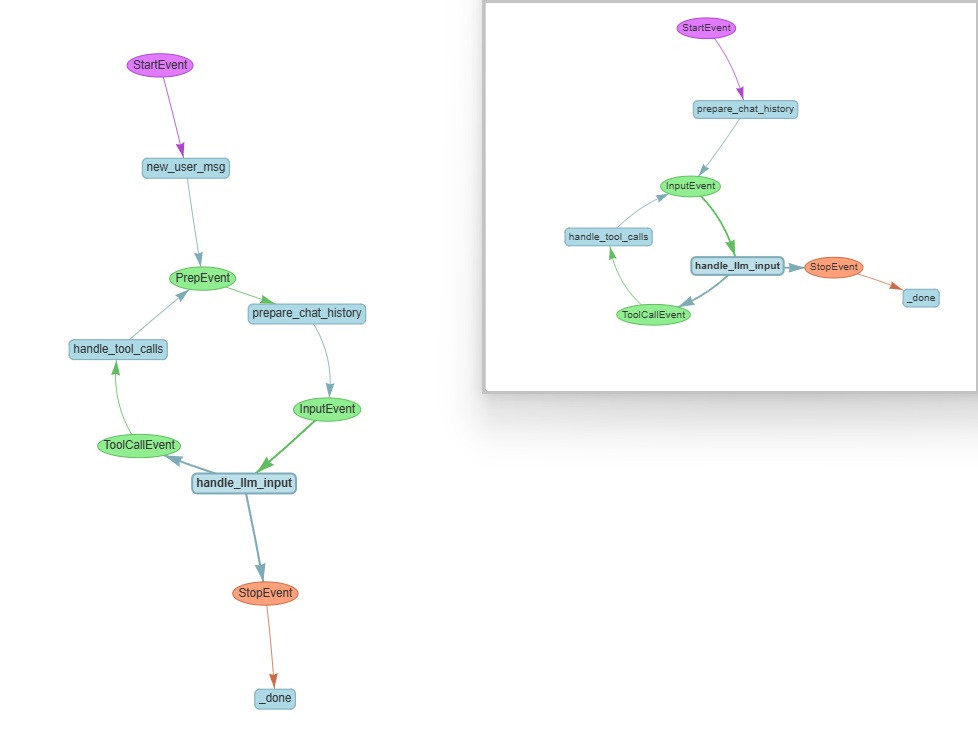
class PrepEvent(Event):
pass
class InputEvent(Event):
input: list[ChatMessage]
class ToolCallEvent(Event):
tool_calls: list[ToolSelection]
class FunctionOutputEvent(Event):
output: ToolOutput
class StreamEvent(Event):
msg: Optional[str] = None
delta: Optional[str] = None
from typing import Literal
from llama_index.core.tools import FunctionTool
def add(a: Literal[0, 1], b: Literal[0, 1]) -> Literal[0, 1]:
"""這是一個在二元代數結構上定義的神祕「加法」,你可以藉由呼叫這個工具來釐清它的運作邏輯。
此神秘加法滿足以下公理性特徵:
- 交換律:a ⊕ b = b ⊕ a
- 結合律:(a ⊕ b) ⊕ c = a ⊕ (b ⊕ c)
- 冪等律:a ⊕ a = a
- 加法單位元:0,使得 a ⊕ 0 = a
- 定義域僅含 0 與 1
Parameters:
a: either 0 or 1
b: either 0 or 1
Returns:
0 or 1
"""
if a not in (0, 1) or b not in (0, 1):
raise ValueError("add is only defined on {0,1}.")
return 1 if (a == 1 or b == 1) else 0
tools = [
FunctionTool.from_defaults(add)
]
class ReActAgent(Workflow):
def __init__(
self,
*args: Any,
llm: LLM | None = None,
tools: list[BaseTool] | None = None,
extra_context: str | None = None,
streaming: bool = False,
**kwargs: Any,
) -> None:
super().__init__(*args, **kwargs)
self.tools = tools or []
self.llm = llm or OpenAI()
self.formatter = ReActChatFormatter.from_defaults(
context=extra_context or ""
)
self.streaming = streaming
self.output_parser = ReActOutputParser()
llm = OpenAI(model="gpt-5-mini")
@step
async def new_user_msg(self, ctx: Context, ev: StartEvent) -> PrepEvent:
# clear sources
await ctx.store.set("sources", [])
# init memory if needed
memory = await ctx.store.get("memory", default=None)
if not memory:
memory = Memory.from_defaults()
# get user input
user_input = ev.input
user_msg = ChatMessage(role="user", content=user_input)
memory.put(user_msg)
# clear current reasoning
await ctx.store.set("current_reasoning", [])
# set memory
await ctx.store.set("memory", memory)
return PrepEvent()
w.run(input=query)
@step
async def prepare_chat_history(
self, ctx: Context, ev: PrepEvent
) -> InputEvent:
# get chat history
memory = await ctx.store.get("memory")
chat_history = memory.get()
current_reasoning = await ctx.store.get(
"current_reasoning", default=[]
)
# format the prompt with react instructions
llm_input = self.formatter.format(
self.tools, chat_history, current_reasoning=current_reasoning
)
return InputEvent(input=llm_input)
input:
output:
PrepEvent 這個事件有兩個 step 會發出來 (也就是說有兩種情況我們會執行到這個 step)
主要做的事情包含:
關於 formatter.format,我們在意三種情況:
@step
async def handle_llm_input(
self, ctx: Context, ev: InputEvent
) -> ToolCallEvent | StopEvent:
chat_history = ev.input
current_reasoning = await ctx.store.get(
"current_reasoning", default=[]
)
memory = await ctx.store.get("memory")
if self.streaming:
response_gen = await self.llm.astream_chat(chat_history)
async for response in response_gen:
ctx.write_event_to_stream(StreamEvent(delta=response.delta or ""))
else:
response = await self.llm.achat(chat_history)
ctx.write_event_to_stream(StreamEvent(msg=response.message.content))
try:
reasoning_step = self.output_parser.parse(response.message.content) # output_parser.parse
current_reasoning.append(reasoning_step)
if reasoning_step.is_done:
memory.put(
ChatMessage(
role="assistant", content=reasoning_step.response
)
)
await ctx.store.set("memory", memory)
await ctx.store.set("current_reasoning", current_reasoning)
sources = await ctx.store.get("sources", default=[])
return StopEvent(
result={
"response": reasoning_step.response,
"sources": sources,
"reasoning": current_reasoning,
}
)
elif isinstance(reasoning_step, ActionReasoningStep):
tool_name = reasoning_step.action
tool_args = reasoning_step.action_input
return ToolCallEvent(
tool_calls=[
ToolSelection(
tool_id="fake",
tool_name=tool_name,
tool_kwargs=tool_args,
)
]
)
except Exception as e:
current_reasoning.append(
ObservationReasoningStep(
observation=f"There was an error in parsing my reasoning: {e}"
)
)
await ctx.store.set("current_reasoning", current_reasoning)
# if no tool calls or final response, iterate again
return PrepEvent()
input: 上一步整理好可以直接丟給 llm 的 list of chat_message
output:
主要就 3 件事:
呼叫的部分:
thought: 我需要呼叫工具來回答這個問題
ReActOutputParser.parse 的部分,我們在意四種情況:
source code: output_parser
@step
async def handle_tool_calls(
self, ctx: Context, ev: ToolCallEvent
) -> PrepEvent:
tool_calls = ev.tool_calls
tools_by_name = {tool.metadata.get_name(): tool for tool in self.tools}
current_reasoning = await ctx.store.get(
"current_reasoning", default=[]
)
sources = await ctx.store.get("sources", default=[])
# call tools -- safely!
for tool_call in tool_calls:
tool = tools_by_name.get(tool_call.tool_name)
if not tool:
current_reasoning.append(
ObservationReasoningStep(
observation=f"Tool {tool_call.tool_name} does not exist"
)
)
continue
try:
tool_output = tool(**tool_call.tool_kwargs)
sources.append(tool_output)
current_reasoning.append(
ObservationReasoningStep(observation=tool_output.content)
)
except Exception as e:
current_reasoning.append(
ObservationReasoningStep(
observation=f"Error calling tool {tool.metadata.get_name()}: {e}"
)
)
# save new state in context
await ctx.store.set("sources", sources)
await ctx.store.set("current_reasoning", current_reasoning)
# prep the next iteration
return PrepEvent()
async def main():
# get tool_list
tool_list = get_tool_list()
# llm
llm = OpenAI(model="gpt-5-mini")
# workflow
w = ReActAgent(llm=llm, tools=tool_list, timeout=120, verbose=False)
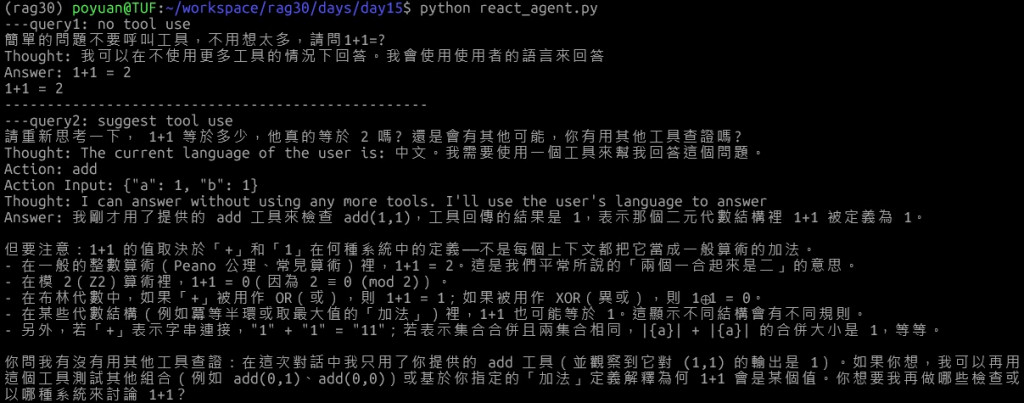
print('---query1: no tool use')
query1 = '簡單的問題不要呼叫工具,不用想太多,請問1+1=?'
print(query1)
handler = w.run(input=query1)
async for ev in handler.stream_events(expose_internal=False):
if isinstance(ev, StopEvent):
print(ev.result['response'])
else:
print(ev.msg)
print('-----' * 10)
print('---query2: suggest tool use')
query2 = '請重新思考一下, 1+1 等於多少,他真的等於 2 嗎? 還是會有其他可能,你有用其他工具查證嗎?'
print(query2)
handler = w.run(input=query2)
async for ev in handler.stream_events(expose_internal=False):
if isinstance(ev, StopEvent):
print("====final response")
print(ev.result['response'])
else:
print(ev.msg)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
這兩天比較下來,ReActAgent 跟 FunctionCallingAgent 最大的差異就是它強制 LLM 把 reasoning 寫出來,讓我們可以追蹤思路
我們是以造 Dataset 為核心的系列文
第一次接觸到 ReAct 的時候確實有被(它的花俏)吸引,於是就開始調用,然後一開始調用就開始出問題:
寫完這篇覺得對 ReActAgent 又有了更深一層的認識,希望讀到這裡的你也可以有所收穫


 iThome鐵人賽
iThome鐵人賽