
DynamoDB 雖然是 Serverless 架構中高效能、低延遲的 NoSQL 資料庫,但若僅依賴單一主鍵(Partition Key + Sort Key)存取資料,查詢彈性有限。
當應用程式需要不同查詢角度時,就需要用到 **本地二級索引(LSI)和全域二級索引(GSI)**來最佳化查詢效率,避免濫用 Scan 導致成本高昂與效能下降,簡單來說,這個架構的用意就是教導開發者:「**如何以正確且高效的方式,從 DynamoDB 中取出資料,而非只是將資料存入」,**此 Lab 是針對以下痛點做出改善:
(1) 直接使用 Scan 會遍歷整個資料表,效能低且成本高,不適合大規模系統。
Scan 操作會遍歷整個資料表,無論您只想要查詢幾筆資料。這對於大型資料表來說,不僅會導致極高的延遲,還會消耗大量的讀取容量單位(RCU),從而產生高昂的費用。Scan 操作轉換為 Query 操作。Query 只會查詢索引中的一小部分資料,這讓查詢速度快了數千倍,並且大大降低了成本。(2) DynamoDB 的設計雖強調 Partition Key,但實際應用中常需要不同查詢角度(例如依使用者 ID 查詢,也可能依 Email 查詢),實現多維度的查詢彈性。
UserID 查詢,也可能需要根據 Email 查詢,甚至需要依 使用者狀態 查詢。(3) 缺乏索引設計會導致應用程式需在 Lambda 端進行大量過濾,增加延遲與計算成本,故需要減輕 Lambda 的計算負擔。(同第一點)
Scan,然後在程式碼中過濾出您需要的資料。這會消耗大量的 Lambda 運算資源,增加延遲,並讓 Lambda 函數的程式碼變得複雜。💡在 Serverless 架構中,DynamoDB GSI 與 LSI 可讓應用程式快速依不同條件存取資料,減少 Lambda 的負擔,並保持高可擴展性。
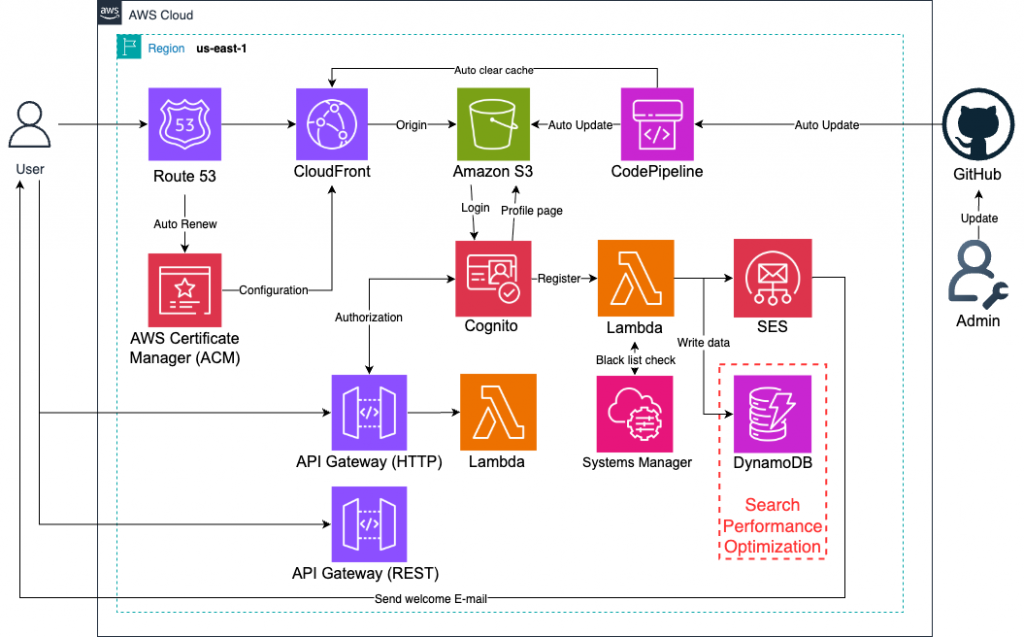
(1) Amazon DynamoDB:主要存放會員與應用資料,支援高效能查詢。
(2) Global Secondary Index (GSI):允許使用不同 Partition Key + Sort Key 查詢資料。
(3) Local Secondary Index (LSI):在相同 Partition Key 下提供額外的 Sort Key 查詢維度。
(4) AWS Lambda(選用):可用於示範應用程式層查詢資料並回傳給前端。
(5) Amazon CloudWatch:監控 Query 與 Scan 的效能與 RCUs/ WCUs 消耗。
(1) 優先使用 Query,避免大量 Scan,降低成本與延遲。
(2) GSI 適合跨 Partition Key 查詢(例如 Email、OrderID),LSI 則適合同一使用者不同維度查詢(例如不同狀態)。
(3) 規劃索引時要平衡效能與儲存成本,每個索引都會增加寫入成本。
(4) 搭配 CloudWatch Metrics 與 DynamoDB Auto Scaling,動態調整 RCU/WCU,避免過度 Provisioning。
★ LSI(本地二級索引)和 GSI(全域二級索引) 的建立方式是不同的:

無
💡該Lab會重新創建一個新的DynamoDB,單純測試LSI及GSI,因為筆者沒有先見之明,之前在Day9就沒有讓Cognito user在註冊時勾選其他項目,做註冊,故無其他索引可以供篩選。
進入「DynamoDB」頁面。
創建一個新的資料表。
設定資料表分區索引鍵為「UserID」,排序索引鍵為「CreatedAt」。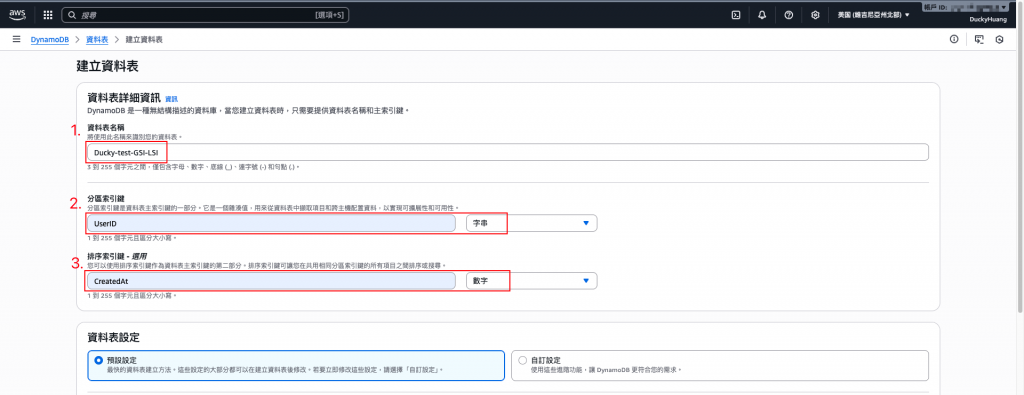
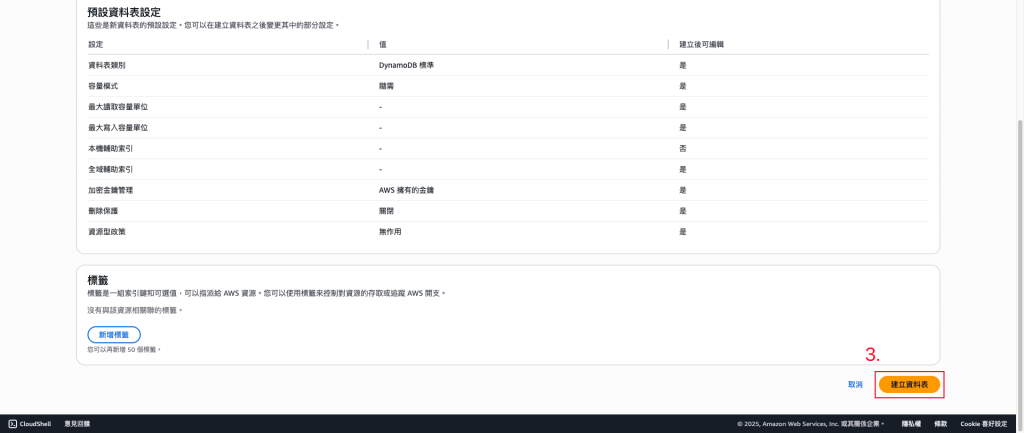
創建完成畫面。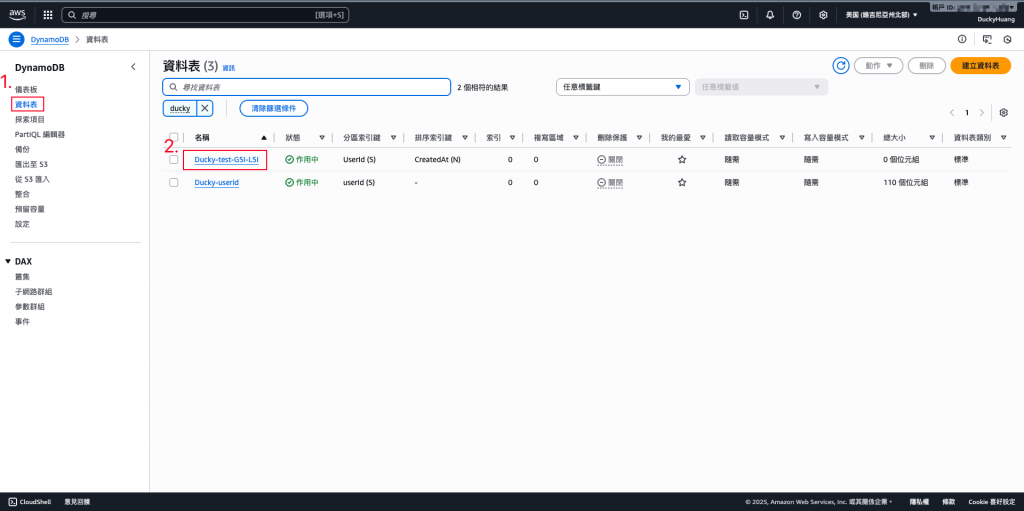
進到剛剛創建的「DynamoDB」資料表中。
新增索引。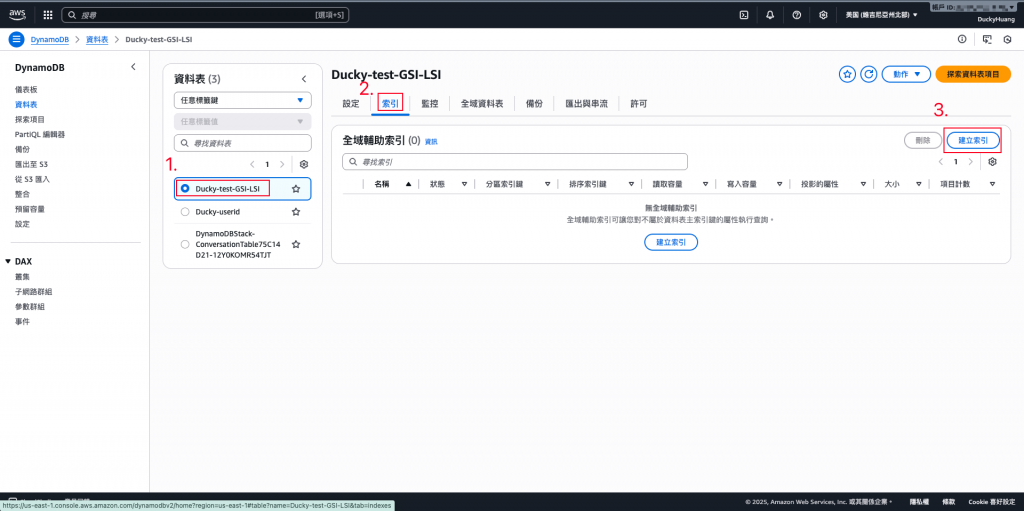
設定資料表分區索引鍵為「UserID」,排序索引鍵為「Status」。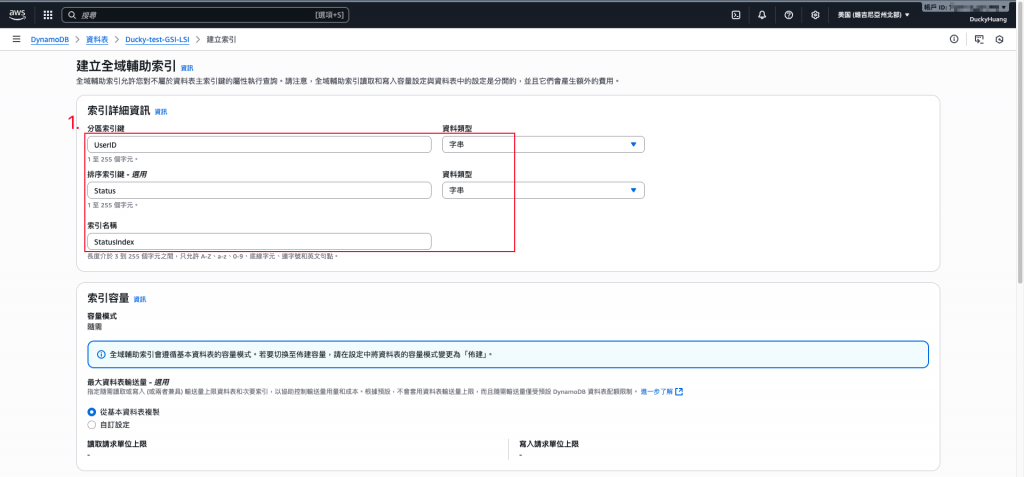
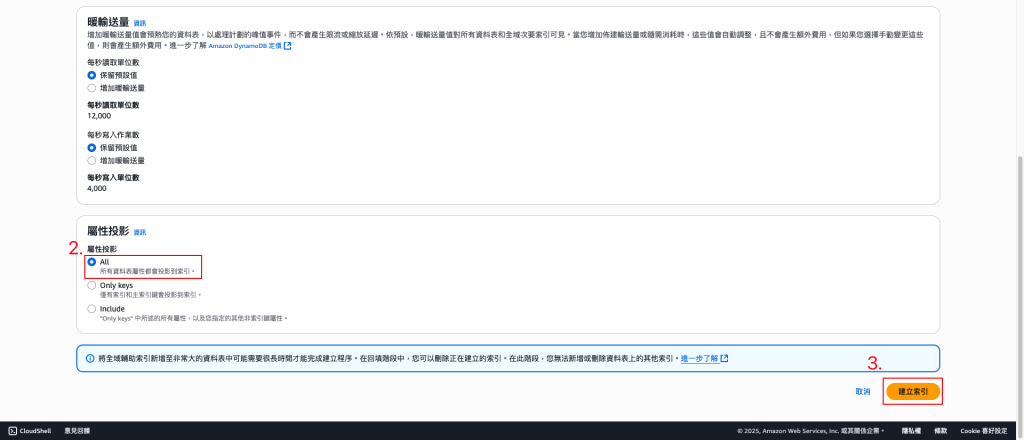
💡要等到前一個「索引」建立完成才能再創建新的,不然會報錯!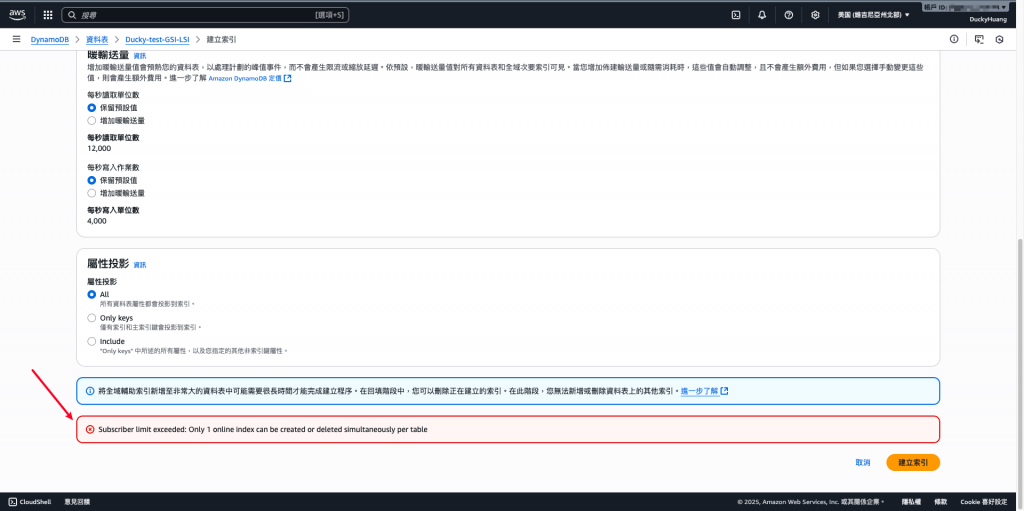
再新增一個索引。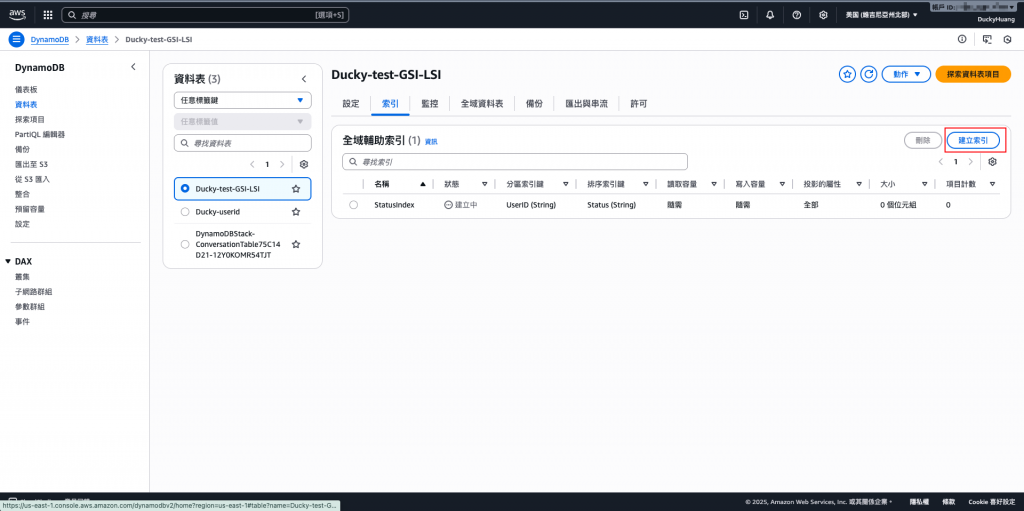
設定資料表分區索引鍵為「Email」,排序索引鍵為「CreatedAt」。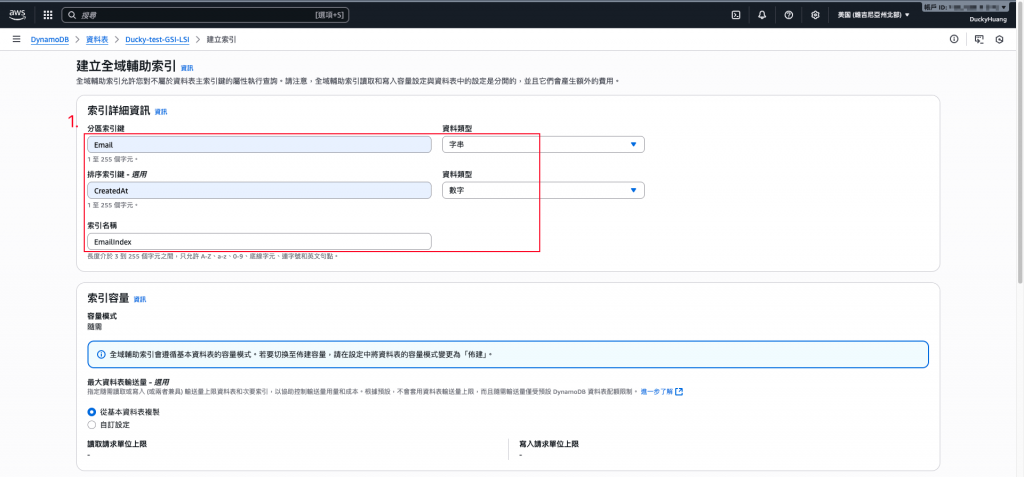
打開AWS CLI。
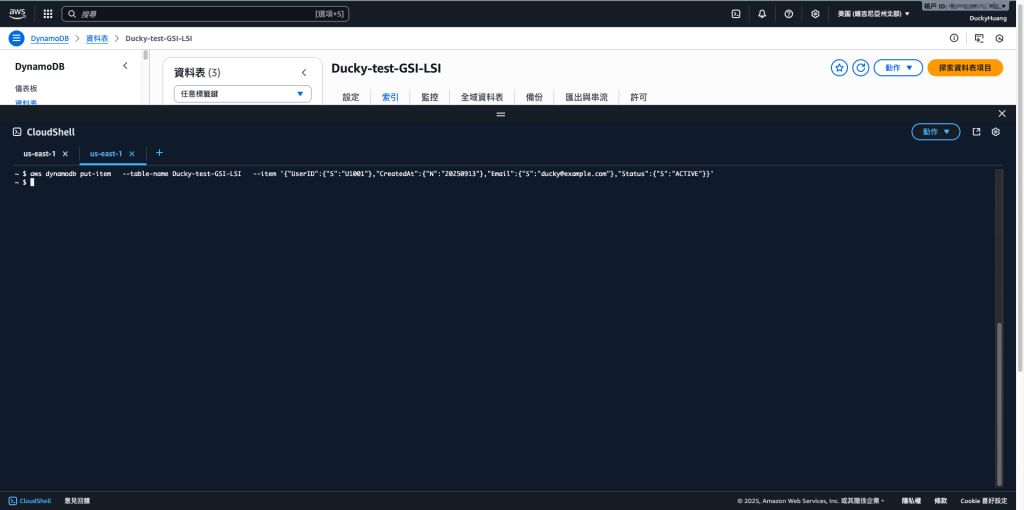
插入測試用資料。
範例程式碼
aws dynamodb put-item \
--table-name Users \
--item '{"UserID":{"S":"U1001"},"CreatedAt":{"N":"20250913"},"Email":{"S":"test@example.com"},"Status":{"S":"ACTIVE"}}'
範例程式碼
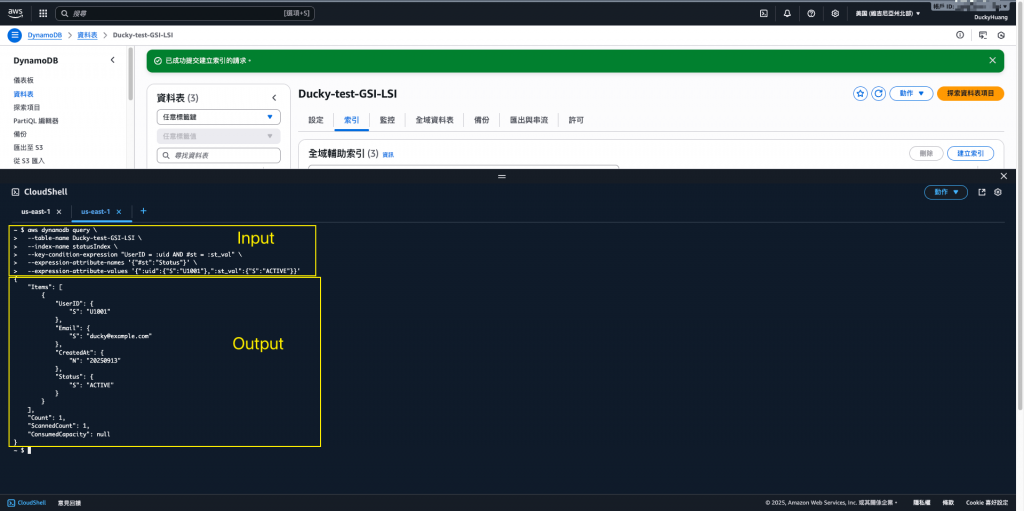
aws dynamodb query \
--table-name Users \
--index-name StatusIndex \
--key-condition-expression "UserID = :uid AND #st = :st_val" \
--expression-attribute-names '{"#st":"Status"}' \
--expression-attribute-values '{":uid":{"S":"U1001"},":st_val":{"S":"ACTIVE"}}'
範例程式碼
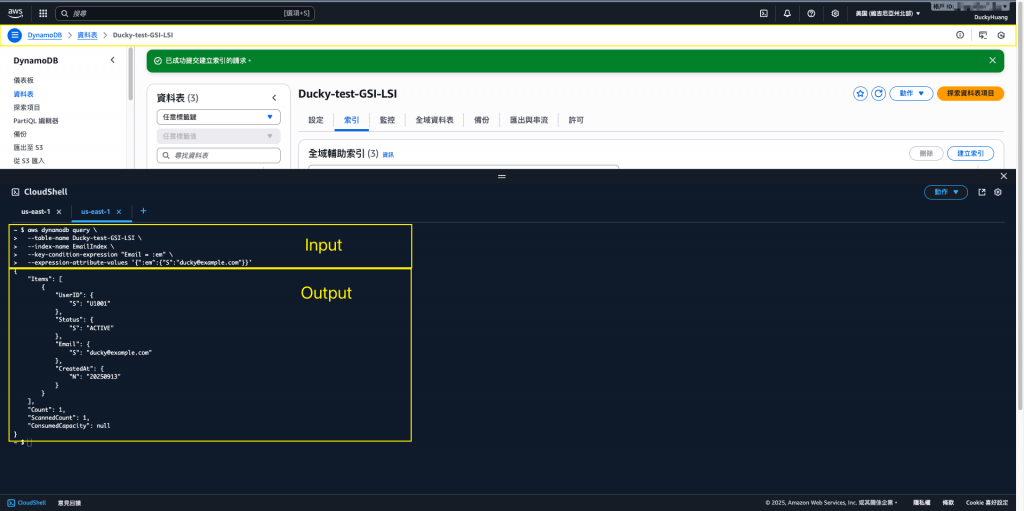
aws dynamodb query \
--table-name Users \
--index-name EmailIndex \
--key-condition-expression "Email = :em" \
--expression-attribute-values '{":em":{"S":"test@example.com"}}'
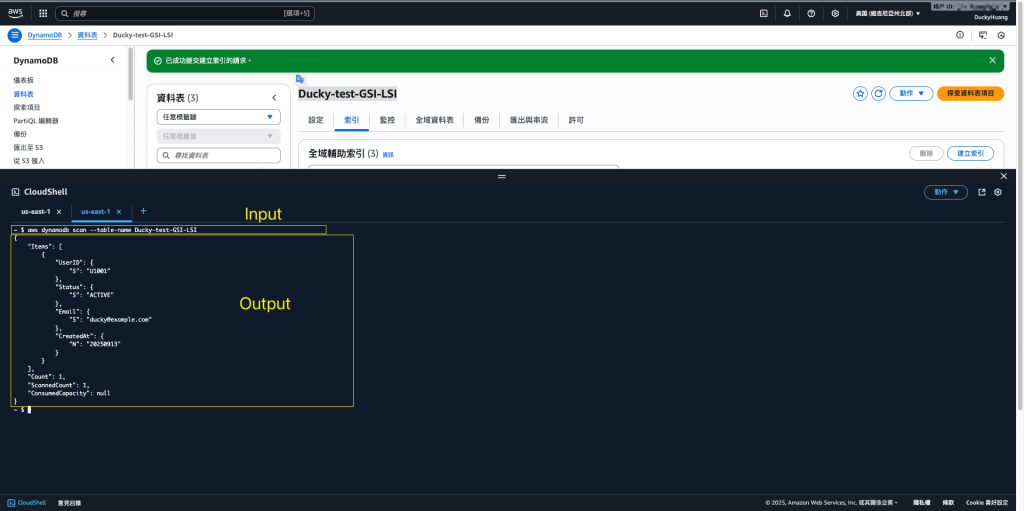
💡如果資料較多這個指令會需要全數掃描過資料庫裡的所有資料,故效率較低。觀察 Scan 的 RCUs 消耗與延遲,對比 Query 效率。
範例程式碼
aws dynamodb scan --table-name Users
本 Lab 示範如何透過 GSI / LSI 提升 DynamoDB 查詢效率,並比較 Query 與 Scan 的差異,關鍵學習點在於:

