我們在上下文的容量限制與策略設計有提到 Token 的限制是每個模型不可違背的規則,所以我們總希望在有限的 Token 條件下,可以保存長期有用的記憶,又能避免無關的資訊一直變多。
如果擁有一些機制與策略做應對,就不用讓過多的歷史資料浪費運算資源,也會降低模型的干擾判斷,這就是持久化與「遺忘機制的重要性。簡單來說,持久化讓 AI 記得該記的事,遺忘則讓它忘掉該忘的事。兩者相輔相成,缺一不可。
當對話持續進行,上下文就會像滾雪球一樣越積越多,若缺乏有效的管理機制,很快就會遇到瓶頸。
一旦上下文累積過多無用的資訊,將會導致以下問題:
此外,一個更深層的問題是當模型學習新的資訊時,可能會突然覆蓋或破壞先前已學會的知識。在對話系統中,這會導致模型對新舊資訊產生混淆,無法做出一致性的判斷。
在長對話中,使用者的觀點或提供的資訊可能會改變。例如,使用者一開始說我喜歡藍色,後來又提到綠色是我最愛的顏色。如果系統只是單純地累積所有訊息,就會同時存在兩條矛盾的記憶,導致後續的回應產生混淆。
有效的記憶管理系統必須決定如何處理新的資訊。這涉及到幾個決策點:
為了解決上述問題,我們可以設計多種策略,讓系統能夠主動或被動地刪除、壓縮不再重要的記憶。以下介紹幾種常見且有效的作法。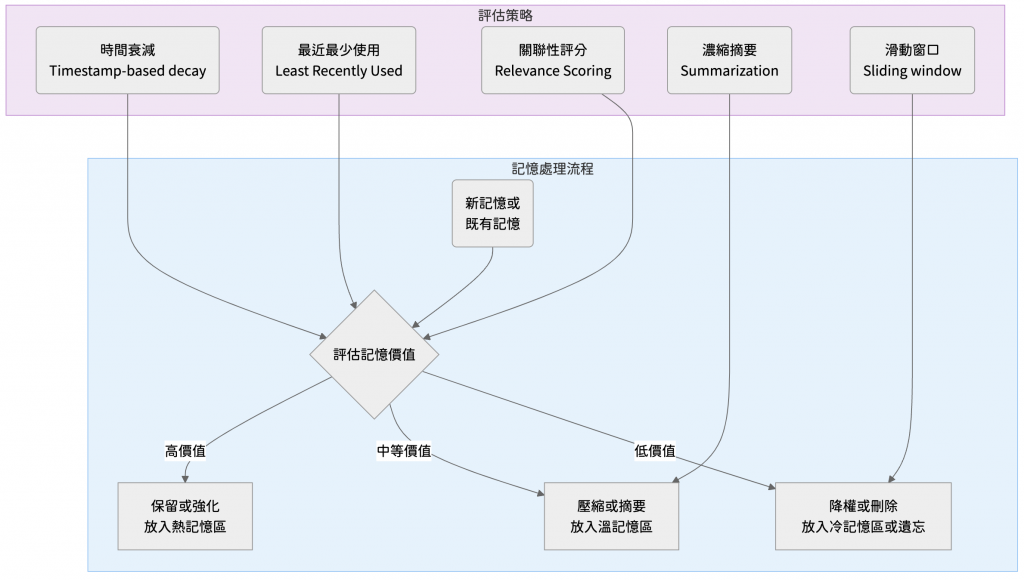
這個策略的核心思想很簡單,就是記憶會隨著時間流逝而變得模糊。
系統會為每一條記憶標記時間戳記,其重要性權重會隨著時間推移而逐漸衰減。當權重低於某個預設的門檻時,該記憶就會被自動刪除或歸檔。這完美地模擬了人類記憶的遺忘曲線,有興趣的朋友可以查查艾賓浩斯遺忘曲線,非常適合用於學習唷。
這個 策略源自系統的快取管理機制,意思是如果一個記憶在最近很少被使用,那它在未來被使用的機率也很低。系統會追蹤每條記憶被檢索或引用的頻率,當記憶庫容量達到上限時,會優先刪除那些最久未被使用的記憶。
這是一種更動態的評估方式。系統會根據當前的對話主題或任務,為每一條歷史記憶計算一個關聯性分數。這個分數綜合了多種維度,例如語義相似度、使用頻率、時間遠近...等,當需要清理記憶體時,系統會淘汰分數最低的記憶。
這是一種簡單粗暴但最有效的策略,我們讓系統保留最近的 N 條對話紀錄或記憶。一旦有新的對話產生,最舊的一條紀錄就會被自動捨棄。雖然這種方法可能會丟失重要的長期記憶,但對於許多不需要深度歷史背景的應用來說,已經足夠。
與其直接刪除舊記憶,不如將其濃縮成精華。系統可以定期將一段冗長的對話歷史,透過語言模型自身的能力,自動生成一段簡潔的摘要。這個摘要會取代原始的詳細記錄,從而釋放出大量的上下文空間,同時保留了核心資訊。
我們可以將記憶比喻為儲存資料,依據其重要性與存取頻率,分為不同的層級:
更高階的記憶管理,是讓模型本身具備選擇性遺忘的能力,而不僅僅依賴外部的規則。
有些人覺得模型應該像人腦一樣,能夠主動判斷哪些記憶不再重要並將其遺忘。這種刻意遺忘的能力,有助於模型擺脫過時資訊,提升對新情境的適應性與靈活性。
這是在更底層的技術上實現遺忘。例如如何直接對模型的內部參數進行剪枝,動態移除那些不再活躍或貢獻度低的連結,從根本上做到忘記特定資訊的效果。
在某些特定情境下,我們需要模型完全、徹底地忘記某些資訊,例如涉及使用者隱私的敏感資料,或是因應法規要求需要刪除的內容。這就需要忘卻學習的技術,透過特定的演算法調整模型權重,使其狀態回復到從未學習過該資訊的樣子。
為了防止重要記憶因時間流逝而被遺忘,系統可以設計一個複習機制。我們可以定期重訪那些被標記為高價值的記憶,強化模型對它們的印象。
例如,Think-in-Memory 框架提出模型不應只儲存對話原文,而應儲存從中提煉出的歸納性思緒,讓模型在重訪時能更好維持邏輯的一致性。
我們可以透過提示詞,引導模型執行記憶清理或壓縮的任務。
這是目前的記憶庫摘要 (包含 20 條記憶)。
請幫我刪除與主題「健身」、「飲食」無關,且超過 30 天未被使用的記憶條目。
最後,請回傳更新後的記憶庫摘要,以及被刪除的項目清單。
以下是長度為 1000 Tokens 的對話歷史紀錄。
請將其濃縮為一段 200 Tokens 以內的摘要,並保留其中最重要的三到五個關鍵記憶點。
未來,這段摘要將會取代原始的詳細記憶,納入我的永久上下文中。
請從以下的記憶庫清單中,找出內容重複或語義高度相似的條目。
對於重複的內容,請只保留資訊最完整、最新的那一個版本,並刪除其他的冗餘版本。
最後回報更新後的記憶庫內容與被刪除的項目。
上下文的持久化與遺忘機制,是上下文工程中比較複雜但關鍵的一環。
一個好的記憶系統就像大腦一樣,可以在記憶與遺忘之間取得微妙的平衡。如果沒有好的遺忘策略,系統會被沉重的歷史包袱拖垮;但如果遺忘得太多,模型又會變得健忘,無法提供連貫且個人化的體驗。
我們可以透過設計精良的時間衰減、LRU、關聯性評分、摘要替代...等策略,讓記憶庫保持在最佳狀態,並搭配主動遺忘、忘卻學習 ... 等功能,讓 AI 變得愈來愈智慧。


 iThome鐵人賽
iThome鐵人賽