pip install llama-index-llms-ollama
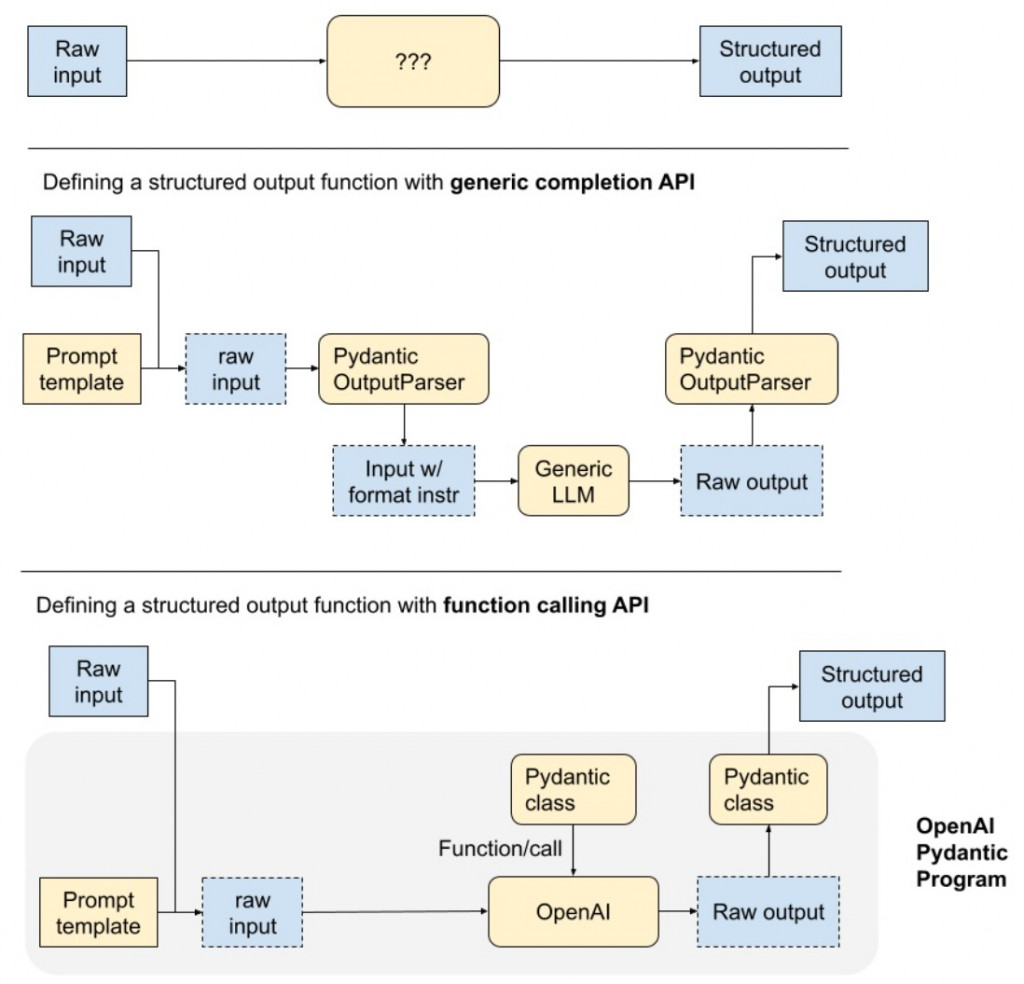
首先是最上面,我們直接 prompt 它,要他出 json
然後是中間,generic completion API
This is notably less reliable, but supported by all text-based LLMs.
最後就是支持 function calling API 的 model
我們就是在呼叫 llm 的時候把 tool 給他,API 會幫我們處理 json 的事情
我們在 Day14 實作的 FunctionAgent 就是這種
chat_with_tools 然後把 tool 給他釐清: 在本系列文中,tool calling 與 function_calling 我們視為同義
釐清: function/tool calling 與 JSON mode 的差異
那是不是全用 function calling 就好了?
我們的目標:
In God we trust. All others must bring data.
import pydantic # pip show pydantic
print(f"our pydantic version: {pydantic.VERSION}")
from pprint import pprint
from typing import List, Optional, Tuple
from pydantic import BaseModel
from pydantic import Field
class Options(BaseModel):
"""單選題的選項物件,包含 A, B, C, D 四個選項"""
A: str = Field(..., description='選項A')
B: str = Field(..., description='選項B')
C: str = Field(..., description='選項C')
D: str = Field(..., description='選項D')
class MCQ(BaseModel):
"""單選題結構,包含題號、題幹、選項與答案"""
qid: int = Field(..., description='題號')
question: str = Field(..., description='題幹')
options: Options = Field(..., description="本題的四個選項")
ans: Optional[str] = Field(default=None, description='答案')
class Meta(BaseModel):
"""試題原始資訊,包含 年分、科目、第幾次考試"""
year: Optional[int] = Field(default=None, description='第?年')
subject: Optional[str] = Field(default=None, description='科目名稱')
times: Optional[int] = Field(default=None, description='第?次考試')
class ExtractExam(BaseModel):
"""
提取整份考卷
- qset: 單選題考題集合
- subject: 科目名稱
- year: 考試年分
- times: 第幾次考試
"""
qset: List[MCQ] = Field(..., description='單選題考題')
metadata: Meta = Field(..., description='考題資訊')
schema = MCQ.model_json_schema()
pprint(schema)

3.0. 我們的 pydantic version 是 2.11.9(提醒:v1 和 v2 在 API 上有些差異)
3.1. 創建 Pydantic class , 就直接繼承 BaseModel: MCQ(BaseModel)
3.2. 一般型別就直接標註(int, str): qid: int
3.3. 嵌套的使用我們的 models: qset: List[MCQ]
3.4. 使用 docstring(""" """): 讓 llm 更容易理解結構
3.5. 使用 Field(..., description=): 一個是預設值,一個是描述
3.6. 用.model_json_schema() 轉成 json schema: 這就是你要塞進 prompt 的規格文件。
3.7. 釐清以上之後: 以後我們就請 chat-gpt 幫你寫就好,這個他真的很會
from llama_index.readers.file import PDFReader
from pathlib import Path
import time
file_path = Path("./data/114_針灸科學.pdf")
FULL_DOCUMENT=False
pdf_reader = PDFReader(return_full_document=FULL_DOCUMENT)
documents = pdf_reader.load_data(file=file_path)
print(f"len of documents: {len(documents)}")
text = documents[0].text
print(f"text len: {len(text)}")
print('---')
print(text)

pypdf source_code
data/114_針灸科學.pdf 路徑下有載好的 pdf 考題return_full_document 設 False 這樣就會分頁讀成 documentfrom llama_index.core.program.function_program import get_function_tool
exam_tool = get_function_tool(ExtractExam)
print(f"# tool info: ")
print(f"# name: {exam_tool.metadata.name}\n\n# description: {exam_tool.metadata.description}")
print('---')
# pip install llama-index-llms-ollama
from llama_index.llms.ollama import Ollama
llama = Ollama(
model="llama3.1:8b",
request_timeout=120.0,
context_window=8000,
temperature=0.0,
)
start = time.time()
resp = llama.chat_with_tools(
[exam_tool],
user_msg="請從下列文本中提取考試: " + text,
tool_required=True, # can optionally force the tool call
)
end = time.time()
print(f'dur: {end-start:.2f} sec')
tool_calls = llama.get_tool_calls_from_response(
resp, error_on_no_tool_call=False
)
print(f"type: {type(tool_calls)}, len: {len(tool_calls)}, dtype: {type(tool_calls[0])}")
print('---')
pprint(tool_calls[0].tool_kwargs)
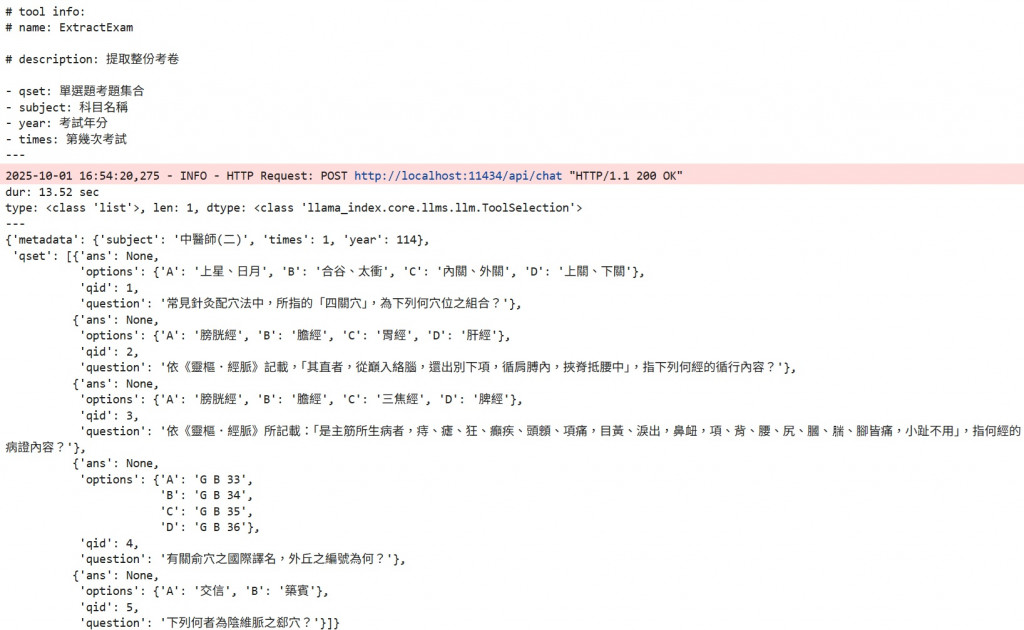
ExtractExam,你被強迫使用它Exam 就好了,這邊定 ExtractExam 就是比較好想像為什麼 structured output 就是 function callingchat_with_tools 呼叫,這個我們之前也有做過MCQ
mcq_tool = get_function_tool(MCQ)
print(f"# name: {mcq_tool.metadata.name}\n\n# description: {mcq_tool.metadata.description}")
start = time.time()
resp = llama.chat_with_tools(
[mcq_tool],
user_msg="你是一個無情的考題提取機器,負責從文本中盡可能多的提取 MCQ,以下是文本資訊:" + text,
tool_required=True, # can optionally force the tool call
allow_parallel_tool_calls=True,
)
end = time.time()
print(f"dur: {end - start:.2f} sec")
tool_calls = llama.get_tool_calls_from_response(
resp, error_on_no_tool_call=False
)
print(f'len of tool_call: {len(tool_calls)}')
print('---')
for tool_call in tool_calls:
pprint(tool_call.tool_kwargs)
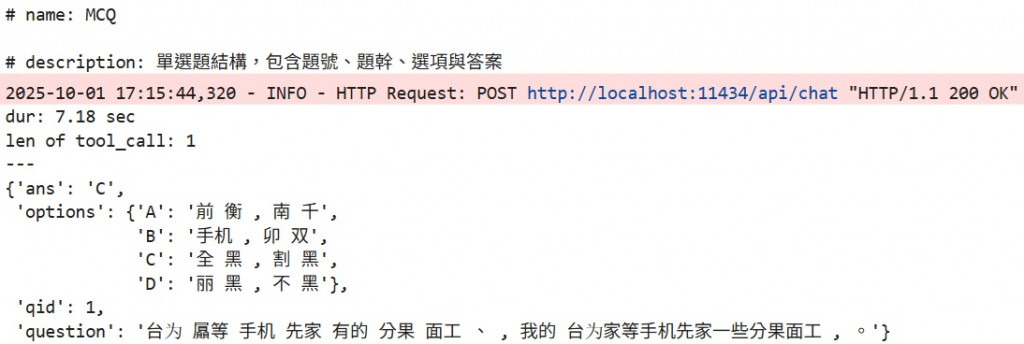
gpt-5-mini 來看一下 allow multiple tool calls 是不是壞了print(f"# name: {mcq_tool.metadata.name}\n\n# description: {mcq_tool.metadata.description}")
import os
from dotenv import find_dotenv, load_dotenv
_ = load_dotenv(find_dotenv())
from llama_index.llms.openai import OpenAI
mini = OpenAI(model="gpt-5-mini")
start = time.time()
resp = mini.chat_with_tools(
[mcq_tool],
user_msg="你是一個無情的考題提取機器,負責從文本中盡可能多的提取 MCQ,以下是文本資訊:" + text,
tool_required=True, # can optionally force the tool call
allow_parallel_tool_calls=True,
)
end = time.time()
print(f"dur: {end - start:.2f} sec")
tool_calls = mini.get_tool_calls_from_response(
resp, error_on_no_tool_call=False
)
print(f'len of tool_call: {len(tool_calls)}')
print('---')
for tool_call in tool_calls:
pprint(tool_call.tool_kwargs)

前面用的都是第一段講的第三種方法,我們現在要回到第 1 種就是直接 prompt 他,因為我們要改用 gemma3
complete
import json
schema = MCQ.model_json_schema()
prompt = "Here is a JSON schema for an Exam: " + json.dumps(
schema, indent=2, ensure_ascii=False
)
gemma = Ollama(
model="gemma3:12b",
request_timeout=120.0,
# Manually set the context window to limit memory usage
context_window=8000,
json_mode=False,
temperature=0.0,
)
prompt += (
"""
Extract an Exam from the following text.
Format your output as a JSON object according to the schema above.
Do not include any other text than the JSON object.
Omit any markdown formatting. Do not include any preamble or explanation.
請盡可能多的提取考題
"""
+ text
)
response = gemma.complete(prompt)
import re
raw = response.text.strip()
# 把 ```json ... ``` 和 ``` 拿掉
if raw.startswith("```"):
raw = re.sub(r"^```(?:json)?", "", raw)
raw = re.sub(r"```$", "", raw)
raw = raw.strip()
data = json.loads(raw)
pprint(data)

json_gemma = Ollama(
model="gemma3:12b",
request_timeout=120.0,
# Manually set the context window to limit memory usage
context_window=8000,
json_mode=True,
temperature=0.0,
)
response = json_gemma.complete(prompt)
json.loads(response.text)
{'qid': 1,
'question': '常見針灸配穴法中,所指的是「四關穴」,為下列何穴位之組合?',
'options': {'A': '上星、日月', 'B': '合谷、太衝', 'C': '內關、外關', 'D': '上關、下關'},
'ans': None}
schema = ExtractExam.model_json_schema()
prompt = "Here is a JSON schema for an Exam: " + json.dumps(
schema, indent=2, ensure_ascii=False
)
json_gemma = Ollama(
model="gemma3:12b",
request_timeout=120.0,
# Manually set the context window to limit memory usage
context_window=8000,
json_mode=True,
temperature=0.0,
)
prompt += (
"""
Extract an Exam from the following text.
Format your output as a JSON object according to the schema above.
Do not include any other text than the JSON object.
Omit any markdown formatting. Do not include any preamble or explanation.
請盡可能多的提取考題
"""
+ text
)
response = json_gemma.complete(prompt)
json.loads(response.text)

我們今天學了讓 llm 回我們 json 的三種 call 法
還有一分鐘搞懂 Pydantic
我本來都只會開 json mode 然後瘋狂改 prompt
簡易的測試了 6 種小情況
這邊都只是簡易的測試,我們明天來把量帶上去做真正的 benchmark


 iThome鐵人賽
iThome鐵人賽