昨天(Day 12)我們談到了 知識庫資料管理:
但是,光有版本控制還不夠。 在真實世界裡,知識會隨著時間而變動 (Drift),如果我們的系統沒有及時更新,就會回答錯誤的資訊。所以,今天我們的重點就是:
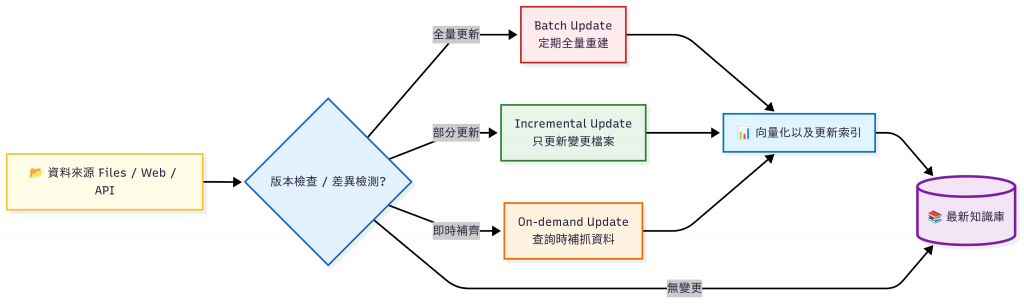
👉 如何發現變動以及更新的策略介紹
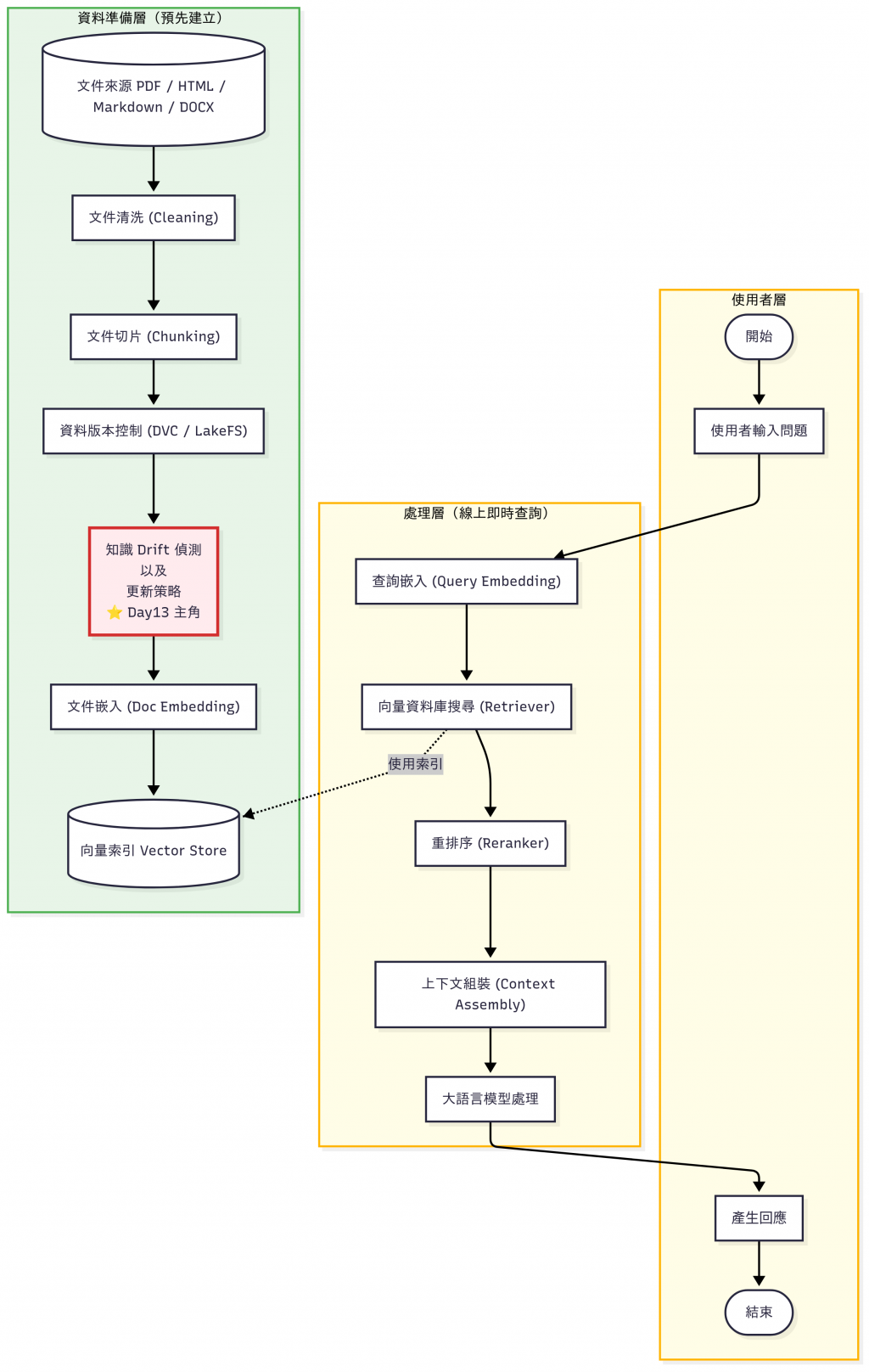
在機器學習裡,Data Drift 指的是 資料分布隨時間改變。知識不像硬碟檔案一成不變,它會隨時間更新。如果我們不跟上,就好像還在用十年前的百科全書查資料——結果自然會出錯。
在 RAG 系統裡, Data Drift 分為三種:
概念漂移 (Concept Drift)
資料漂移 (Data Drift)
檢索漂移 (Retrieval Drift)
實際例子:
| 資料類型 | 特性 | 適合的更新策略 | 常見應用 | 說明 |
|---|---|---|---|---|
| FAQ / 內部文件 | 不定期改版、檔案型知識庫 | Incremental Update | 公司內部 FAQ、產品手冊 | 只更新有變更的文件,避免每次都重建整個索引 |
| 熱門新聞 / 即時資訊 | 高時效性、即時變動 | On-demand Update | 新聞網站、股價、天氣預報 | 查詢時動態抓取,確保答案最新,但延遲較高 |
| 歷史資料庫 / 法規檔案 | 大量、低頻更新,內容通常固定 | Batch Update | 法規資料庫、醫療規範 | 週期性全量更新,確保一致性,適合穩定資料 |
完整可執行程式碼 已經放在 GitHub。
import os, hashlib
def get_file_hash(path):
hash_md5 = hashlib.md5()
with open(path, "rb") as f:
for chunk in iter(lambda: f.read(4096), b""): # 分塊計算避免一次吃光記憶體
hash_md5.update(chunk)
return hash_md5.hexdigest()
file_path = "faq.pdf"
print(os.path.getmtime(file_path), get_file_hash(file_path))
執行結果:
# 把 Day12 的 worker_manual.pdf 移過來 Day13 用
❯ python metadata_comparison.py
📥 第一次建立 metadata 紀錄。
# 檔案沒有變動的情況下再執行一次
❯ python metadata_comparison.py
📂 檔案: worker_manual.pdf
- 之前修改時間: 2025-09-27 11:17:25
- 之前 Hash: 5106549b250c4c06a9bd1e59ab950e8a
- 目前修改時間: 2025-09-27 11:17:25
- 目前 Hash: 5106549b250c4c06a9bd1e59ab950e8a
✅ 檔案內容無變更。
# 修改 worker_manual.pdf 後儲存,再執行一次
❯ python metadata_comparison.py
📂 檔案: worker_manual.pdf
- 之前修改時間: 2025-09-27 11:17:25
- 之前 Hash: 5106549b250c4c06a9bd1e59ab950e8a
- 目前修改時間: 2025-09-27 11:25:57
- 目前 Hash: 0323bd12d945343f73035ab4503b2e3d
⚠️ 檔案內容已變更,需要更新知識庫!
# version_check.py
import yaml
def get_version(path: str) -> str:
with open(path, "r", encoding="utf-8") as f:
data = yaml.safe_load(f)
return data.get("version", "0.0.0")
def compare_versions(old_v: str, new_v: str) -> bool:
"""若版本號升級,回傳 True"""
def parse(v): return list(map(int, v.split(".")))
return parse(new_v) > parse(old_v)
old_file = "faq_v1.yaml"
new_file = "faq_v2.yaml"
old_version = get_version(old_file)
new_version = get_version(new_file)
print(f"舊版: {old_version}, 新版: {new_version}")
if compare_versions(old_version, new_version):
print("⚠️ 偵測到新版本,需要更新知識庫!")
else:
print("✅ 沒有新版本,無需更新。")
這邊可以準備兩個檔案:
# 範例輸入檔(faq_v1.yaml)
version: 1.0.0
faq:
- q: 退貨政策
a: 商品需在 7 天內退回
# 範例輸入檔(faq_v2.yaml)
version: 1.1.0
faq:
- q: 退貨政策
a: 商品需在 14 天內退回
- q: 是否支援線上客服?
a: 是的,請至官網點選聊天室
執行結果:
❯ python version_check.py
舊版: 1.0.0, 新版: 1.1.0
⚠️ 偵測到新版本,需要更新知識庫!
# embedding_comparison.py
from openai import OpenAI
from dotenv import load_dotenv
import numpy as np
import os
# 載入 .env 檔案
load_dotenv()
# 讀取 OPENAI_API_KEY
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("沒有找到 OPENAI_API_KEY,請檢查境變數!")
# 初始化 OpenAI client
client = OpenAI()
def embedding(text: str):
"""取得文字的向量表示"""
return client.embeddings.create(
model="text-embedding-3-small",
input=text
).data[0].embedding
def cosine_similarity(v1, v2):
"""計算兩個向量的餘弦相似度"""
return np.dot(v1, v2) / (np.linalg.norm(v1) * np.linalg.norm(v2))
# 舊版 FAQ vs 新版 FAQ
old_text = "退貨政策:商品需在 7 天內退回,且保持完整包裝。"
new_text = "退貨政策:商品需在 14 天內退回,並保持原始包裝未損壞。"
vec_old = embedding(old_text)
vec_new = embedding(new_text)
similarity = cosine_similarity(vec_old, vec_new)
print(f"語意相似度: {similarity:.4f}")
# 設定門檻(可依需求調整,例如 0.95)
if similarity < 0.95:
print("⚠️ 偵測到重要差異,需要更新知識庫!")
else:
print("✅ 差異不大,可以不用更新。")
執行結果:
❯ python embedding_comparison.py
語意相似度: 0.9096
⚠️ 偵測到重要差異,需要更新知識庫!
這邊列出了適合 / 不適合差異檢測的各種場景:
| 文件類型 / 場景 | 適合用 Embedding 差異檢測 | 為什麼 |
|---|---|---|
| 法規 / 政策文件 | ✅ 適合 | 條文語意才是關鍵(例如「7 天退貨 → 14 天退貨」) |
| FAQ / 產品手冊 / SOP | ✅ 適合 | 偵測語意變化,避免因文字修飾誤判 |
| 研究報告 / 白皮書 | ✅ 適合 | 關心語意數值或觀點是否改變,而不是排版 |
| 合約文件 | ✅ 適合 | 條款語意小改動就可能影響法律效果 |
| 程式碼 / 設定檔 | ❌ 不適合 | 必須逐字精準比對,傳統 diff 更可靠 |
| 報表 / 數據表格 | ❌ 不適合 | 數字一有變化就是差異,不需要語意比對 |
| 超大型文件(數百頁 PDF) | ⚠️ 視情況 | 成本太高,建議只針對關鍵章節比對 |
完整可執行程式碼 已經放在 GitHub。
模擬一個知識庫更新流程:

註:以下
pipeline.py的向量化採用 本地 hashing trick(無需 API Key),
方便 Demo 與 CI/CD 測試,不會額外消耗 OpenAI Token。
真實場景可改成 OpenAI Embeddings 或自家模型 (詳見 README.md)。
# pipeline.py
from __future__ import annotations
import os
from steps.detect import detect_change, save_hash
from steps.embed import embed_texts
from steps.update_index import write_index
SRC_FILE = "data/faq.txt"
META_HASH = "artifacts/source.hash"
INDEX_OUT = "artifacts/vector_index.json"
def simple_chunk(text: str, max_chars: int = 400) -> list[str]:
# 極簡切片:依段落與長度切
parts = []
for para in text.splitlines():
if not para.strip():
continue
buf = para.strip()
while len(buf) > max_chars:
parts.append(buf[:max_chars])
buf = buf[max_chars:]
if buf:
parts.append(buf)
return parts or ["(空文件)"]
def main() -> None:
print("🔍 檢查檔案是否變動…")
res = detect_change(SRC_FILE, META_HASH)
if not res.changed:
print("✅ 無變動,跳過更新")
return
print("⚠️ 偵測到變動,開始更新索引…")
with open(SRC_FILE, "r", encoding="utf-8") as f:
text = f.read()
chunks = simple_chunk(text)
print(f"✂️ 切出 {len(chunks)} 個片段")
vectors = embed_texts(chunks)
print(f"🧠 產生 {len(vectors)} 筆向量")
records = [
{"id": i, "text": chunks[i], "vector": vectors[i]}
for i in range(len(chunks))
]
write_index(INDEX_OUT, records)
save_hash(META_HASH, res.new_hash)
print(f"📦 已寫入索引:{INDEX_OUT}")
print("🎉 更新完成!")
if __name__ == "__main__":
# 確保資料夾存在
os.makedirs("data", exist_ok=True)
os.makedirs("artifacts", exist_ok=True)
if not os.path.exists(SRC_FILE):
with open(SRC_FILE, "w", encoding="utf-8") as f:
f.write("公司員工手冊 v1.0:\n第二章 加班與補休:加班需事前申請,工時可折換補休。\n")
main()
執行結果:
# 第一次跑
❯ python pipeline.py
🔍 檢查檔案是否變動…
⚠️ 偵測到變動,開始更新索引…
✂️ 切出 2 個片段
🧠 產生 2 筆向量
📦 已寫入索引:artifacts/vector_index.json
🎉 更新完成!
# 修改 data/faq.txt 後跑第二次
❯ python pipeline.py
🔍 檢查檔案是否變動…
⚠️ 偵測到變動,開始更新索引…
✂️ 切出 3 個片段
🧠 產生 3 筆向量
📦 已寫入索引:artifacts/vector_index.json
🎉 更新完成!
# 都不修改檔案,直接跑第三次
❯ python pipeline.py
🔍 檢查檔案是否變動…
✅ 無變動,跳過更新
今天我們展示了如何偵測版本過舊以及簡單的更新示範,而在 Day23 - 再訓練與知識迭代 (Retraining & Continual Learning) 我們會示範增量更新實際的作法。
| 類別 | 常見陷阱 ⚠️ | 最佳實務 ✅ |
|---|---|---|
| 檔案偵測 | 只依賴 mtime,容易誤判(重新存檔、Git revert) |
同時比對 檔案大小 + Hash,必要時再進行 Embedding 差異比對 |
| 更新策略 | 每天全量重建導致 Token 花費變高、效率差 | 根據資料特性選擇 Incremental / On-demand / Batch,只在必要時更新 |
| 差異比對 | 對所有文件做 Embedding Diff 導致 Token 成本爆炸 | 分層檢測:先 metadata/版本號,再向量化做精細比對 |
| 檢索品質 | 只管文件更新,忽略檢索漂移(query 命中率下降卻沒發現) | 維護 Regression Query Set(常見查詢集),每次更新後回歸測試 |
| 版本管理 | 覆蓋舊知識庫,出錯後難以回滾 | 保留歷史版本,支援 rollback(可以參考 Day12 文章) |
| 監控告警 | 沒監控,Pipeline 掛掉沒人發現 | 監控 + 告警:Prometheus / Grafana + Slack/Email 通知 |
想像一座圖書館,知識庫就像它的館藏。
如果圖書館不更新,你在 2025 年查「世界人口」,卻還讀到「2000 年人口 60 億」,這樣的答案就失去參考價值。
同樣地,三種 Drift 也能在圖書館裡找到對應:
Day 13 的重點:
明天(Day 14),我們將進入 Pipeline 自動化,看看如何讓這些「文件清洗 → 向量化 → 索引更新」的流程完全自動化,減少人力負擔。

