鄰居,讓系統能用「語意」檢索,而不是死板的字詞比對。
不過,在正式進行 Embedding 之前,我們還需要處理一個重要的步驟 —— Chunking(文字切分策略)。
因為如果每個 Block 太小,Embedding 可能抓不到語意;但如果太大,又會導致向量過長、浪費資源。
因此在 Day 13,我們會先討論:

