前 16 天,我們一路鋪陳了基礎觀念:
從 RAG 檢索架構、快取、觀測性、Prompt 設計 到 Workflow 工具(LangChain + Guidance)。
這些都是在回答同一個問題:怎麼讓 LLM 更聰明、更可靠地使用資料。
但光有好的 Prompt 以及資料流程還不夠。
進入下半場,我們要面對更根本的實務課題:
👉 這些 LLM 實際要部署在哪裡?
不同策略不只影響成本,還會左右延遲、隱私、維運難度。
今天,我們就來比較這三種常見的 專案部署策略,看看它們的優缺點,以及什麼情境最適合哪種做法。
| 條件 / 選項 | 雲端 API ☁️ | 本地自建 🏠 | 混合架構 🔀 |
|---|---|---|---|
| 隱私需求 | 低 → 可接受把文件送到外部 API | 高 → 文件不能離開內部網路 | 中等 → 一般 FAQ 本地,敏感查詢本地,複雜推理交給雲端 |
| 成本預算 | 前期便宜,長期隨 Token 用量爆炸 | 前期高昂 (GPU / Infra),長期便宜 | 中等,可控,依需求切換 |
| 維運難度 | ★(幾乎免維運) | ★★★★ (GPU 監控、更新、效能改善) | ★★★(需要 Routing、雙邊監控) |
| 適合公司規模 | 初創 / 中小企業 PoC | 金融、醫療、大型企業、政府 | 中型企業,追求成本效益 |
| 案例 | 員工 50 人,每天少量問答 → 直接用 OpenAI GPT-4o / Anthropic Claude / Google Gemini | 銀行內部 FAQ Bot,需保留完整審計紀錄 → 本地 Llama 3 / Mistral / Falcon | 科技公司 500 人,日常 FAQ 用 Llama 3 / Mistral 本地自建模型,遇到需要創造性規劃的問題交給 Claude / GPT-4o / Gemini |
代表:OpenAI API、Anthropic Claude、Google Gemini、AWS Bedrock
優點:
➡️ 適合 初期 MVP / 快速上線,以及 對隱私要求不高的應用。
代表:Llama 2、Mistral、Falcon、RWKV,自行部署在 GPU Server 或 K8s Cluster
優點:
➡️ 適合 企業內部敏感應用(如醫療、金融、政府),或 長期高頻使用。
[註1] Quantization(量化,把浮點數權重轉成低精度,例如 FP16/INT8,降低運算成本)
做法:
➡️ 適合 追求性價比 或 需要彈性 的團隊。
範例邏輯如下:
def route_query(query: str) -> str:
"""
Routing 策略:
1. 先檢查敏感資料
2. 短文或 FAQ → 本地
3. 其他 → 雲端
"""
# 檢查是否含敏感資料(個資/機密)
if contains_pii(query): # PII: Personal Identifiable Information
return "local"
# 短文 or 常見 FAQ
elif len(query) < 300 or is_faq_match(query):
return "local"
# 預設走雲端
else:
return "cloud"
這樣可以做到成本效益與精度的平衡。
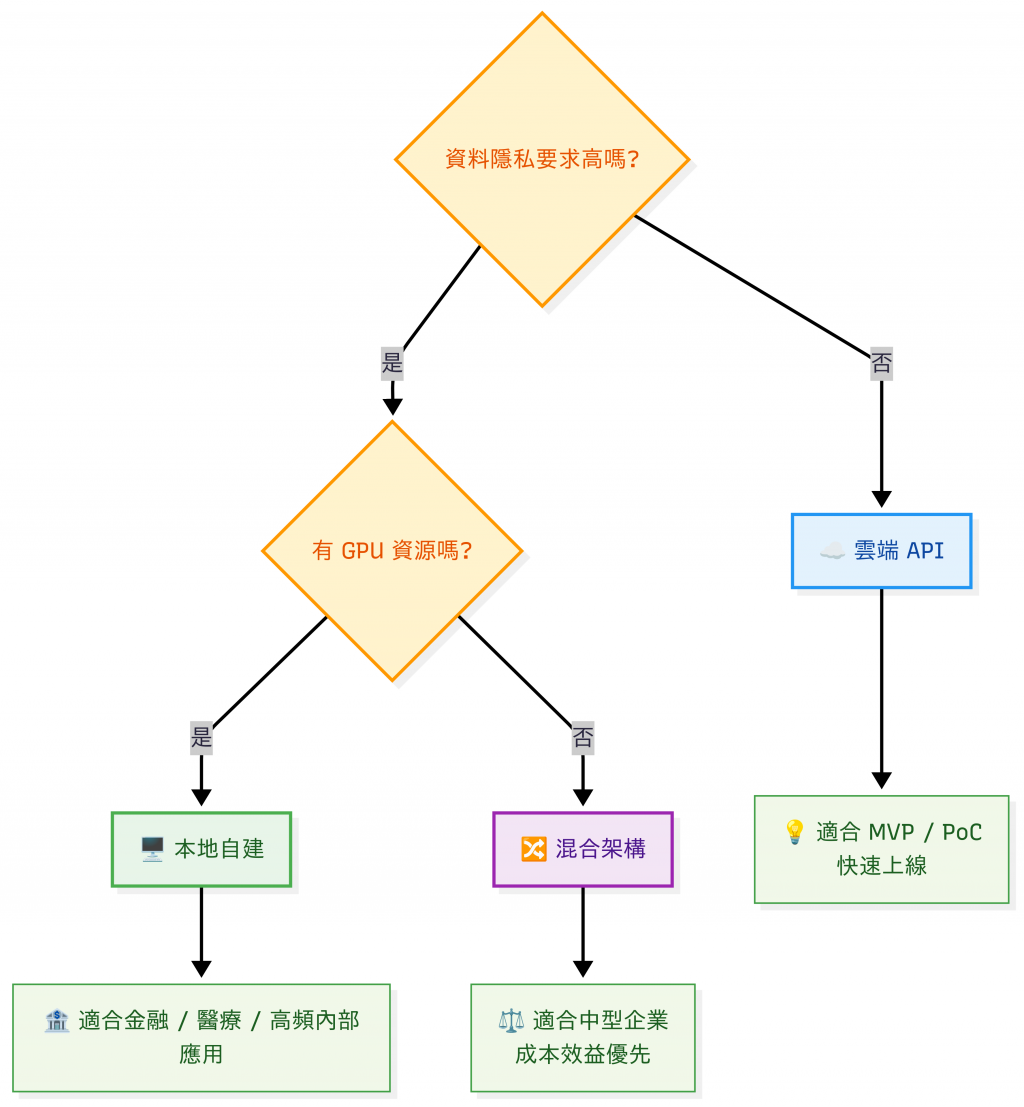
模型部署策略決策樹
| 常見陷阱 | 問題描述 | 實際後果 | 正確做法 ✅ |
|---|---|---|---|
| 過早自建 GPU | 一開始就花大錢買 8 張 A100,流量卻不足,GPU 閒置率高達 70%。 | 資本支出浪費,ROI 遠低於預期;現金流壓力大。 | 先用 雲端 API 驗證需求(PoC/MVP),等流量穩定再考慮自建或租 GPU。 |
| 低估維運成本 | 以為「買機器和 GPU卡就好」,忽略 電費、冷卻、機房、工程師人力。 | 電費 + 機房冷卻 + 運維人力,往往比 GPU 本身更貴;導致總擁有成本 (TCO) 超支。 | 在試算時加上 電費(400W × 24h × 30d)、人力成本(0.2 FTE DevOps/MLOps 工程師)。 |
| Routing 策略過簡 | 只用「字數 <300 → 本地,否則雲端」判斷,忽略資料敏感度與模型能力。 | 敏感資料可能被送到外部 API;遇到本地模型答不出來卻沒回退機制,導致使用者體驗差。 | Routing 應結合 敏感資料檢測(PII/NER)+ 回退策略,必要時自動切換雲端模型。 |
假設我們要做一個 公司內部 FAQ Chatbot,回答員工的常見問題(例如:請假流程、VPN 設定、HR 規章),應該選哪種部署策略呢?
以下月費皆不包含人力和維護費,只單看硬體成本:
GPU 以 單張 A100 24/7 的「算力基礎成本」對齊不同平台(實際要看是否真的需要 24/7 滿載)。
NTD 以 1 USD ≈ NT$32 呈現(實際匯率每日波動)。
| 策略 | 優點 | 缺點 | 適合情境 | 預估月費 (USD) | 預估月費 (NTD) |
|---|---|---|---|---|---|
| 雲端 API ☁️(GPT-4o mini) | 上線快、零維運;用多少付多少 | 需資料脫敏/合規;成本隨用量線性 | PoC / 小團隊 / 低流量 | $11–$20($0.375/天 × 30 天 = $11.25/月) | NT$350–640 |
| 本地 GPU(租用,AWS,A100) | 資料留內部;彈性加減算力 | 維運較複雜;24/7 成本中高 | 合規要求較嚴的中型團隊 | $1,060–2,950/月/GPU(Capacity Blocks 估 $1.475/hr 底價;On-Demand 換算約 $4.10/hr/卡) | NT$34,000–94,400 |
| 本地 GPU(租用,RunPod / Lambda,A100) | 單卡成本較 AWS 低;好擴縮 | 可靠度/配額受供應商影響 | PoC / 短期專案 / 降本 | $1,180–1,560/月/GPU($1.64–2.17/hr) | NT$37,800–49,900 |
| 本地 GPU(自購,1 年攤提,A100 80GB) | 最高隱私與控制;可客製 | CapEx [註3]高;維護需人力 | 資金充足的短期專案 | $1,200–1,800 + 隱藏成本 | NT$38,000–57,000 + 隱藏成本 |
| 本地 GPU(自購,3 年攤提,A100 80GB) | 攤提後 TCO [註4]低 | 折舊/維修/升級風險 | 長期運營 | $500–1,200 + 隱藏成本 | NT$16,000–38,000 + 隱藏成本 |
| 混合架構 🔀(A100 本地主 + API 備援) | 高可用;流量尖峰可轉雲 | 維運複雜、雙邊成本 | 高可用 / 容災需求 | $1,200–3,200+(本地主 1 張 A100 + 少量 API) | NT$38,000–102,000+ |
[註3] CapEx 全名是 Capital Expenditures(資本支出),中文一般翻作 資本性支出。
[註4] 光看 GPU 硬體成本($330/月)可能覺得很便宜,但加上電費、人力後,實際月費可能超過 $1,600。
| 項目 | 假設/計算公式 | 成本/月 (USD) | 成本/月 (NTD) |
|---|---|---|---|
| 硬體成本 | $12,000 ÷ 36 個月 (3 年攤提) | $333 | NT$10,656 |
| 電費 | 400W × 24hr × 30 天 × NT$4.0/kWh = 288 kWh × 4.0 | $36 | NT$1,152 |
| 維護人力 | 0.2 FTE × $5,500/月 | $1,100 | NT$35,200 |
| 總計 | 硬體 + 電費 + 人力 | $1,469/月 | NT$47,008/月 |
[註5] 台電工業用電採時間電價,依契約與時段而定。113/04/01 起之高壓電力價目參考:離峰 NT$2.49–2.62/kWh、半尖峰 NT$3.56–3.67/kWh、尖峰(夏月)約 NT$10.42–10.70/kWh。近年新聞口徑之工業平均約 NT$3.8–4.3/kWh;若要保守估算,可抓 NT$4.0/kWh。讀者可自行依實際合約與時段重算。
[註6] FTE 是 Full-Time Equivalent 的縮寫,中文常翻成 全職人力當量,泛指花了多少時間維護系統。
混合架構需要同時維護兩套系統,本地與雲端的成本會疊加:
總計:約 $2,819/月,比單純本地成本高出許多。
➡️ 適合 PoC、小規模試行 、無 IT 團隊的小型企業 或 非敏感資料的測試。
Kubernetes 叢集或是 Bare Metal Servers[註7] 裡部署 開源 LLM (Llama 3.1 - 8B/70B or Mixtral) 、自建模型 + 向量資料庫(如 Milvus / Pinecone)儲存 FAQ 文件提升效率。➡️ 適合 大型企業 / 金融 / 醫療 / 政府機構。
[註7] Bare Metal(實體機,不透過虛擬化層(Hyperisor),直接跑在硬體上)
➡️ 適合有 IT 能力但預算有限的中型企業,追求 成本效益 + 彈性。
⚡ 實際流量並非每天固定,可能在日間尖峰時段衝高 5–10 倍。建議搭配 Auto-scaling(自動擴縮) 機制,例如雲端 GPU Spot Instance 或 Kubernetes HPA,才能避免資源閒置或突發 OOM。
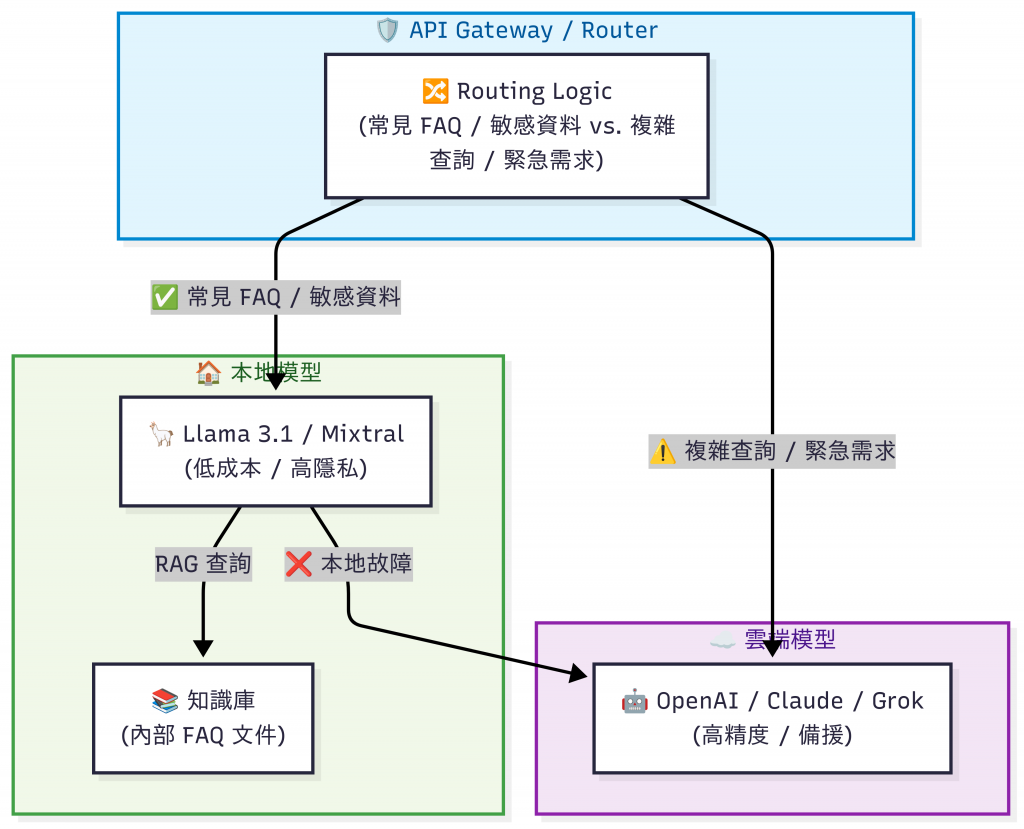
混合型架構示意圖
在 1,000 人公司、每日 1,000 次查詢、且 高度重視隱私 的情境下,最合適的選擇是 方案二(本地自建):
理由
實施步驟
備選方案 : 方案三(混合架構)
成本:
註:若功耗取 600W,電費變為 NT$1,728/月,則範圍分別上移 +NT$576。
- 本文所涉及之成本試算、架構建議,均基於公開資訊(如雲端廠商定價頁、GPU 市場行情)與合理假設情境,僅供技術交流與學習參考。
- 實際部署成本將因 地區電價、供應商折扣、模型選型、維運模式 等因素而有顯著差異,另本文撰寫於 2025 年 10 月,雲端/GPU 市場價格變動快速,請以最新報價為準。
- 本文不代表任何特定企業之內部數據或商業決策,亦不構成投資建議或專案承諾。
- 若讀者需進行實際部署,建議以 自家需求與專案預算 為基準,並搭配專業顧問或雲端供應商提供之最新報價進行評估。
LLM 可以有 三種典型部署策略:雲端 API、本地自建、混合架構:
明天(Day 18),我們會開始介紹 LLM API Gateway 架構,示範如何用 FastAPI + LLM Proxy 搭建一個安全、可控的中介層,並且逐步審視 LLMOps 在維護 LLM 應用時需要留意的部分。


 iThome鐵人賽
iThome鐵人賽