這其實是個在 AI 時代才產生的、新型態的風險,需要被小心管理。
在過去,身為知識工作者,我們最大的挑戰或許是資訊不足,得大海撈針般地從零散的報告和數據中尋找答案。但現在,情況恰恰相反。我們面臨的,不再是資訊的不夠,而是由 AIGC 生成出過多看似專業、實則可能有誤的資訊。
以下是 PM 小森夢到的:
某天,在一場重要規劃會前,小森用 AI 快速做市場與競品分析,做出了一個漂亮報告;開會時自信地簡報「競品上線時程預測」。結果,技術總監指出這裡所假設的 OOXX 技術,其實已在上個月就公開棄用…
瞬間,全場尷尬,PM 當場臉很腫。
此時小森才深刻意識到:AI 帶來的效率,背後可能是巨大的風險。
AI 犯的錯,我們得背鍋。你又不能在會議上說:「這不是我的錯,是 AI 說的結論。」這就像一個居上位的團隊 Leader 說:「這不是我的問題,是我 Member 做的」一樣不專業。
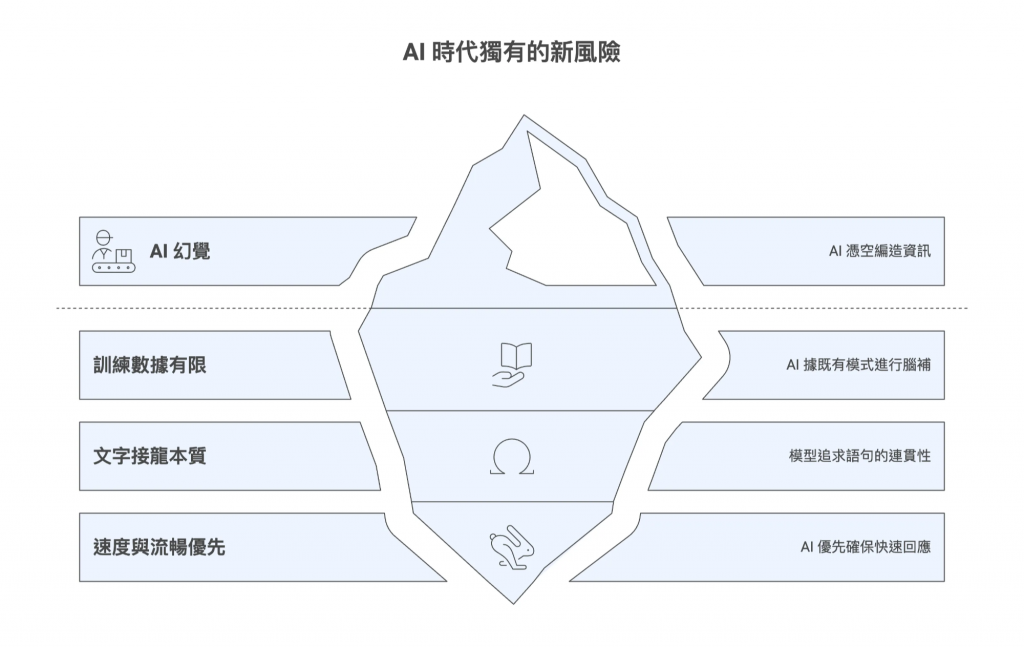
這帶出了在新時代中,所有知識工作者都必須面對的新樣態風險- AI 幻覺
幻覺這個問題,不在於 AI 它不知道,反而在於它誤以為自己知道,太過自信地胡說八道。
要避免被 AI 誤導,首先就得要先理解它為什麼會創造出錯誤的回應資訊,也就是所謂的「AI 幻覺」(Hallucination)。這並非 AI 有意欺騙,而是被其底層技術機制天生所限制住的。
簡單來說,大型語言模型(LLM)的本質不是一個擁有知識、能夠真的「理解」世界的生命智慧體,而是一個極其複雜的「文字接龍機」。它的核心任務,是在給定一段文字後,預測下一個最可能出現的詞是什麼,然後一個詞一個詞地串連下去,組成流暢、看似合理的句子。
它的訓練目標是形成說服力與流暢度,而非絕對真實。這個根本性的差異,導致了幾種常見的風險:
之所以會形成這些問題,其背後的成因,主要有三點:
因此,當我們在會議上無腦引用 AI 的內容,實際上引用的可能只是「一段非常流暢的胡說八道」。
理解了 AI 的本質只是個「很會接話的模仿人類大師」的原理後,我們該從根本上對它的所有回答,都抱持一種預設的懷疑。
有些人會想:「我以前查資料也會交叉比對,這不就是同一回事嗎?」但 AI 的挑戰,跟傳統 Google 搜尋完全不同。
過去,我們的流程是:Google 搜尋 → 瀏覽一排藍色連結 → 點開幾個權威來源 → 交叉比對真偽。 在這個過程中,我們的大腦天生就處於一種「篩選、質疑」的模式。
但發展至今,太過聰明的 AI ,如今早已改變了這個遊戲規則,帶來了新的挑戰:
因此,只靠過去的「常識 + 搜尋」已經遠遠不夠。我們必須建立一套全新的、為 AI 時代量身打造的驗證流。
既然 AI 的錯誤難以無法避免,我們就要建立一套新的認知守備,讓自己在接收 AI 回答時,預設就啟動「專業的懷疑論者」這種偏激人設。
三道心智防線,就像是進擊的巨人中的三道城牆,層層守護住我們的判斷:
來源真實性
檢查來源是否真的存在,網址能否點開,報告是否能找到。
來源可信度
官方網站、學術論文、權威媒體的可信度,高於討論區中的鄉民留言。
資訊時效性
這份資料是三年前的新聞,還是三天前的報告?在高速變化的產業裡,這往往很關鍵。
同時,也要警覺以下常見的認知偏誤:

不得不說,AI 的產出很高效,但其錯誤往往更隱蔽、更難以察覺。正因如此,我們必須將「AI 內容識讀」視為與「媒體識讀」同等關鍵的基礎底層能力。

