完整程式碼可在 GitHub 專案中找到:Finetune-30-days-demo / day-22
在 Day 21,我們讓平台具備了 模型卡與共享 API,但模型與實驗的紀錄依然分散:
results/metrics.json 保存準確率、lossresults/ 資料夾存放 config、log、checkpoints這種做法在一開始能跑,但隨著實驗變多,問題逐漸浮現:
👉 為了解決這些痛點,今天要導入 MLflow Tracking,讓實驗管理走向標準化。
在專案逐漸壯大後,我們需要一套標準化的實驗管理工具,這正是 MLflow 的角色。MLflow 是一個開源平台,提供四大模組:Tracking(實驗紀錄)、Projects(可重現環境)、Models(模型管理)、Registry(模型版本與階段)。今天我們聚焦在 Tracking 功能,它能統一記錄實驗的參數 (params)、指標 (metrics) 與產物 (artifacts),並提供網頁 UI 與 API 查詢。
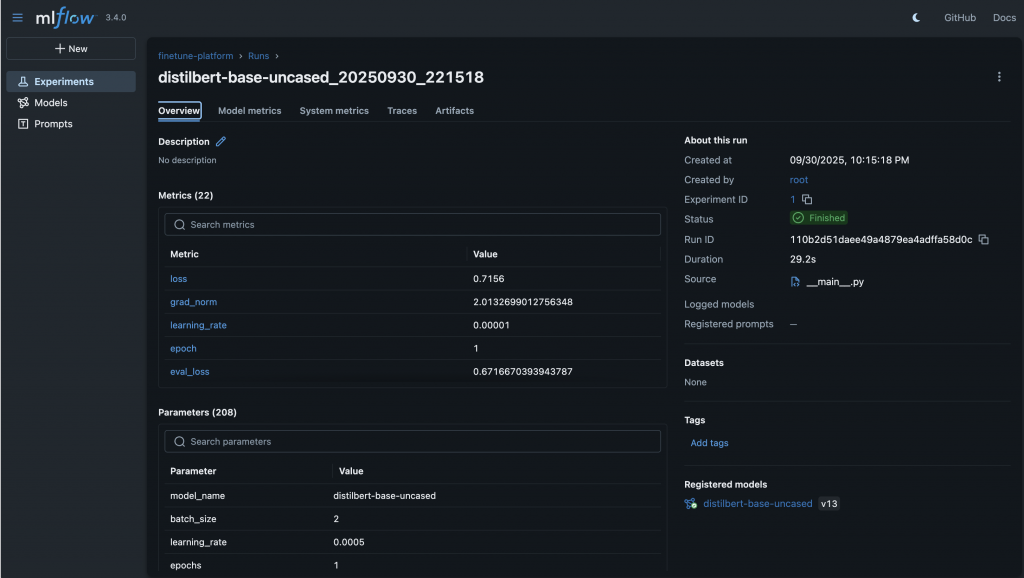
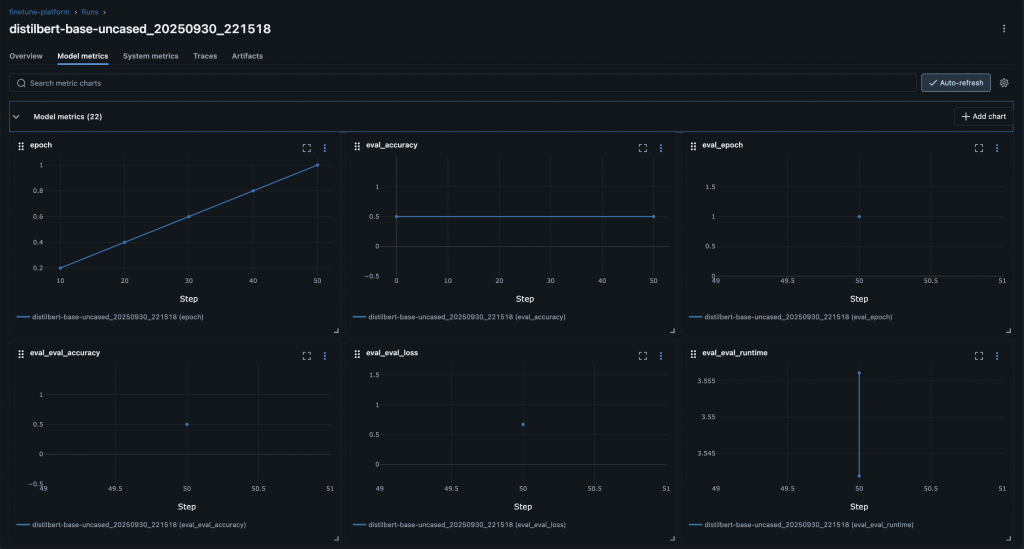
相比我們原本分散在 JSON、DB 與資料夾裡的做法,MLflow 帶來幾個明顯好處:
如果說 Day 14 的測試是保護「功能不會壞掉」,那麼 MLflow 就是保護「實驗不會亂掉」,確保我們能隨時回頭追蹤並驗證研究成果。
首先需要有一個可以集中儲存實驗紀錄的地方。最簡單的方式,是用 SQLite 當後端資料庫並指定 artifact 存放路徑:
mlflow server \
--backend-store-uri sqlite:///mlflow.db \
--default-artifact-root ./mlruns \
--host 0.0.0.0 --port 5000
啟動後,打開 http://localhost:5000 就能看到 MLflow 的網頁 UI。
接著在 train/runner.py 中,把每次訓練的輸入與輸出寫入 MLflow:
import mlflow
with mlflow.start_run() as run:
mlflow.log_params(config) # 超參數
mlflow.log_metrics(metrics) # 訓練與評估結果
mlflow.log_artifacts("results") # 模型與 log 檔案
這樣,每次執行訓練就會在 MLflow UI 中新增一筆 run,包含參數、metrics 與 artifacts,形成完整的實驗紀錄。
為了讓研究人員不一定要進 MLflow UI,也能快速查詢實驗結果,我在 FastAPI 新增了一個 /experiments/mlflow/{run_id} 端點,回傳指定 run 的核心資訊:
{
"run_id": "c5a4f8d1a6e54b3e9c2f1f3d",
"params": { "lr": 0.0005, "batch_size": 8 },
"metrics": { "accuracy": 0.87, "loss": 0.45 },
"artifacts": [
"results/config.yaml",
"results/metrics.json",
"results/model.pt"
]
}
這讓 MLflow 的資料可以被平台 UI 直接利用,而不需要完全跳出到另一個系統。
最後,在 Streamlit 前端新增了一個 **「實驗瀏覽」**分頁:
這樣的設計,讓使用者能先在平台快速瀏覽重點,再進到 MLflow 看到完整的曲線、對比與 artifacts。
導入 MLflow Tracking 之後,實驗紀錄不再零散在 JSON 與資料夾裡,而是統一進入一個標準化的系統。研究人員能在 UI 上即時比對不同 run 的曲線,開發者則能透過 API 撈資料做自動化報告,團隊也能共享結果、減少重複比對與手動整理的負擔。
今天的進度,讓我們的實驗管理正式從「工程自製」走向「標準化工具」。有了這個基礎,平台不僅更透明,也更容易協作。接下來的 Day 23,我們會進一步導入 MLflow Model Registry + DVC,讓模型與資料能隨時被回溯、升降版與回滾,將治理能力再提升一個層級。
📎 AI 協作記錄:今日開發指令
請幫我針對專案做以下開發與修改:
1. 新增 MLflow Tracking 設定
- 建立檔案:src/core/mlflow_config.py
- 內容:初始化 MLflow Tracking,設定 tracking_uri(預設 http://mlflow:5000),實驗名稱預設 "finetune-platform"。
2. 修改訓練程式接入 MLflow
- 檔案:src/train/runner.py
- 訓練開始時 → 建立 run (mlflow.start_run)
- log_params:batch_size, learning_rate, epochs, model_name
- 每個 epoch → log_metrics (accuracy, loss, runtime)
- 訓練結束後 → mlflow.log_artifacts (config.yaml, logs, final_model/)
3. 修改評估程式接入 MLflow
- 檔案:src/train/evaluator.py
- 評估完成後 → mlflow.log_metrics({"eval_acc": ..., "eval_loss": ...})
4. 新增 API 查詢端點
- 檔案:src/api/routes/mlflow.py
- 新增 GET /experiments/mlflow/{run_id}
- 使用 mlflow.get_run(run_id) 查詢 params、metrics、artifacts_uri
- 回傳 JSON 結果
5. 新增 Streamlit UI 分頁「Experiments」
- 檔案:src/ui/pages/experiments.py
- 顯示最近的 run_id, model_name, accuracy, runtime
- 每列提供「查看詳細」按鈕,連結至 MLflow Web UI (http://localhost:5000)
6. 更新 Docker Compose,新增 MLflow Tracking Server
- 檔案:docker-compose.yml
- 新增服務 mlflow:
image: ghcr.io/mlflow/mlflow:latest
ports:
- "5000:5000"
volumes:
- ./mlruns:/mlruns
command: mlflow server --backend-store-uri sqlite:///mlflow.db --default-artifact-root /mlruns --host 0.0.0.0


 iThome鐵人賽
iThome鐵人賽