經過前面系列的文章,我們已經從零搭建出一條完整的 RAG Pipeline ,目前具備以下能力:
如下圖所示:
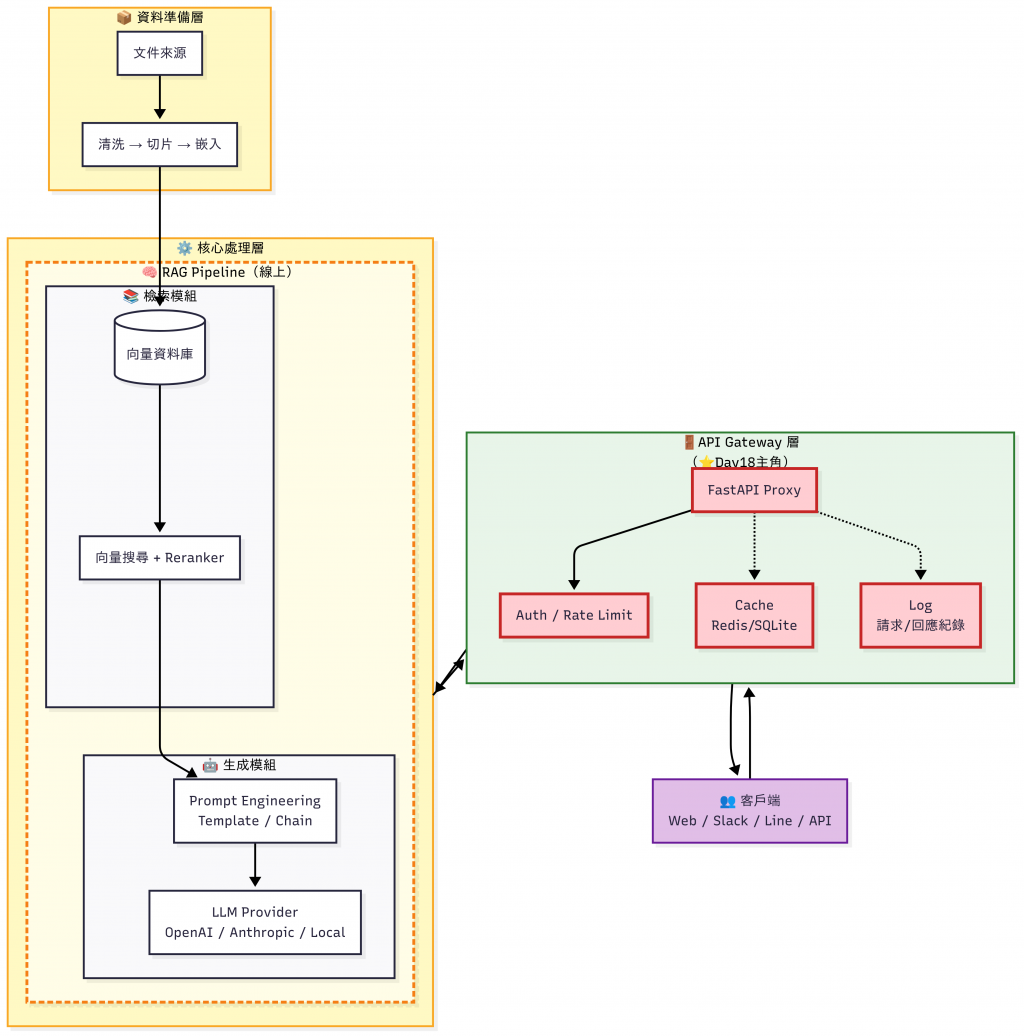
在 Day17 的混合架構我們定義了 Routing 策略,今天(Day18)我們會開始把這套策略部分落實到 API Gateway,並延伸介紹我們可以在 API Gateway 上面做什麼事情。
RAG Pipeline 打好基礎後,我們就擁有了一個 企業知識庫 + LLM 驅動的 Q&A 能力。
然而目前的架構還有一個明顯限制:
部分前端或新接入的應用(Web、Slack Bot、Line Bot、Discord Bot)仍是直接呼叫 LLM Provider(如 OpenAI API),而即便已有簡易後端,各應用也常各自直連 LLM、缺少一個統一出入口。
這會帶來三個問題:
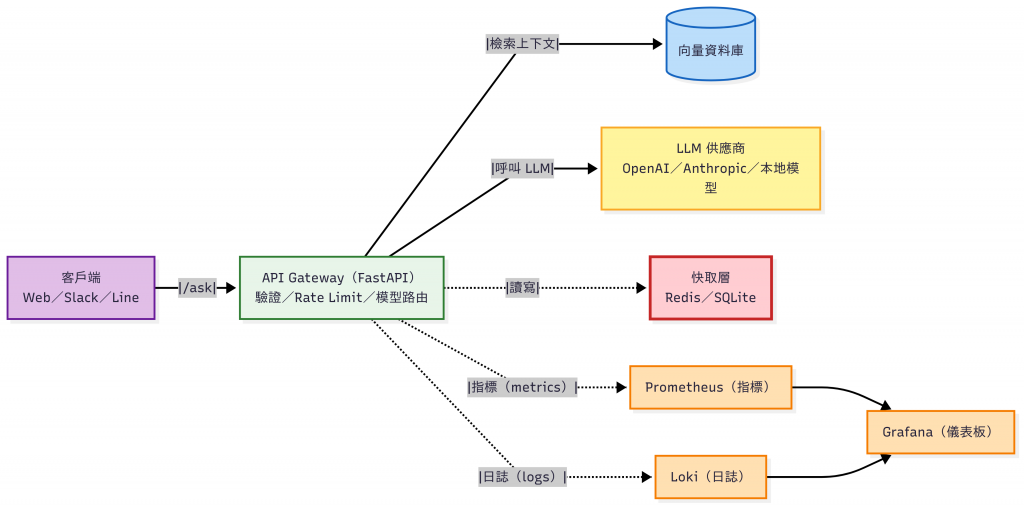
API Key 管理上也有困難因此今天我們引入 API Gateway:讓所有前端只需呼叫同一個 /ask 出入口,在這一層集中處理 Auth/Rate Limit、Log、Cache、觀測與模型抽象化/路由,安全且一致地存取 LLM 與檢索能力。
| 面向 | 能做什麼 | 具體作法 / 範例 | 實務案例 |
|---|---|---|---|
| 🔐 安全性保護 | 集中金鑰管理、避免外洩;依需求設定 Rate Limit | 後端保存 Provider Key;依租戶/路徑設限流與配額分別設定 Rate Limit | 依「部門金鑰」做配額:HR 2k req/day、CS 10k;超額回 429 並寫入審計 log |
| 🔄 抽象化模型來源 | 前端只呼叫 POST /ask;後端可隨時替換 LLM Provider |
OpenAI / Anthropic / 本地模型可熱切換;前端零改動 | 規則:當使用者請求被判定為「包含 PII [註1]」時,該請求一律路由到本地模型處理需求時間分類:1秒需求→gpt-4o-mini、長文/推理→GPT-4o` |
| 📈 可觀測性 (Metrics) | 記錄 Query Log、Token 用量、Latency / Error Rate;自動 Failover | 以延遲 / 錯誤率觸發降級或改變路由;成本分析與除錯 | 異常:p95>3s 且 5xx>2% 即切備援模型並通知 On-call |
| 🌐 跨平台存取 | 多端共用同一 API,避免重複整合 | Web、Slack Bot、Line Bot 同走 Gateway 出入口 | 企業入口網站、Slack 問答機器人與 Line 客服,同用 /ask 與同一套快取策略 |
[註1] Personally Identifiable Information,可識別個資
即使把 Provider 的 API Key 放到後端,仍需確認「誰在呼叫、能不能呼叫、可用多少」,以下是幾個常見做法:
iss/aud/scope/exp,適合 Web/Mobile 與 RBAC。kid 支援雙簽重疊期;30/60/90 天輪替;依環境/租戶分權並記審計日誌。完整的程式碼放在 GitHub Repo。
還記得在 Day07 - Demo 最小可行的 RAG QA Bot (Web 版)我們做了一份專案,功能是「先查詢內部知識庫,再交由 LLM 回答」,然後再把專案裡的後端程式讓前端頁面呼叫嗎 ? 我們現在要把這個後端程式抽出來,包裝成一個 Gateway。
day18_LLM_Gateway/
├─ gateway/
│ └─ main.py # LLM Gateway:統一入口 /ask
├─ services/
│ └─ retrieval_service.py # Day07 改寫的檢索邏輯(向量嵌入 + FAISS 搜尋)
├─ frontend/
│ └─ index.html # Day07 前端
├─ .env
└─ requirements.txt
Gateway 資料夾底下的 main.py 只做「統一入口 + 呼叫模型」。
它會:
retrieval_service 拿到 context先寫一個簡單的 gateway 版本:
# gateway/main.py
from fastapi import FastAPI, HTTPException, Request
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import JSONResponse, FileResponse
from fastapi.staticfiles import StaticFiles
from pathlib import Path
from typing import Dict, Any
import os, time, traceback
from dotenv import load_dotenv
from openai import OpenAI
from services.retrieval_service import retrieve_best
load_dotenv()
app = FastAPI(title="LLM Gateway (Day18)")
# CORS(同源存取時也能留著,上線請改白名單)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_methods=["*"],
allow_headers=["*"],
)
# === 前端頁面設定 ===
BACKEND_DIR = Path(__file__).resolve().parent
FRONTEND_DIR = BACKEND_DIR.parent / "frontend"
@app.get("/") # 讓根路徑回首頁
def root():
idx = FRONTEND_DIR / "index.html"
if idx.exists():
return FileResponse(idx)
return JSONResponse({"error": "frontend/index.html not found"}, status_code=404)
# 如需放 JS/CSS/圖,掛到 /_static(可選)
app.mount("/_static", StaticFiles(directory=FRONTEND_DIR, html=True), name="frontend")
# === 健康檢查 ===
@app.get("/healthz")
def healthz():
return {"ok": True}
# === OpenAI Client ===
api_key = os.getenv("OPENAI_API_KEY")
if not api_key:
raise ValueError("沒有找到 OPENAI_API_KEY,請檢查環境變數!")
OPENAI_TIMEOUT = float(os.getenv("OPENAI_TIMEOUT", "20"))
CHAT_MODEL = os.getenv("CHAT_MODEL", "gpt-4o-mini")
client = OpenAI(timeout=OPENAI_TIMEOUT, max_retries=0)
# === 主要 API ===
@app.post("/ask")
def ask(payload: Dict[str, Any]):
"""
輸入例:
{ "question": "加班規則?", "temperature": 0.2 }
"""
start = time.time()
try:
question = (payload.get("question") or "").strip()
if not question:
raise HTTPException(status_code=400, detail="question is required")
# 1) 先查知識庫(沿用 Day07/RAG)
context, dist = retrieve_best(question, k=3)
# 2) 再交由 LLM 回答
messages = [
{"role": "system", "content": "你是一個企業 FAQ 助理。"},
{"role": "user", "content": f"根據以下知識庫內容回答:\n{context}\n\n問題:{question}"},
]
resp = client.chat.completions.create(
model=CHAT_MODEL,
messages=messages,
temperature=float(payload.get("temperature", 0.2)),
)
answer = resp.choices[0].message.content
return {"question": question, "context": context, "answer": answer, "debug": {"l2": dist, "model": CHAT_MODEL}}
except HTTPException:
raise
except Exception as e:
traceback.print_exc()
return JSONResponse(status_code=500, content={"error": str(e)})
finally:
print(f"[gateway:/ask] {(time.time()-start):.2f}s")
# 安裝套件
pip install -r requirements.txt
# 啟動 Gateway
uvicorn gateway.main:app --reload --port 8000
測試(POST JSON):
❯ curl -X POST "http://localhost:8000/ask" \
-H "Content-Type: application/json" \
-d '{"question":"加班規則是什麼?"}'
{"question":"加班規則是什麼?","context":"加班申請:需事先提出,加班工時可折換補休。","answer":"加班規則是:員工需事先提出加班申請,並且加班工時可以折換為補休。","debug":{"l2":0.9121904969215393,"model":"gpt-4o-mini"}}%
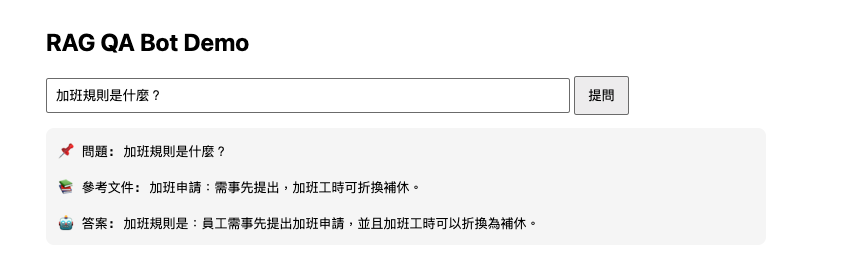
UI 介面測試:
在真實環境,我們會用 Redis 或雲端 API Gateway 做限流,但為了 Demo,我們只要在程式裡加一個「記憶體限流」+「簡單 Logging」+「Metrics」就好。
目標:
429 Too Many Requests。⚠️ Demo 僅示範用途;生產請改 Redis 或 Edge 限流 :
Redis + Sliding Window/Token Bucket(慢限流 + 配額)
NGINX / Envoy 邊界限流
雲端:AWS API Gateway / Cloudflare Rate Limiting
限制每分鐘最多 10 次請求,並且把 access 紀錄只存在程式的記憶體裡(重啟就會清空):
# ============================================================
# 🟢 記憶體限流 (In-Memory Rate Limit)
# - Demo 用:每 IP 每分鐘最多 10 次
# - 程式重啟會清空;多機不共享
# - 生產環境請換 Redis / 雲端 API Gateway
# ============================================================
_WINDOW_SEC = int(os.getenv("RATE_LIMIT_WINDOW_SEC", "60"))
_LIMIT = int(os.getenv("RATE_LIMIT_MAX_PER_IP", "10"))
_BUCKETS: dict[str, deque] = defaultdict(deque)
def in_memory_rate_limit(request: Request):
ip = request.client.host
now = time.time()
dq = _BUCKETS[ip]
# 移除視窗外的請求
while dq and now - dq[0] > _WINDOW_SEC:
dq.popleft()
if len(dq) >= _LIMIT:
raise HTTPException(status_code=429, detail="Too Many Requests (demo limiter)")
dq.append(now)
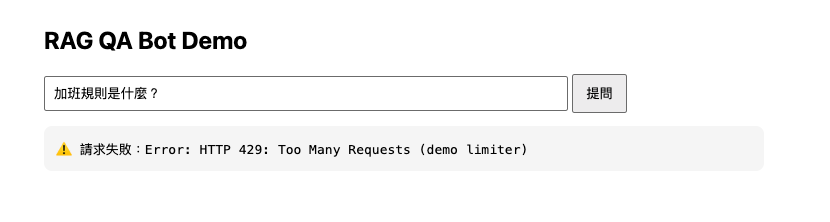
測試結果:
❯ curl -sS -X POST "http://localhost:8000/ask" \
-H "Content-Type: application/json" \
-d '{"question":"加班規則是什麼?"}'
{"detail":"Too Many Requests (demo limiter)"}
| 層級 | 作法 | 優點 | 缺點 | 適用 / 備註 | 設定說明(統一以 request / second 表示) |
|---|---|---|---|---|---|
| 應用層 | Redis + Sliding Window Counter | 多機一致、實作簡單、易做 per-tenant | 視窗越細資源用量越高;需要 Redis | 同時間高流量的應用、精細租戶控制;Redis 故障 → 保守(僅白名單或降速) | Key:rate:{tenant}:{client}:{route}:{1s};1 r/s;超量回 429+Retry-After;加上 X-RateLimit-* |
| 應用層 | Token Bucket(Redis/Envoy) | 支援短暫突發、恢復平滑 | Redis 需原子性實作,較複雜 | 互動式/不穩定流量;昂貴路由可設較小 r/s | Redis:每秒補 rps、桶 burst;Envoy:tokens_per_fill、max_tokens |
| 邊界層 | NGINX limit_req |
在進入 App 前先擋爆量、部署容易 | 不支援複雜的租戶策略 | 以 IP/路徑 做粗限流,與應用層細則搭配使用 | limit_req rate=5r/s burst=10 nodelay;超量回 429+Retry-After |
| 雲端 | Cloudflare Rate Limiting | 開箱、低維運,含 Bot 防護 | 可能增加延遲或成本 | 公開入口先降低風險 | 依路徑/方法設定 requests/period(換算為 r/s);超量回 429 |
| 雲端 | AWS API Gateway Usage Plans | 內建 rate/burst 與日/月配額 | 配額用罄要有後續明確處理流程 | 快速上線、內建監控(e.g. CloudWatch) | 每個 API Key 綁 rate/burst+quota;監看 429 與配額剩餘 |
| Side Car/服務網格 | Envoy Rate Limit Service (RLS) | 與服務網格整合、策略集中 | 部署與設定較複雜 | 大型微服務、多入口一致策略 | 以 tenant/route 下達 RLS 規則;可與 Istio 整合 |
把 Query log 輸出到後端伺服器的 console / stdout,同時也寫一份到 gateway.log 檔案:
# ============================================================
# 🟠 Logging:同時輸出 console + 檔案 gateway.log
# ============================================================
root_logger = logging.getLogger()
if not root_logger.handlers:
root_logger.setLevel(logging.INFO)
fmt = logging.Formatter("%(asctime)s %(levelname)s %(message)s")
# Console Handler
ch = logging.StreamHandler()
ch.setFormatter(fmt)
root_logger.addHandler(ch)
# File Handler
fh = logging.FileHandler("gateway.log", encoding="utf-8")
fh.setFormatter(fmt)
root_logger.addHandler(fh)
log = logging.getLogger(__name__)
gateway.log:
2025-09-10 12:42:30,072 INFO HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
2025-09-10 12:42:30,481 INFO HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
2025-09-10 12:43:28,443 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-09-10 12:43:28,446 INFO [ASK] success in 1.94s, answer_len=32
2025-09-10 12:43:36,389 INFO [ASK] ip=127.0.0.1 q='加班規則是什麼?' temp=0.2
2025-09-10 12:43:36,735 INFO HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
2025-09-10 12:43:38,272 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-09-10 12:43:38,275 INFO [ASK] success in 1.89s, answer_len=32
2025-09-10 12:43:38,837 INFO [ASK] ip=127.0.0.1 q='加班規則是什麼?' temp=0.2
2025-09-10 12:43:39,193 INFO HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
2025-09-10 12:43:40,420 INFO HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-09-10 12:43:40,423 INFO [ASK] success in 1.59s, answer_len=32
⚠️ 這個版本只是 教學用 Demo,因為程式一重啟,限流的記錄就會消失。
最後在 Gateway 加上 最小可用的觀測性,在 main.py 加上相關設定:
from prometheus_client import Counter, Histogram, generate_latest, CONTENT_TYPE_LATEST
REQS = Counter(
"gateway_requests_total", "Total HTTP requests",
labelnames=["route", "method", "status"]
)
LAT = Histogram(
"gateway_request_duration_seconds", "Request latency (seconds)",
labelnames=["route", "method"]
)
ERRS = Counter(
"gateway_errors_total", "Errors by type",
labelnames=["route", "type"]
)
text/plain exposition)。/metrics 自身。| 指標名稱 | 型別 | 標籤 | 用途 |
|---|---|---|---|
gateway_requests_total |
Counter | route, method, status |
每個路由的請求次數(含狀態碼) |
gateway_request_duration_seconds |
Histogram | route, method |
請求延遲直方圖(可推 p50/p95) |
gateway_errors_total |
Counter | route, type |
錯誤次數(http/unhandled/自訂類型) |
備註:Middleware 會自動涵蓋
/ask、/healthz等所有路由;/metrics 已排除不計,避免自我干擾。
| 需求 | 推薦方案 | 為什麼 |
|---|---|---|
| 立刻上線,不想自建 | OpenRouter | 託管服務、單一 API 打多家模型 |
| 自建但想省事 | LiteLLM Proxy | OpenAI 相容、Docker 即起、可路由/降級 |
| 需要強大觀測 | Helicone / Langfuse | 請求/成本/Prompt 分析 + Gateway |
| 自建開源模型 | vLLM + LiteLLM | vLLM 高效推理、LiteLLM 統一介面/降級 |
| 企業穩定推理 | Hugging Face TGI | 穩定成熟的企業級推理伺服器 |
| 雲端端點省維運 | Anyscale Endpoints | 雲端代管多種模型、彈性擴展 |
| 工具 | OpenAI 相容 | 路由 / 降級 | 觀測 | 部署方式 |
|---|---|---|---|---|
| OpenRouter | ✅ | ✅ | 部分 | 託管 |
| LiteLLM Proxy | ✅ | ✅ | 有成本/用量/預算記錄 | 自建 / Docker |
| Helicone | ✅(Proxy/非阻斷) | ✅(Gateway) | ✅(強) | 託管或自建 |
| Langfuse | N/A(觀測層) | ⛔ | ✅(強) | 託管或自建 |
| vLLM | ✅(Chat/Completions) | ⛔(自行搭配) | ⛔(自行搭配) | 自建 |
| Hugging Face TGI | 部分(需轉接) | ⛔(自行搭配) | ⛔(自行搭配) | 自建 |
| Anyscale Endpoints | 部分(相容層) | 可能(依方案) | 有平台監控 | 託管 |
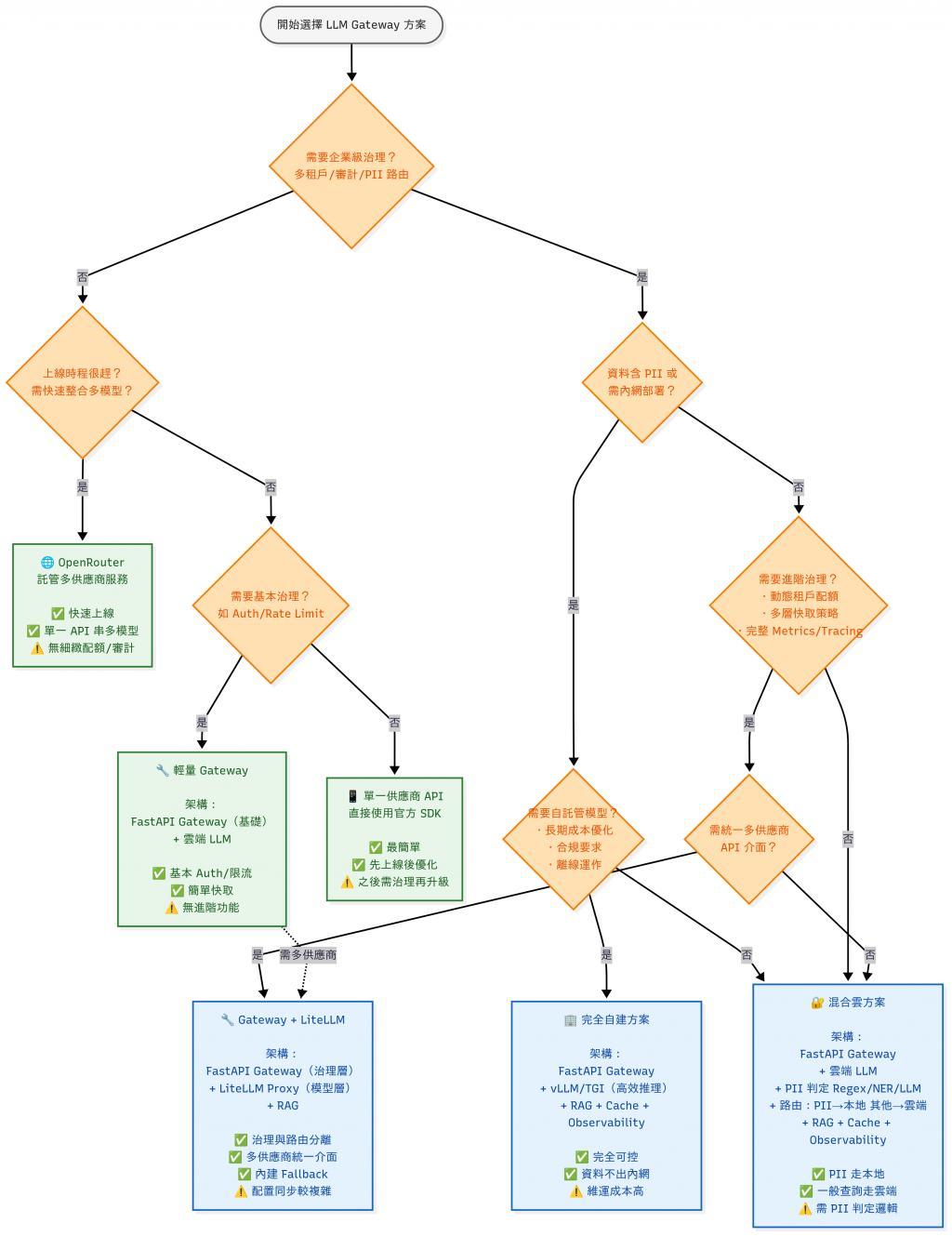
今天我們完成了一個 最小可行的 API Gateway:
它提供統一的 /ask API,隱藏 API Key,讓任何 Client 都能安全地呼叫 LLM。
雖然目前功能還很精簡,但它已經是整個系統的 核心樞紐。
接下來,所有的請求都會經過這個 Gateway,我們就能逐步加入:
隨著這些能力逐步加上去,Gateway 會從「單純的代理」演化成真正的 企業級 LLM 中控點。
明天(Day 19),我們就會把焦點放在 Observability(可觀測性),看看如何監控 Latency、Token 與成本,避免月底帳單嚇死人。

