想像一下,你每天使用 Google 搜尋、請 Siri 幫你設定鬧鐘、或是用翻譯軟體看懂英文文章。
這些看似理所當然的功能,背後都藏著一個核心問題:
電腦要如何「理解」人類的語言?
對人類來說,「蘋果很好吃」和「這部電影很好看」都能輕鬆理解。
但對電腦而言,這些文字就像是一堆亂碼。電腦的世界裡只有 0 和 1,
它需要一套方法把文字轉換成數字,才能進行計算和分析。
這就是「自然語言處理」(Natural Language Processing, NLP) 要解決的問題。
今天這篇文章,我們將從最基礎的「斷詞」開始,一路探索到「詞向量」,
看看電腦是如何一步步學會「讀懂」文字的。
斷詞是將連續的文字切分成有意義的最小單位,
這個步驟雖然看似簡單,卻是所有 NLP 任務的基礎,
因為斷詞的品質會直接影響後續所有分析的準確度。
而英文的斷詞相對中文要容易不少,因為單字之間有空格作為天然分隔符。
例如像是 "I love eating apples" 可以直接按空格
切分成 ["I", "love", "eating", "apples"]。
相對的,中文的斷詞則複雜得多。中文字之間沒有明確界線,
「研究生命」可能是「研究/生命」,也可能是「研究生/命」,
這種歧義性是中文斷詞的主要挑戰。
中文斷詞主要有三種方法:
-基於詞典的方法使用預先建立的詞典,將句子與詞典中的詞進行匹配。
這種方法速度快,但無法處理新詞或未登錄詞。
-基於統計的方法透過計算字與字之間共同出現的機率,判斷哪些字應該組合成詞。
這種方法對新詞的適應性較好。
-基於深度學習的方法使用神經網路模型學習斷詞規則。
這是目前準確度最高的方法,但需要大量標註資料和計算資源。
完成斷詞後,我們就需要將文字轉換成數字給電腦看,這個步驟就稱為文字的數值化或向量化。
不同的數值化方法適用於不同的應用場景。以下我們就來看看幾種不同的方式:
One-Hot Encoding 是最直觀的文字數值化方法。
這個方法為每個詞建立一個與詞典大小相同的向量,該詞對應的位置為 1,其他位置都是 0。
假設詞典有「我、愛、吃、蘋果、香蕉」五個詞。
「我」會被表示為 [1,0,0,0,0],「愛」是 [0,1,0,0,0],以此類推,
每個詞都有一個唯一的位置標記。
這種方法的優點是簡單直觀,容易實作和理解。
但同時缺點也很明顯,
第一個問題是「維度災難」。如果詞典有一萬個詞,每個詞就需要一萬維的向量,
造成巨大的空間浪費。
第二個問題則是「無法表達語意關係」。
「國王」和「皇后」在語意上相關,但它們的向量完全正交,看不出任何關聯。
BoW 模型統計「每個詞在文本中出現的次數」。
這種方法把文本看作一個裝滿詞彙的袋子,只關心詞出現了幾次,不管順序。
例如「我愛吃蘋果」和「我愛吃香蕉」在 BoW 中會被表示為兩個計數向量。
如果詞典是「我、愛、吃、蘋果、香蕉」,前者是 [1,1,1,1,0],後者是 [1,1,1,0,1]。
BoW 的主要問題是丟失了詞序資訊。「我咬狗」和「狗咬我」意思完全相反,
但在 BoW 中的表示完全相同。這在需要理解句子結構的任務中會造成問題。
TF-IDF 是 BoW 的改良版本。它不只計算詞頻,還考慮了詞的「稀有程度」。
這個方法基於一個直觀的想法:常見的詞鑑別力低,罕見的詞更有特色。
TF-IDF 由兩部分組成。*TF(Term Frequency)*是詞頻,表示這個詞在文件中出現的次數。
*IDF(Inverse Document Frequency)*是逆文件頻率,
計算方式是總文件數除以包含該詞的文件數,再取對數。
在美食評論中,「好吃」可能出現在 90% 的評論裡,IDF 值很低;
而「松露」只出現在 5% 的評論中,IDF 值就很高。
最後的 TF-IDF 分數是 「TF 乘以 IDF」,給予罕見詞更高的權重。
TF-IDF 在資訊檢索和文件分類任務中表現很好。
但它仍然無法捕捉詞與詞之間的語意關係,這是所有基於計數方法的共同限制。
前面介紹的方法都有一個根本問題:無法表達語意相似性。
像是前面提到的:「國王」和「皇后」明明相關,但在 One-Hot 或 BoW 中完全看不出來。
而我們現在要介紹的 Word Embedding 就可以解決這個問題。
Word Embedding 會將每個詞表示為一個密集的低維度向量(通常是 100 到 300 維)。
關鍵在於,語意相近的詞會有相近的向量表示。
這種方法基於分布假說(Distributional Hypothesis):
在相似上下文中出現的詞,往往有相似的語意。
像前面講到的「國王」和「皇后」都可能出現在「統治」、「王宮」、「權力」等詞附近,
所以它們的向量會很接近。
更令人驚奇的是,詞向量也可以進行數學運算。
最著名的例子是 King - Man + Woman ≈ Queen。
這表示詞向量不只捕捉到了相似性,還學到了詞與詞之間的關係模式。
Word2Vec 是 2013 年 Google 提出的詞向量訓練方法,至今仍被廣泛使用,
它有兩種訓練架構:CBOW 和 Skip-gram,以下我們就來介紹他的一些資訊:
CBOW(Continuous Bag of Words) 會根據上下文預測中間的詞。
給定「我」、「吃」、「蘋果」,模型要預測中間的「愛」。
我會說這有點像填空題,他會去看前後文,然後去猜出中間的詞到底是什麼。
而 Skip-gram 則相反,根據中間的詞預測周圍的上下文。
給定「愛」,模型要預測出「我」、「吃」、「蘋果」等周圍的詞。
它對罕見詞的效果較好,但相對的訓練速度較慢。
那我們該選擇何種架構呢?
選擇哪種架構取決於「資料量」和「需求」。
小資料集建議使用 CBOW,大資料集且關注罕見詞時選擇 Skip-gram。
Word2Vec 的訓練過程像是一個**「預測任務」**,
模型會掃描大量文本,嘗試預測詞與上下文的關係。
當預測越準確,模型參數就越接近最佳狀態。
模型的核心是一個淺層神經網路。輸入層接收詞的 one-hot 編碼,
隱藏層就是我們要的詞向量,輸出層預測目標詞。
訓練完成後,隱藏層的權重矩陣就是詞向量表。
而為了加速訓練,Word2Vec 使用了兩個技巧:
不計算所有詞的機率,只計算幾個負樣本。
使用二元樹結構降低計算複雜度。
這些技巧讓 Word2Vec 能在合理時間內處理數百萬詞的語料庫,增加效率。
https://python5566.wordpress.com/2018/03/17/nlp-%E7%AD%86%E8%A8%98-negative-sampling/comment-page-1/
接著我們就來實際操作斷詞的模型,看看實際它是如何運作的,
程式碼如下:
import jieba
from gensim.models import Word2Vec
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import numpy as np
# 步驟1: 準備並斷詞(使用英文資料)
raw_texts = [
"I like eating apples",
"I like eating bananas",
"Apples and bananas are delicious",
"I don't like eating guava",
"Fruits are healthy",
"Eating more fruits is good for health",
"Apples contain rich vitamins",
"Bananas provide energy"
]
# 英文直接用空格斷詞
sentences = [text.lower().split() for text in raw_texts]
print("斷詞結果範例:", sentences[0])
# 步驟2: 訓練 Word2Vec 模型
model = Word2Vec(
sentences=sentences,
vector_size=100,
window=5,
min_count=1,
sg=1,
epochs=100
)
# 步驟3: 查看訓練結果
print("\n=== 詞向量分析 ===")
print(f"「apples」的詞向量維度: {len(model.wv['apples'])}")
print(f"詞向量範例(前5維): {model.wv['apples'][:5]}")
# 尋找相似詞
similar_words = model.wv.most_similar('apples', topn=3)
print(f"\n與「apples」最相似的詞: {similar_words}")
# 計算詞語相似度
sim_score = model.wv.similarity('apples', 'bananas')
print(f"「apples」與「bananas」的相似度: {sim_score:.3f}")
sim_score2 = model.wv.similarity('apples', 'healthy')
print(f"「apples」與「healthy」的相似度: {sim_score2:.3f}")
# 步驟4: 視覺化詞向量
words_to_visualize = ['apples', 'bananas', 'guava', 'fruits', 'like', 'healthy', 'vitamins']
word_vectors = [model.wv[word] for word in words_to_visualize]
# 轉換成 numpy array
word_vectors = np.array(word_vectors)
# 使用 t-SNE 降維到 2D
tsne = TSNE(n_components=2, random_state=42, perplexity=3)
vectors_2d = tsne.fit_transform(word_vectors)
# 繪製散點圖
plt.figure(figsize=(10, 8))
plt.scatter(vectors_2d[:, 0], vectors_2d[:, 1], s=100)
for i, word in enumerate(words_to_visualize):
plt.annotate(word,
xy=(vectors_2d[i, 0], vectors_2d[i, 1]),
xytext=(5, 5),
textcoords='offset points',
fontsize=12)
plt.title("Word Embedding Visualization", fontsize=14)
plt.xlabel("Dimension 1")
plt.ylabel("Dimension 2")
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("\n視覺化完成!")
首先我們就先來講解程式碼每個部分都在幹嘛:
程式首先準備了 8 個英文句子作為訓練的材料。
這些句子包含水果、健康等主題相關的詞彙。
接著我們使用 split() 方法將每個句子按空格切分成詞語列表,
並轉換為小寫以統一格式(lower)。
程式中我們使用 Gensim 的 Word2Vec 函式訓練模型。
模型設定了幾個重要參數:
vector_size=100 表示每個詞會被表示為 100 維的向量,
window=5 表示考慮前後 5 個詞作為上下文,
sg=1 表示使用 Skip-gram 架構,
epochs=100 表示整個訓練資料會被掃描 100 次。
訓練過程中,模型會學習預測每個詞周圍的上下文詞彙。透
過不斷調整參數,讓預測越來越準確。
而在訓練完成後,模型內部的權重矩陣就是我們要的詞向量。
在步驟三我們展示了如何使用訓練好的模型。
當我們要直接查看某個詞的向量表示,就要使用 most_similar() 找出最相似的詞,
或用 similarity() 計算兩個詞之間的相似度分數。
相似度的範圍從 -1 到 1,
數值越「高」表示越「相似」。
因為詞向量是 100 維的,人類無法直接觀察,
所以我們必須使用 「t-SNE 演算法」將 100 維壓縮成 2 維,這樣就能在平面上繪製。
t-SNE 會盡量保持原本的相對距離關係,讓相似的詞在 2D 空間中也靠近。
最後使用 matplotlib 繪製散點圖,每個點代表一個詞,點的位置反映詞與詞之間的語意關係。
講解完程式碼後,我們就直接來看視覺化的結果:
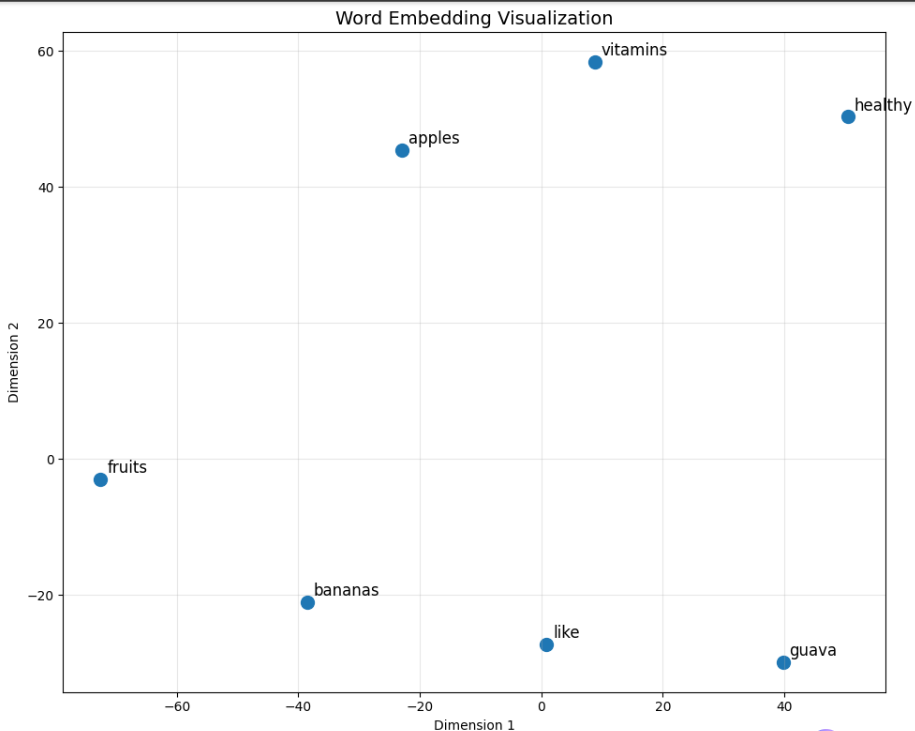
在圖的左側我們可以看到水果相關的詞彙聚集,
fruits、bananas、apples 相對靠近,因為它們都屬於水果類別,經常出現在相似的上下文中。
右上角是健康營養相關的詞彙群組,
healthy 和 vitamins 位置接近,反映了這些詞在訓練文本中經常一起出現或處於相似的語境。
like 這個動詞位於中間偏下方,與名詞類的詞保持一定距離。
這也符合詞性的差異,動詞與名詞的使用情境本來就不同。
guava 在右下角較為孤立。這是因為訓練資料中 guava 只出現一次,模型無法充分學習它與其他詞的關係,
就是訓練資料不夠的關係。
這張圖證明了: Word2Vec 可以成功從文本中學習到語意結構。
這個模型並沒有被告知哪些詞是水果、哪些詞與健康相關,
但它純粹透過分析詞彙的上下文分布就自動發現了這些語意結構,並把它們放在一起。
因為我們在訓練資料中只有放 8 個句子,所以學習效果有限。
若是在實際應用中,大部分就會使用數百萬甚至數億詞的語料庫訓練,得到的語意空間就會更加精確和豐富。
以上就是我們今天的學習了,我們今天介紹了關於NLP的一些相關知識,
也介紹了斷詞是怎麼運作的,以及文字的數值化會如何呈現。
希望今天的文章內容有幫助到各位。

