在專案管理界中,有一句經典名言:「問題都不是突然發生的,而是突然被發現的。」
白話文的意思是,徵兆其實早就存在,但團隊沒有人「看到」。
有些人不敢講,有些訊號被忽略,有些進度報告寫得模模糊糊,最後大家只好又再次掉入「怎麼到現在才發現?」的無間道之中。
風險表好像你放在辦公室窗邊的盆栽:Kick-off 那幾個禮拜大家都看過,之後就再也沒人理它,直到你離職前才發現它乾枯。
傳統上,PM 都被前輩們教說要做風險控管:預先發現風險、制定應對計畫。聽起來很完整,但在實務上卻常常變成:
於是,PM 的日常更像是消防員,而不是領航員。專案一路走到問題爆炸,大家才一窩蜂滅火,卻沒有人在乎為什麼火苗一開始沒被看見。
如果要跳脫這個無間輪迴,風險管理必須從事後發現轉向前期預測。我們需要的是一個風險雷達—不等火燒起來才救,而是在訊號逐漸變大時就能捕捉。
除了風險表更新頻率低,實際上跟不上專案日常變化之外,在例行會議裡,風險討論常常被草草帶過。另外,靠 PM 經驗判斷雖然重要,但這代表風險管理的品質完全取決於 PM 個人的經驗與視野。
換句話說,傳統方法的資訊收集太被動,也太仰賴「人要誠實講出來」。問題是,在真實世界的團隊裡,不是每個人都願意講出那些可能帶給他自己麻煩的話。
AI 在這裡能做的事,不是取代 PM,而是幫忙處理那些日常累積下來的「訊號噪音」。
這些工作如果交給人,耗時又乏味。但 AI 不會喊累,所以我們可以壓榨它,讓 PM 把注意力放在「判斷與決策」上。這就是風險雷達的核心觀念:AI 幫你把訊號放大,PM 幫團隊決定要怎麼應對。
專案週報的時候很容易有貓膩,尤其是那句「80% 已完成」。
在專案管理界中,「80%」 永遠是個進可攻退可守的數字,因為它既不代表快完成,也不代表還差多少。只要給出這個漂亮數字,你就不太會被 PM 問細節,多好?
不過,80% 的通常真心話是:「我們卡住了,但又不好意思明說」。
我們可以在 NotebookLM 中下 Prompt 協助我們追問:
就勾選的 Weekly Report 文件中,請你幫我標記其中任何模糊或可能隱含風險的工作項目及進度
請將這些句子轉換成具體的追問問題,方便我詢問該項的負責人。
##輸出格式##
- 原句
- 推論可能風險
- 建議追問問題
如果是會議錄音(記得要事先告知並取得同意,比較尊重大家),NotebookLM 也可以上傳錄音檔轉逐字稿,之後我們只要勾選該錄音檔,並輸入以下 Prompt:
這是週報的會議內容,請找出成員講話中任何不確定的語氣(如「可能吧」「應該行」「再看看」)。
幫我整理成需要澄清的風險點,並建議我下一步該怎麼追問。
##輸出格式##
- 原句
- 推論可能風險
- 建議追問問題
這樣,原本模糊的訊息就能立刻變成具體問題,讓 PM 可以盡快私下追問,以避免模糊帶過,導致錯過了辨識出風險的機會。
專案週報如果只看單一週,很難發現「沒動的地方」。NotebookLM 可以一次讀兩份文件(例如上週 vs 本週),幫你做出差異比對。
例如,我們可在 NotebookLM 中下 Prompt:
你現在是在 {{領域}} 有10年經驗的風險顧問,根據勾選的這兩份文件做分析:
1. 哪些項目有明顯進展?
2. 哪些項目停滯或沒有更新?
3. 哪些描述看起來存在風險(需求再變更、延遲未解釋、相同問題反覆出現)?
給我三到五點具體建議,指出我應追問或介入之處。
##輸出格式##
-表格
-欄位為:進展|停滯|風險徵兆|顧問建議
這時候,你得到的就會是一份「吹哨者提醒清單」,幫你點出可能需要追問的問題。
有了差異分析與風險點,如果還是堆成一份文件,團隊會議上很快又被一堆文字淹沒。這時候就需要一個一眼就懂的儀表板。
先用 NotebookLM 產出結構化的資料 (by JSON)
請彙整資料(差異分析、逐字稿澄清點、匿名回饋),產出「風險雷達總覽」的 JSON。
##要求##
-三層級:high, medium, low,各層最多 5 條
-每條欄位:title, clue, next_step, owner, due
-metadata:generated_at, data_sources
-直接輸出 JSON,前後不需解釋
##資料##
//貼上差異分析與風險點的內容
你會得到類似以下的 JSON:
{
"metadata": {
"generated_at": "2025-10-01",
"data_sources": ["weekly_report_2025-09-24.pdf", "meeting_transcript_2025-09-29.txt"]
},
"high": [
{
"title": "[PROJ-142] API v2 規格未凍結,導致開發重工風險",
"clue": "後端與設計討論中再度新增欄位,影響既有 endpoint 實作",
"next_step": "PM 安排 Spec Freeze 會議,會後產出正式版並上傳 Confluence",
"owner": "PM/Backend Lead/UI Lead",
"due": "2025-10-03"
},
{
"title": "[DB-327] 資料庫查詢壓測延遲過高",
"clue": "壓測顯示高峰期 read query > 1.5s,且 CPU 使用率長期超過 85%",
"next_step": "DBA 提出分片或快取策略並提交 POC",
"owner": "DBA/Backend Lead",
"due": "2025-10-05"
}
],
"medium": [
{
"title": "[QA-210] 測試人力不足影響回歸進度",
"clue": "本週僅 1 名 QA 可支援,另有兩人休假交疊",
"next_step": "提出臨時人力需求或縮減驗收範圍",
"owner": "QA Lead",
"due": "2025-10-04"
},
{
"title": "[INFRA-88] CI/CD pipeline 間歇性失敗",
"clue": "部分 build job timeout,需手動 rerun 才能通過",
"next_step": "Infra Team 檢查 runner 資源與 GitLab job 設定",
"owner": "Infra Lead",
"due": "2025-10-06"
}
],
"low": [
{
"title": "[DESIGN-57] 設計稿與前端命名規則落差",
"clue": "樣式標註與 SCSS class name 不一致,造成 FE 開發混淆",
"next_step": "Design Ops 與 FE Lead 建立命名對照表,下個 Sprint 開始套用",
"owner": "FE Lead/Design Ops",
"due": "2025-10-07"
},
{
"title": "[DOC-45] 內部 Wiki 缺少最新 UI 截圖",
"clue": "使用者操作文件仍使用 v1.3 的舊版介面截圖",
"next_step": "Design Ops 更新 Wiki 並附 changelog",
"owner": "Design Ops",
"due": "2025-10-08"
},
{
"title": "[CS-19] 使用者回饋未即時同步 backlog",
"clue": "客服收集的回饋單未能自動建立 Jira ticket,需人工補建",
"next_step": "PM 與 CS 共同建立回饋 triage 流程,每週檢視一次",
"owner": "PM/CS Lead",
"due": "2025-10-09"
}
]
}
接著,再用 ChatGPT / Gemini / Claude 建立 Dashboard 的視覺化。
例如,我們可以用 ChatGPT,寫以下 prompt:
你將收到專案風險資料(by JSON),請依此產出 33 號遠征隊的風險儀表板的視覺化網頁。
請注意版面易讀性及要求
##版面與可讀性##
-頁首:標題「33 號遠征隊風險雷達 Dashboard」
-三個區塊:高風險(紅色)、中風險(黃)、低風險(綠)
-每條風險以卡片顯示
-風險層級以色塊與小圓點標示(紅/黃/綠)
-RWD:手機/投影皆可讀;可列印(print-friendly)
##要求##
-用一般人能存成html,就可直接在瀏覽器中觀看的方式:
-內嵌 CSS
-用原生 Javascript
-要能支援中文編碼
-讓json檔在最前面,方便我之後只更新新的資料,就能重覆使用這個版型
-在網頁的最下方,讓使用者可以直接貼上json檔,整個頁面就可以重新依據新的資料更新
##JSON##
//貼上上一步 NotebookLM 輸出的 JSON
這樣一來,你就會得到了一個單檔的網頁,下載後點二下就可以在瀏覽器中打開:
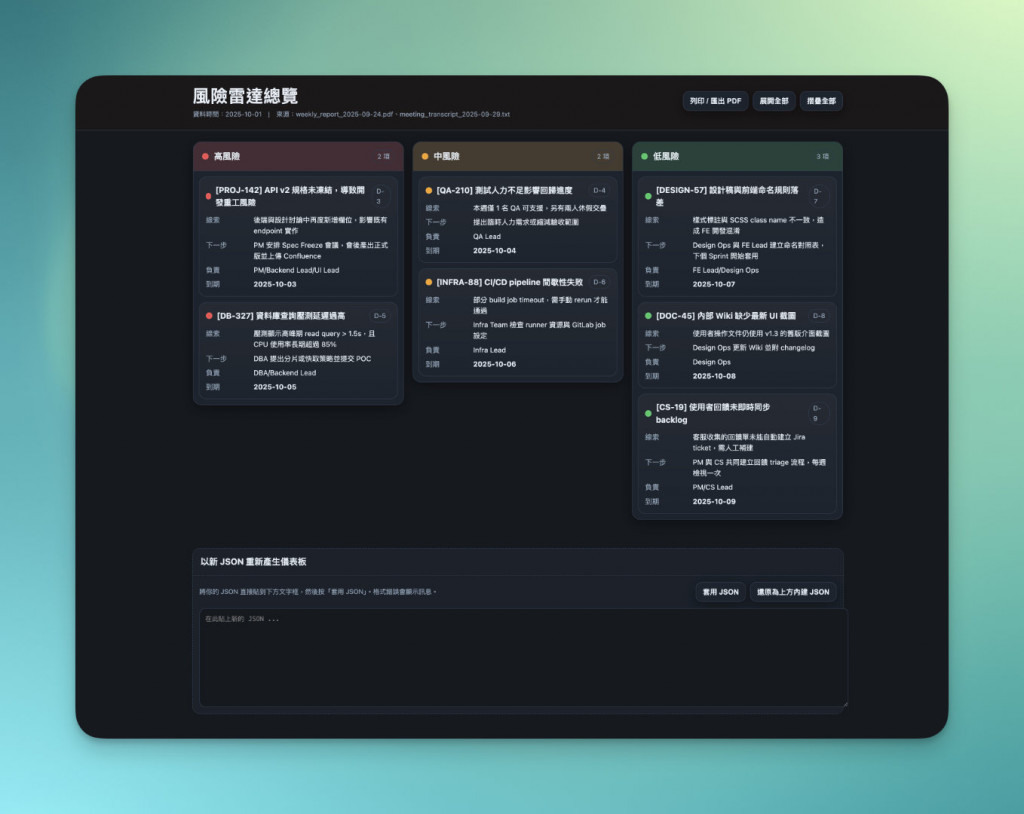
之後,未來在每週會議更新時,只要把新的資料內容丟到 JSON 欄位中,點擊更新,Dashboard 的版型不用重建,就能立刻生成新版的風險雷達。
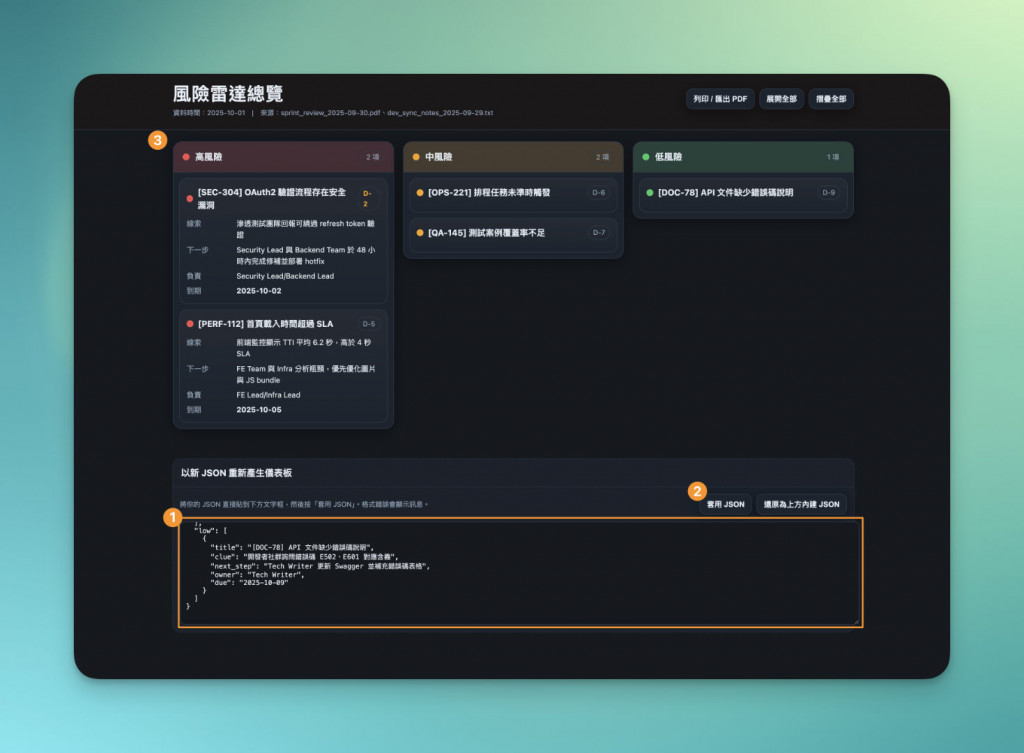
使用這套方法,流程其實可以變成一種固定工作流:
不用再做 ppt,不用在會議裡說破嘴。直接打開 Dashboard ,團隊就可直接看到紅黃綠燈,直觀地「看」到潛在的風險小火苗。
AI 幫你把雜訊變成訊號,把逐字稿變成總結,把週報差異變成顧問建議。但最後能不能真的避開風險,還是取決於 PM:你要不要把這些訊號帶進討論,會不會造成衝突?該如何就事論事防範風險,讓團隊採取行動?這些都是身為「人」的價值。
好的 PM,不是在火災後把火滅掉,而是讓火苗根本燒不起來。這才是真的有在做風險管理。

