在前一篇文章裡,我們花了很多篇幅來理解 RNN(Recurrent Neural Network)的理論基礎,
包含它為什麼適合處理文字、語音和時間序列這類資料。
而在今天,我們要透過一個小型的實作來感受 RNN 的魅力,
並嘗試讓電腦學會「文字接龍」:
給定一個文字開頭,模型能夠自動預測接下來的文字。
透過這個簡單卻又直觀的練習,希望其能夠幫助我們看到 RNN 是怎麼
一步一步「記住上下文」並進行預測的。
在這個例子裡,我們會使用一段簡單的英文文字資料。
由於我們不是在做大規模訓練,所以即使資料量不大,模型仍能展現出「預測」的效果。
而在今天的訓練中,我們直接使用 TensorFlow 內建的簡單文字。
如果是在實務上,我們也可以換成小說、歌詞,甚至是自己的筆記之類的。
程式碼如下:
import tensorflow as tf
import numpy as np
# 載入資料
text = "hello world! this is a simple text for testing recurrent neural networks."
# 建立字元字典
vocab = sorted(set(text))
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
# 把文字轉換成數字
text_as_int = np.array([char2idx[c] for c in text])
在這裡,vocab 就是所有出現過的字元集合,
例如空格、字母、驚嘆號。
char2idx 是字元到數字的對照表,而 text_as_int 則是整段「文字轉換成數字」的結果。
我們也會稱這個過程叫做「編碼」(encoding)。
RNN 模型需要學習「前後文的關係」,所以我們要把文字切成一小段一小段的序列。
舉個很簡單的例子,如果輸入 "hello worl",那麼模型的目標就是預測下一個字 "d"。
這樣訓練下來,模型才能逐步學會語言的連貫性。
因為序列長度必須小於文字總長度,否則我們就無法建立有效的訓練資料。
在這個例子中,我們的文字只有 73 個字元,所以序列長度應該設定得更小。
而此段的程式碼如下:
# 設定序列長度(必須小於文字總長度)
seq_length = 10
examples_per_epoch = len(text)//(seq_length+1)
# 使用 tf.data 建立 dataset
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
# 轉成序列
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)
# 建立輸入/標籤 pair
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)
這裡的 split_input_target 很關鍵。它會把每個序列切成「輸入」和「標籤」。
例如 [h, e, l, l, o] → 輸入 [h, e, l, l],標籤 [e, l, l, o]。
換個說法,就是要模型學會「看到前一個字,預測下一個字」。
在模型訓練時,我們不會一次把所有資料都送進去,而是把資料分成一個一個批次(batch)。
這樣做有兩個好處:
第一,可以避免記憶體不足;
第二,可以讓模型在每個批次中隨機化資料,避免學習順序造成偏差。
# 設定批次大小
BATCH_SIZE = 2
BUFFER_SIZE = 10
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
這裡的 BATCH_SIZE 設定為 2,也就是模型每次會處理 2 組輸入輸出配對。
BUFFER_SIZE 設為 10,代表在建立批次前會隨機打亂這些資料,確保模型學習過程更加穩定。drop_remainder=True 則是為了確保每個批次大小一致,避免最後一批資料數量不足。
接下來就是進入最關鍵的部分,我們要來建立一個簡單的 RNN 模型。
在建立模型之前,我們先設定幾個重要的參數:
vocab_size 是字典的大小,也就是所有可能的字元數量;
embedding_dim 是字元向量的維度;
rnn_units 是 RNN 層中神經元的數量。
# 設定模型參數(針對小資料集調整)
vocab_size = len(vocab)
embedding_dim = 32
rnn_units = 64
# 建立模型
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim),
tf.keras.layers.SimpleRNN(rnn_units,
return_sequences=True,
recurrent_initializer='glorot_uniform'),
tf.keras.layers.Dense(vocab_size)
])
在這個模型中,第一層是 Embedding 層,
它的功能是把文字編碼(數字形式)轉換成「向量」表示,
這樣模型才能更好地理解字與字之間的關係。
接著是 SimpleRNN 層,這是 RNN 的核心部分,它能逐字處理序列,
並且把過去的狀態傳遞下去,讓模型能「記得」前後文。
最後一層則是 Dense 層,它會輸出對應字典大小的機率分佈,也就是模型對「下一個字元」的預測。
模型架構完成之後,我們就需要定義損失函數,並且開始訓練模型。
這裡我們使用 sparse categorical crossentropy 來計算模型預測與真實答案之間的差距
(這個在之前的實作文章內有講過),並且選擇 Adam 這個常見的優化器來更新權重。
由於資料量很小,我們需要增加訓練的 epoch 數量,讓模型有更多機會學習。
讓我們先來看程式碼:
# 定義損失函數
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
# 編譯模型
model.compile(optimizer='adam', loss=loss)
# 訓練模型(增加訓練次數)
history = model.fit(dataset, epochs=30)
在這個訓練過程中,我們設定讓模型跑 30 個 epoch,
也是由於資料量很少,需要更多的訓練輪數才能讓模型充分學習。
而隨著訓練的進行,如果發現損失值逐漸下降,代表模型在逐步學會如何預測序列,
不過要注意的是,由於訓練資料只有 73 個字元,生成的文字很可能不會太流暢,
但至少能看見模型學到了字元分布和一些基本的模式。
我認為這是可以讓我們花比較少時間訓練,但還是能學習到東西的好方法。
訓練完成後,接下來就是我覺得整個實作最有趣的部分 —— 讓模型生成文字。
在這裡,我們會給定一個起始字串,模型會依據這個字串一步一步預測下一個字元,
然後將預測結果接在輸入後面,再繼續生成,直到達到我們設定的長度。
話不多說,上程式碼:
# 文字生成函數
def generate_text(model, start_string):
num_generate = 200
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
temperature = 1.0
for i in range(num_generate):
predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0)
# 只取最後一個時間步的預測
predictions = predictions[-1, :] / temperature
predicted_id = tf.random.categorical(tf.expand_dims(predictions, 0), num_samples=1)[0,0].numpy()
# 將新預測的字元加入輸入序列
input_eval = tf.concat([input_eval, tf.expand_dims([predicted_id], 0)], axis=1)
text_generated.append(idx2char[predicted_id])
return start_string + ''.join(text_generated)
# 測試生成文字
print(generate_text(model, start_string="hello"))
這裡的 start_string 是我們給模型的起始字,例如 "hello"。
temperature 參數則控制生成文字的隨機性:
如果溫度很低(例如 0.2),模型生成的文字會比較保守,幾乎只會選最可能的字;
反之如果溫度很高(例如 1.5),模型生成的文字會更有創意,但同時也更隨機。
透過這個迴圈,模型每次會預測一個字元,然後把它加回輸入,再繼續下一輪的預測。
如此一來,我們就能得到一段連續的文字。
首先先讓我呈現一次完整的程式碼:
import tensorflow as tf
import numpy as np
# 1. 準備資料
text = "hello world! this is a simple text for testing recurrent neural networks."
vocab = sorted(set(text))
char2idx = {u:i for i, u in enumerate(vocab)}
idx2char = np.array(vocab)
text_as_int = np.array([char2idx[c] for c in text])
# 2. 建立輸入序列
seq_length = 10 # 修改:從100改為10
examples_per_epoch = len(text)//(seq_length+1)
char_dataset = tf.data.Dataset.from_tensor_slices(text_as_int)
sequences = char_dataset.batch(seq_length+1, drop_remainder=True)
def split_input_target(chunk):
input_text = chunk[:-1]
target_text = chunk[1:]
return input_text, target_text
dataset = sequences.map(split_input_target)
# 3. 建立資料批次
BATCH_SIZE = 2 # 修改:從64改為2
BUFFER_SIZE = 10 # 修改:從10000改為10
dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE, drop_remainder=True)
# 4. 建立模型
vocab_size = len(vocab)
embedding_dim = 32 # 修改:從256改為32
rnn_units = 64 # 修改:從1024改為64
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim), # 修改:移除batch_input_shape
tf.keras.layers.SimpleRNN(rnn_units,
return_sequences=True,
recurrent_initializer='glorot_uniform'), # 修改:移除stateful=True
tf.keras.layers.Dense(vocab_size)
])
# 5. 模型訓練
def loss(labels, logits):
return tf.keras.losses.sparse_categorical_crossentropy(labels, logits, from_logits=True)
model.compile(optimizer='adam', loss=loss)
history = model.fit(dataset, epochs=30) # 修改:從10改為30
# 6. 文字生成
def generate_text(model, start_string):
num_generate = 50 # 修改:從200改為50
input_eval = [char2idx[s] for s in start_string]
input_eval = tf.expand_dims(input_eval, 0)
text_generated = []
temperature = 1.0
for i in range(num_generate):
predictions = model(input_eval)
predictions = tf.squeeze(predictions, 0)
predictions = predictions[-1, :] / temperature # 修改:只取最後一個時間步
predicted_id = tf.random.categorical(tf.expand_dims(predictions, 0), num_samples=1)[0,0].numpy()
input_eval = tf.concat([input_eval, tf.expand_dims([predicted_id], 0)], axis=1) # 修改:使用concat
text_generated.append(idx2char[predicted_id])
return start_string + ''.join(text_generated)
print(generate_text(model, start_string="hello"))
接著,我們就來看模型在訓練之後,都學到了什麼:
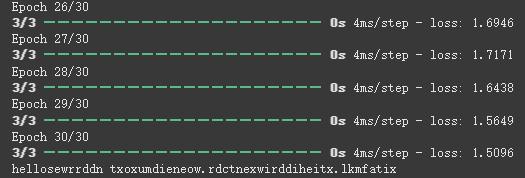
最後一行「hellosewrrddn txoxumdieneow.rdctnexwirddiheitx.lkmfatix」
就是我們訓練後模型所生成的結果。
在觀察結果後,我發現模型成功學到了幾個重要的規律:
首先,它知道要使用我訓練資料中出現過的字元,
像是 e、l、r、o、t、w、x、i、n 這些字母都在原始文字中出現過。
再來,它也知道要用空格來分隔單字,而且還會適時使用句點作為標點符號。
最後,它注意到某些字母應該出現得比較頻繁,
例如 e、r、t 這些高頻字母在生成的文字中也出現得比較多。
更有趣的是,我們可以觀察到模型生成了一些「看起來像單字」的組合,
例如 sewrrddn 和 txoxumdieneow。
雖然這些不是真正的英文單字,但它們的長度和結構看起來有那麼一點英文單字的感覺。
這表示模型隱約學到了「單字應該有一定長度」和「字母不是完全隨機排列」這些概念。
不過模型完全無法拼出真實的英文單字。
它不知道 hello 後面通常會接 world,
也不知道 this 或 simple 這些訓練資料中出現過的完整單字。
模型更不理解任何語法或語義,生成的句子沒有任何實際意義。
其實原因也很簡單,就是訓練資料太少了。
73 個字元大約只有 10 個單字,模型根本沒有足夠的範例來學習真正的語言規律。
這就像是你只看過 10 個中文詞彙,然後要你寫一篇文章,當然寫不出來。
模型現在處於一種「知道遊戲規則,但不知道怎麼玩」的狀態。
它知道要用這些字母、要用空格、要有標點符號,
但它不知道這些元素該如何正確組合成有意義的語言。
這個結果其實很有教學價值。它清楚展示了深度學習的一個核心原則:
模型的學習能力完全受限於資料量。
即使是最簡單的語言生成任務,也需要大量的訓練資料才能學到有意義的模式。
這個實驗也讓我們看到 RNN 的學習是分層次的。在資料量極少的情況下,
模型只能學到最表面的統計特徵(字元分布、空格使用)。
如果要學習更深層的規律(單字拼寫、語法結構),則需要指數級增加的資料量。
以上就是我們今天的學習了,
下一篇,我們將開始挑戰 LSTM(長短期記憶網路),
看看它是如何幫助 RNN 克服「遺忘問題」的!

