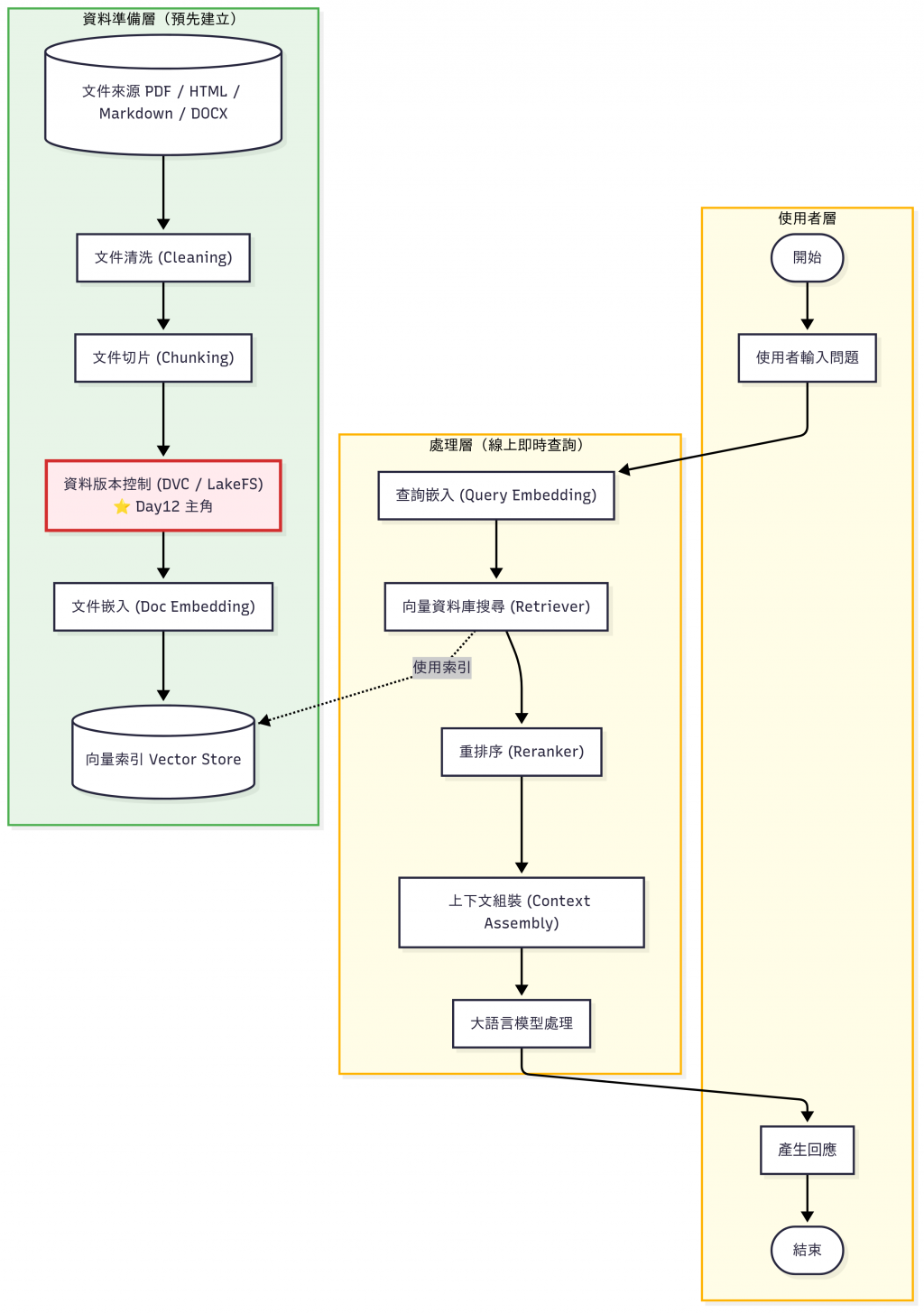
經過前幾天(Day 8–11) 的實作,我們已經完成了從 文件清洗 → Chunking → 向量化 → 索引 → 查詢流程 → 上下文組裝 的基礎。
這些流程已經涵蓋了 RAG (Retrieval-Augmented Generation) 的核心元件,我們已經完成了一個能夠 支援文件檢索並提供上下文給 LLM 回答的基礎 RAG 系統。但是,如果要打造一個真正可用的企業級 RAG 系統,還需要考慮:
這兩天的主題,就是針對這些挑戰:
今天的文章就是要讓各位讀者理解:
📝 知識庫不只是建一次,而是要「持續更新、可追溯、能擴展」。
在真實場景裡,知識庫很少只來自一個來源:
同時,這些文件不是一成不變的:
如果沒有 整合機制 和 版本控制(Version Control):
無論 PDF、Web、API,都需要進入 同一個 pipeline 進行格式處理,出來的格式才會相近。
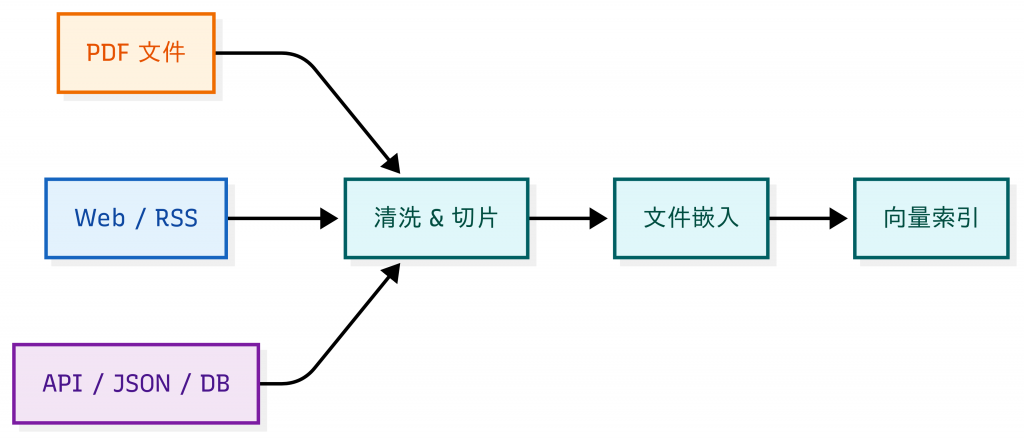
目標是:不管資料來自哪裡,最後都能轉換成 Chunk → Embedding → Index 的統一格式。
除了 Demo1: PDF 文件 的程式碼我會寫在本文,其他兩種的程式碼因為篇幅關係,我會貼在 GitHub Repo,文中僅會顯示執行結果,方便做比較。有興趣的讀者請自行到 GitHub Repo 參考。
完整可執行程式碼 已經放在 GitHub。
先準備一份 worker_manual.pdf,內容如下:
公司員工手冊 v1.0
第一章:出勤規範
1. 上班時間:上午 9 點至下午 6 點。
2. 請假規則:需提前一天提出申請,緊急情況可事後補辦。
3. 遲到超過 15 分鐘需登記並扣考勤分。
第二章:加班與補休
1. 加班需事前提出申請,經主管核准後方可進行。
2. 加班工時可折換補休,需於一個月內使用完畢。
3. 連續加班超過三日,主管需評估員工狀況。
第三章:出差與報銷
1. 出差需填寫出差單,並附上詳細行程與預算。
2. 報銷需提供正式發票,金額超過 1000 元需經理簽核。
3. 出差結束後需提交出差報告,三日內完成。
第四章:福利制度
1. 每年提供三天帶薪病假。
2. 員工旅遊每兩年舉辦一次,由公司補助部分費用。
3. 員工可申請教育訓練補助,每年上限 5000 元。
第五章:獎懲制度
1. 表現優異者可獲得年度獎金或晉升機會。
2. 違反公司規範者,視情節輕重給予警告或處分。
3. 貪污、洩密等重大違規行為將直接解僱。
程式碼如下,這隻程式會做以下步驟:
pdfplumber 抽取文字,並依 章節/條列 切成 chunk。TfidfVectorizer(analyzer="char", ngram_range=(1,3)) + NearestNeighbors,支援中文。# pdf_ingestion_demo.py (robust)
import pdfplumber
import re
import os
from typing import List, Tuple
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.neighbors import NearestNeighbors
# ========== 工具函式 ==========
def clean_text(s: str) -> str:
"""移除多餘空白"""
return re.sub(r"\s+", " ", s).strip()
def chunk_by_rules(text: str) -> List[str]:
"""
根據規則切分 PDF 文字:
- 章節標題 (第X章)
- 條列 (1. / 2. / 3.)
"""
lines = [line.strip() for line in text.split("\n") if line.strip()]
chunks, buf = [], []
for line in lines:
# 章節標題:單獨成段
if line.startswith("第") and "章" in line:
if buf:
chunks.append(" ".join(buf))
buf = []
buf.append(line)
# 條列數字:單獨成段
elif re.match(r"^\d+\.", line):
if buf:
chunks.append(" ".join(buf))
buf = []
buf.append(line)
# 其他:接續到當前段
else:
buf.append(line)
if buf:
chunks.append(" ".join(buf))
return [clean_text(c) for c in chunks]
def load_pdf(path: str) -> List[str]:
"""從 PDF 載入文字,並依規則切成 chunk(含錯誤處理)"""
if not os.path.exists(path):
print(f"❌ 找不到檔案:{path},請確認路徑是否正確。")
return []
docs: List[str] = []
try:
with pdfplumber.open(path) as pdf:
if not pdf.pages:
print("⚠️ 這個 PDF 沒有任何頁面。")
return []
for i, page in enumerate(pdf.pages, start=1):
try:
text = page.extract_text()
except Exception as pe:
print(f"⚠️ 第 {i} 頁解析失敗,已略過。原因:{pe}")
continue
if text:
docs.extend(chunk_by_rules(text))
else:
print(f"ℹ️ 第 {i} 頁沒有可抽取文字,可能是掃描影像或加密。")
except Exception as e:
print(f"⚠️ 開啟或處理 PDF 時發生錯誤:{e}")
return []
return docs
def build_index(docs: List[str]) -> Tuple[TfidfVectorizer, NearestNeighbors, List[str]]:
"""
建立向量索引
- 使用 char ngram,更適合中文
- ngram_range=(1,3):單字、雙字、三字都考慮
"""
if not docs:
raise ValueError("沒有可用文件段落可建立索引。")
vec = TfidfVectorizer(analyzer="char", ngram_range=(1,3))
X = vec.fit_transform(docs)
nn = NearestNeighbors(metric="cosine").fit(X)
return vec, nn, docs
def query(q: str, vec: TfidfVectorizer, nn: NearestNeighbors, docs: List[str], topk: int = 3) -> None:
"""查詢,並回傳最相似的段落"""
if not docs:
print("⚠️ 索引為空,無法查詢。")
return
qv = vec.transform([q])
k = min(topk, len(docs))
dist, idx = nn.kneighbors(qv, n_neighbors=k)
print(f"\nQ: {q}")
for d, i in zip(dist[0], idx[0]):
print(f"- {docs[i]} (score={1-d:.4f})")
# ========== 主程式 ==========
if __name__ == "__main__":
pdf_path = "worker_manual.pdf" # 換成要處理的 PDF 檔案路徑
docs = load_pdf(pdf_path)
if not docs:
print("⚠️ 沒有載入任何段落,請確認 PDF 是否有效或可抽取文字。")
else:
print(f"✅ 載入完成,共 {len(docs)} 段落")
try:
vec, nn, docs = build_index(docs)
except Exception as e:
print(f"⚠️ 建立索引失敗:{e}")
else:
# 範例查詢
query("請假規則", vec, nn, docs)
query("加班", vec, nn, docs)
query("報銷", vec, nn, docs)
執行結果:
❯ python pdf_ingestion_demo.py
✅ 載入完成,共 21 段落
Q: 請假規則
- 2. 請假規則:需提前⼀天提出申請,緊急情況可事後補辦。 (score=0.3712)
- 1. 每年提供三天帶薪病假。 (score=0.0496)
- 第⼀章:出勤規範 (score=0.0472)
Q: 加班
- 第⼆章:加班與補休 (score=0.2841)
- 3. 連續加班超過三⽇,主管需評估員⼯狀況。 (score=0.1735)
- 1. 加班需事前提出申請,經主管核准後⽅可進⾏。 (score=0.1685)
Q: 報銷
- 第三章:出差與報銷 (score=0.3456)
- 2. 報銷需提供正式發票,⾦額超過 1000 元需經理簽核。 (score=0.1690)
- 3. 出差結束後需提交出差報告,三⽇內完成。 (score=0.0587)
💡 延伸思考:
當文件數超過 數萬筆 時,單機向量化與檢索會出現記憶體與計算瓶頸。
這時候需要考慮:
- 分批處理(Batching)
- 分散式向量化(例如 Spark / Ray / GPU 加速)
- 或直接使用雲端向量資料庫(如 Pinecone, Milvus, Weaviate)
requests 下載 HTML,BeautifulSoup 萃取 <p> 文字。TfidfVectorizer(analyzer="char", ngram_range=(1,3)) + NearestNeighbors。執行結果如下:
❯ python web_ingestion_demo.py
載入完成,共 53 段落
Q: 生成式AI
- 生成式 AI 的安全隱憂 (score=0.3399)
- 那麼生成式 AI 自己又會怎麼解釋生成式 AI 呢?我們詢問 TAIDE,得到了以下的答案: (score=0.2877)
- 勢不可擋的生成式 AI 浪潮 (score=0.2717)
Q: 微軟
- 考慮到不同地區的文化背景可能導致對同一句話的不同解讀,因此 AI 的發展不能僅僅由國際大型公司單方面決定,而應該通過微調來適應各地區的文化背景,以更符合當地的實際需求。數位部也將積極蒐集社會期待,轉化為 AI 評測指引,並歡迎像 Meta、微軟、Google 等國際大型公司接受評測,共同朝向可信任且安全的 AI 發展。 (score=0.1062)
- 9. 教育與研究:研製能生成新知識和教材的教育科技平台、工具和軟體,用於科學研究、數學證明、歷史分析等領域。 (score=0.0406)
- 勢不可擋的生成式 AI 浪潮 (score=0.0000)
⚠️ 提醒:Web/API 資料通常會隨時間變動,需要透過 排程 (scheduler) 重新抓取,例如 cron job、Airflow、Prefect,具體做法會在 day14 解說。
這邊會模擬呼叫某個內部 API 回傳的 JSON 檔案:
{
"faqs": [
{"q": "上班時間", "a": "上午 9 點至下午 6 點"},
{"q": "請假規則", "a": "需提前一天提出申請,緊急情況可事後補辦"},
{"q": "加班補休", "a": "加班工時可折換補休,需於一個月內使用完畢"},
{"q": "報銷流程", "a": "需提供正式發票,金額超過 1000 元需經理簽核"}
]
}
❯ python api_ingestion_demo.py
載入完成,共 4 筆 FAQ
Q: 加班
- Q: 加班補休 A: 加班工時可折換補休,需於一個月內使用完畢 (score=0.3332)
- Q: 上班時間 A: 上午 9 點至下午 6 點 (score=0.0427)
Q: 報銷
- Q: 報銷流程 A: 需提供正式發票,金額超過 1000 元需經理簽核 (score=0.1721)
- Q: 請假規則 A: 需提前一天提出申請,緊急情況可事後補辦 (score=0.0000)
有了格式統一的資料之後,接下來的挑戰是隨著時間的推移,管理 資料版本。
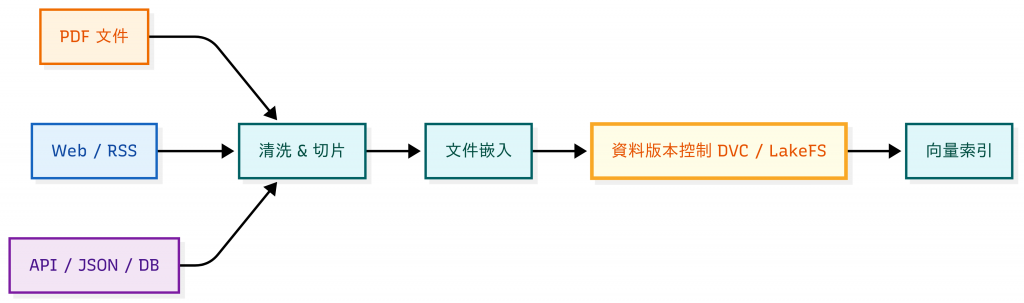
在進入工具與實作之前,我們必須先理解一件事:知識庫不是靜態的,而是有生命週期 (Lifecycle)。知識庫的資料會隨時間持續演變,就像軟體開發一樣有不同階段:
flowchart LR
A[新增 Create] --> B[更新 Update]
B --> T[測試 / 驗證 Test]
T --> C[淘汰 Deprecate]
C --> D[回溯 / 審計 Audit]
D --> B
style A fill:#E8F5E9,stroke:#2E7D32,stroke-width:2px,color:#1B5E20
style B fill:#E3F2FD,stroke:#1565C0,stroke-width:2px,color:#0D47A1
style T fill:#E0F7FA,stroke:#006064,stroke-width:2px,color:#004D40
style C fill:#FFF3E0,stroke:#EF6C00,stroke-width:2px,color:#E65100
style D fill:#EDE7F6,stroke:#5E35B1,stroke-width:2px,color:#311B92
%% linkStyle 索引:A->B(0), B->T(1), T->C(2), C->D(3), D->B(4)
linkStyle 0 stroke:#2E7D32,stroke-width:2px
linkStyle 1 stroke:#1565C0,stroke-width:2px
linkStyle 2 stroke:#006064,stroke-width:2px
linkStyle 3 stroke:#EF6C00,stroke-width:2px
linkStyle 4 stroke:#5E35B1,stroke-width:2px
在企業真實場景裡,缺乏版本控制往往不是小問題,而是會帶來實際風險:
這種情境在一般文件協作中也早有前車之鑑:多人共用雲端文件若沒有版本管理,常常出現「誤發舊版檔案」或「被覆蓋掉的修改」。
因此,版本控制不是錦上添花,而是正式產品化的必要機制。
| 規模 | 更新頻率 | 推薦方案 | 特點 | 成本 | 效能 | 適合場景 |
|---|---|---|---|---|---|---|
| 🟢 小型(< 1GB) | 週更新 | Git + Metadata | 檔名 + Hash + Timestamp,簡單易用,但大檔案難管理 | 低 | 單機即可,速度快,但不適合大檔案 | POC、個人專案、小型內部知識庫 |
| 🟡 中型(1–10GB) | 日更新 | DVC + S3/GCS | 專為大檔案設計,支援 dvc push/pull,整合雲端儲存 |
中 | 支援快取與差分傳輸,效能中等,擴展到多機環境較容易 | 中小企業、團隊協作、定期更新的知識庫 |
| 🔴 大型(> 10GB) | 即時更新 | LakeFS | 讓 S3/GCS 具備版本化,可 branch/merge,適合多人協作 | 高 | 高度可擴展,支援併發存取與 TB/PB 級資料,能即時回滾 | 企業級平台、大型數據湖、多人協作環境 |
worker_manual.txt,內容跟上面的 worker_manual.pdf 一樣)。metadata.json。實作程式碼如下:
# metadata_demo.py
import hashlib
import json
import os
from datetime import datetime
META_FILE = "metadata.json"
def calc_hash(path):
"""計算檔案的 SHA256 hash"""
h = hashlib.sha256()
with open(path, "rb") as f:
h.update(f.read())
return h.hexdigest()
def load_metadata():
"""讀取 metadata.json,如果不存在就回傳空 dict"""
if os.path.exists(META_FILE):
with open(META_FILE, "r", encoding="utf-8") as f:
return json.load(f)
return {}
def save_metadata(meta):
"""儲存 metadata.json"""
with open(META_FILE, "w", encoding="utf-8") as f:
json.dump(meta, f, indent=2, ensure_ascii=False)
def update_metadata(path):
"""更新某個檔案的 metadata"""
meta = load_metadata()
h = calc_hash(path)
ts = datetime.now().isoformat(timespec="seconds")
meta[path] = {"hash": h, "timestamp": ts}
save_metadata(meta)
print(f"已更新 {path} → hash={h[:8]}..., time={ts}")
if __name__ == "__main__":
# 假設 manual.txt 是知識庫檔案
file_path = "manual.txt"
# 如果檔案不存在,先寫一個測試檔
if not os.path.exists(file_path):
with open(file_path, "w", encoding="utf-8") as f:
f.write("公司員工手冊 v1.0\n出勤規範:上班 9-6\n")
# 更新 metadata
update_metadata(file_path)
# 顯示 metadata.json
print("\n目前的 metadata.json:")
print(json.dumps(load_metadata(), indent=2, ensure_ascii=False))
先執行第一次,結果如下:
❯ python metadata_demo.py
已更新 worker_manual.txt → hash=c27e153e..., time=2025-09-26T14:12:14
目前的 metadata.json:
{
"worker_manual.txt": {
"hash": "c27e153e0b1d2a716d6d63c7978983139a825fc7c9adeabfad5bafd815ee5de6",
"timestamp": "2025-09-26T14:12:14"
}
}
任意修改 worker_manual.txt 後再跑:
❯ python metadata_demo.py
已更新 worker_manual.txt → hash=4a723d94..., time=2025-09-26T14:13:03
目前的 metadata.json:
{
"worker_manual.txt": {
"hash": "4a723d94f5b9304aaa990f49903e5f928a7098ecb4802b3dac9ee9af70a22bfa",
"timestamp": "2025-09-26T14:13:03"
}
}
改變的 hash 碼除了會顯示在終端機上,也會另外儲存在本地端的 metadata.json :
❯ cat metadata.json
{
"worker_manual.txt": {
"hash": "4a723d94f5b9304aaa990f49903e5f928a7098ecb4802b3dac9ee9af70a22bfa",
"timestamp": "2025-09-26T14:13:03"
}
}%
在大部分情境下,DVC 幾乎都是 搭配 Git 使用,形成一個「程式碼 + 資料」雙軌版本控管的模式:
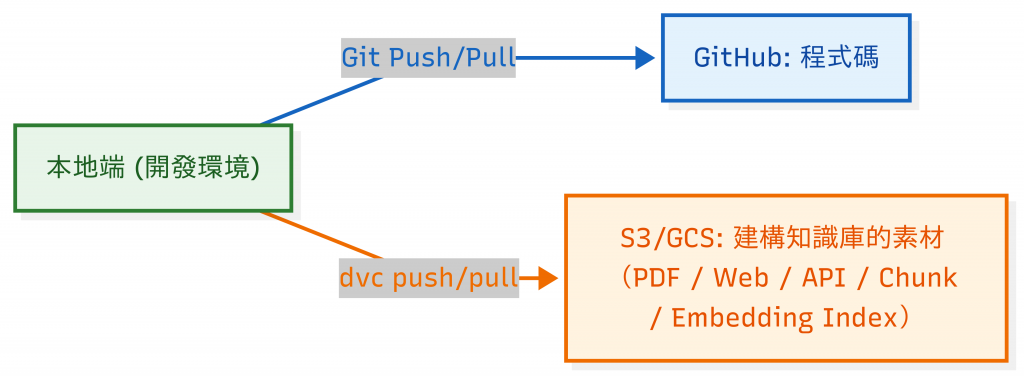
worker_manual.pdf → dvc add → 產生 worker_manual.pdf.dvc
.dvc / dvc.yaml 等 metadata(不含大檔案本身)dvc push 上傳實際檔案內容git clone → dvc pull,即可從 S3 還原對應的資料版本(這邊不做 demo)先安裝 dvc (如果是 gcp 或其他的雲端儲存方案要加上額外的套件):
pip install "dvc[s3]"
# 1. 初始化 DVC
dvc init
# 2. 把 worker_manual.pdf 加進版本控制
dvc add day12_version_control/worker_manual.pdf
# 建立 commit 並且把對應的 dvc 檔案推到 GitHub
git add day12_version_control/worker_manual.pdf.dvc .dvc/config .gitignore
git commit -m "Add day12 worker_manual.pdf v1"
git push -u origin main
# 3. 建立 AWS s3 demo bucket
aws s3 mb s3://day12-dvc-demo-bucket --region ap-northeast-1
# 4. 推到遠端 s3 bucket
dvc remote add -d myremote s3://day12-dvc-demo-bucket/dvc-store # 加一個名為 'myremote' 的遠端,並設為預設 (-d)
dvc remote modify myremote region ap-northeast-1 # 建議設 region,避免預設區域不一致
dvc push
執行結果:
❯ dvc push
Collecting |1.00 [00:00, 970entry/s]
Pushing
1 file pushed
在 s3 上會存成類似這樣的路徑: s3://day12-dvc-demo-bucket/dvc-store/files/md5/51/06549b250c4c06a9bd1e59ab950e8a,這個檔案不能用 s3 命令直接下載,只能用 dvc pull :
❯ dvc pull
Collecting |0.00 [00:00, ?entry/s]
Fetching
Building workspace index |1.00 [00:00, 448entry/s]
Comparing indexes |3.00 [00:00, 1.53kentry/s]
Applying changes |1.00 [00:00, 371file/s]
A day12_version_control/worker_manual.pdf
1 file added
dvc pull 做了什麼?
.dvc metadata(知道 hash 值是多少)worker_manual.pdf
⚠️ 小提醒:
實際部署到團隊環境時,DVC 還需要設定:
- Remote 儲存位置:S3/GCS/Azure Blob
- 權限控管:確保不同人員有正確的讀寫權限
- 安全性:避免把 access key 寫死在 config,建議搭配 IAM Role 或環境變數
- 監控:重要資料操作要有審計日誌(例如誰 push 了新版本)
多來源整合:就像一間圖書館,同時收錄了「紙本書(PDF)」、「雜誌(Web)」、「即時報紙(API)」。
資料版本控制:就像圖書館的「館藏編號 + 出版日期」,你可以清楚知道:
Day 12 的重點:
明天(Day 13),我們將探討 Data Drift 與知識更新:
當文件版本更新,舊知識失效時,如何確保檢索到的內容始終正確?

