
目標先講清楚:
用 OpenMemory MCP,讓 Mem0 記憶「一次設定、到處可用」
add_memories:儲存新的記憶體物件search_memory:檢索相似/相關記憶list_memories:查看所有已儲存記憶delete_all_memories:一鍵清空記憶庫起好服務後,有提供各應用的安裝指令
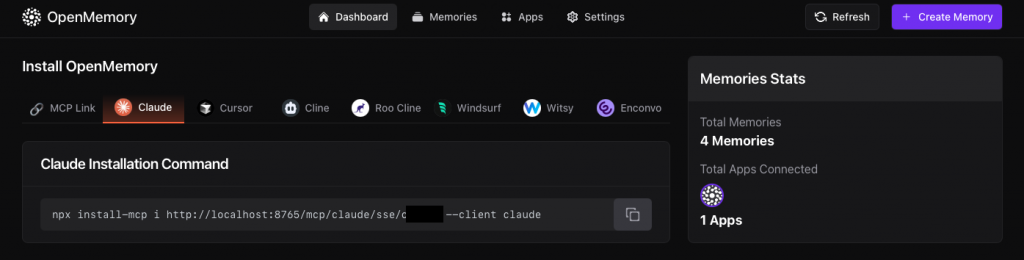
也有提供MCP Link給支援MCP的框架使用;以langGraph的框架為例
from langchain_mcp_adapters.client import MultiServerMCPClient
client = MultiServerMCPClient(
{
"openmemorymcp": {
"transport": "sse",
# 貼上MCP Link
"url": "http://host.docker.internal:8765/mcp/openmemory/sse/xxxx",
}
}
)
記憶資料預設存在本機,後端向量庫採 Qdrant;Docker 一鍵帶起 API、UI 與 DB。
在使用
add_memories過程會呼叫 LLM 將一句話拆成多個可檢索的事實/偏好(例如:姓名、職稱、公司、喜好等),方便後續的語意檢索與個別更新。
輸入:「我叫王大明,是 A 公司採購,喜歡紅眼班機。」
被拆為:a) 使用者姓名是 王大明、b) 在 A 公司任職採購、c) 偏好 紅眼班機。
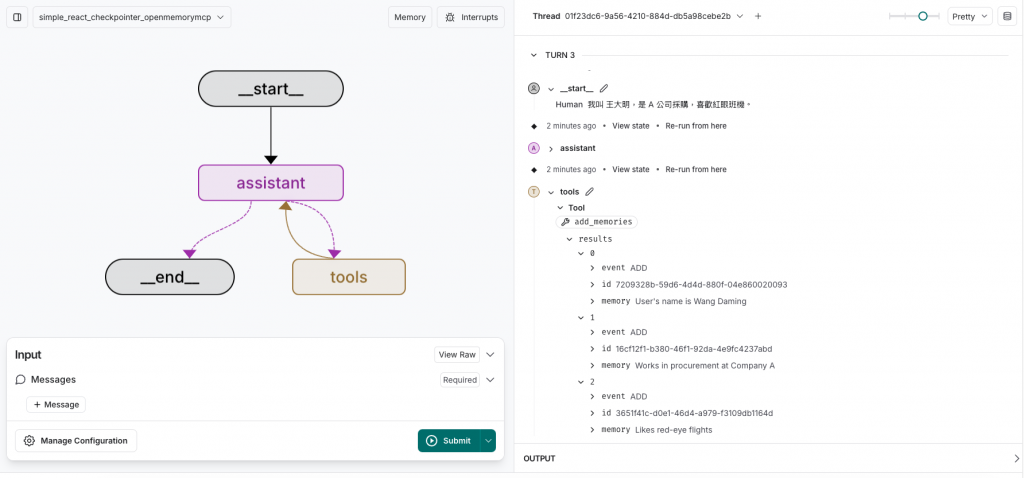
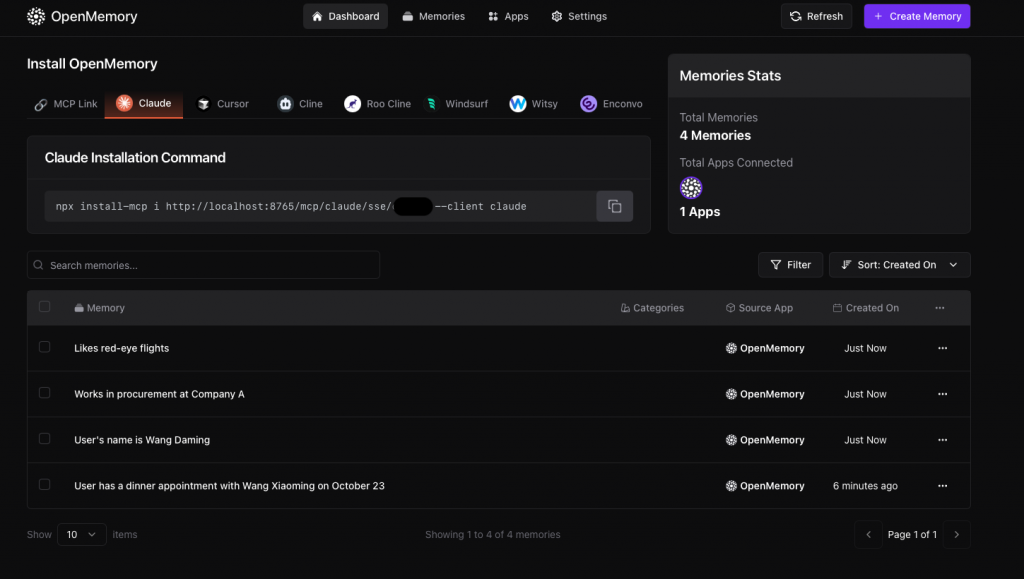
在Dashboard也可以對這些記憶進行修改
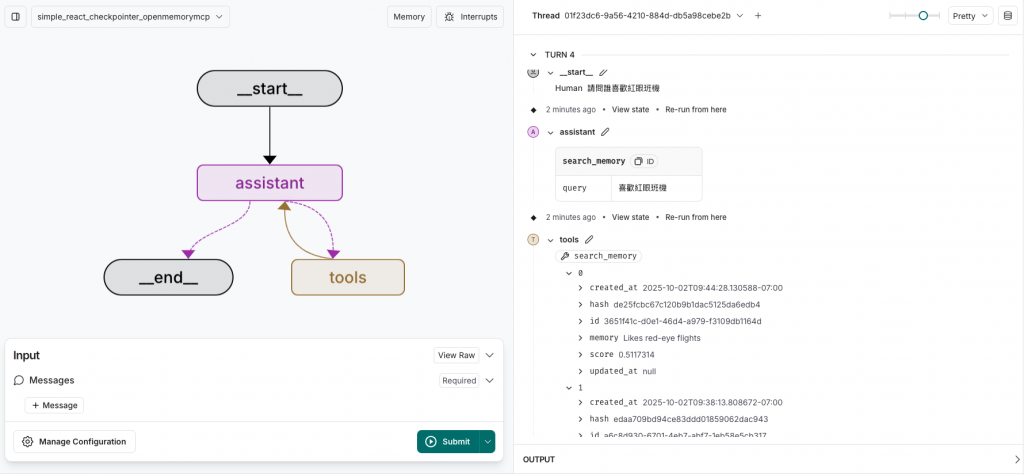
OpenMemory MCP 的
search_memories走的是向量相似度檢索,這讓「用戶當下問題」能與「歷史記憶」做語意比對,而非只看關鍵字。
當詢問問題-「誰喜歡紅眼班機」,除了提供正確答案,還可以看到分數
當你在LangGraph增加的記憶,也可以在claude Desktop調用OpenMemory MCP拿到資料
(在langGraph服務寫入的記憶)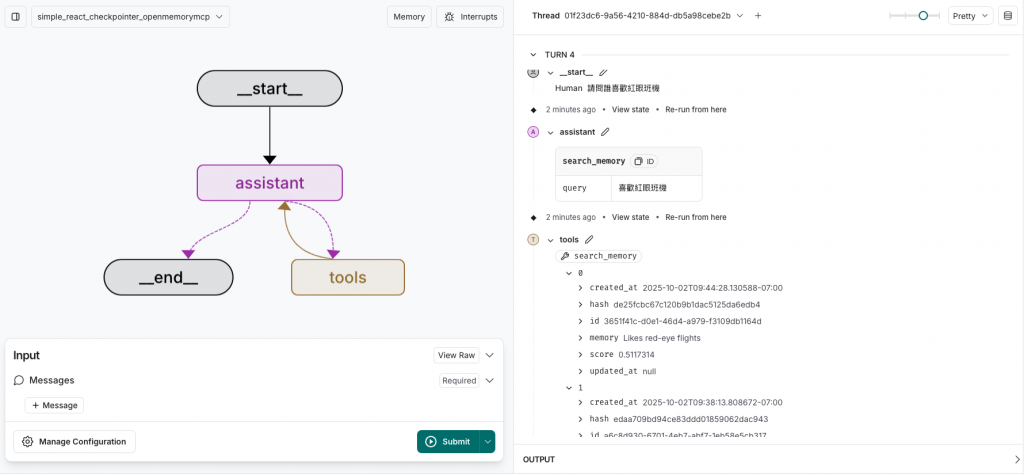
(在claude desktop進行記憶調用)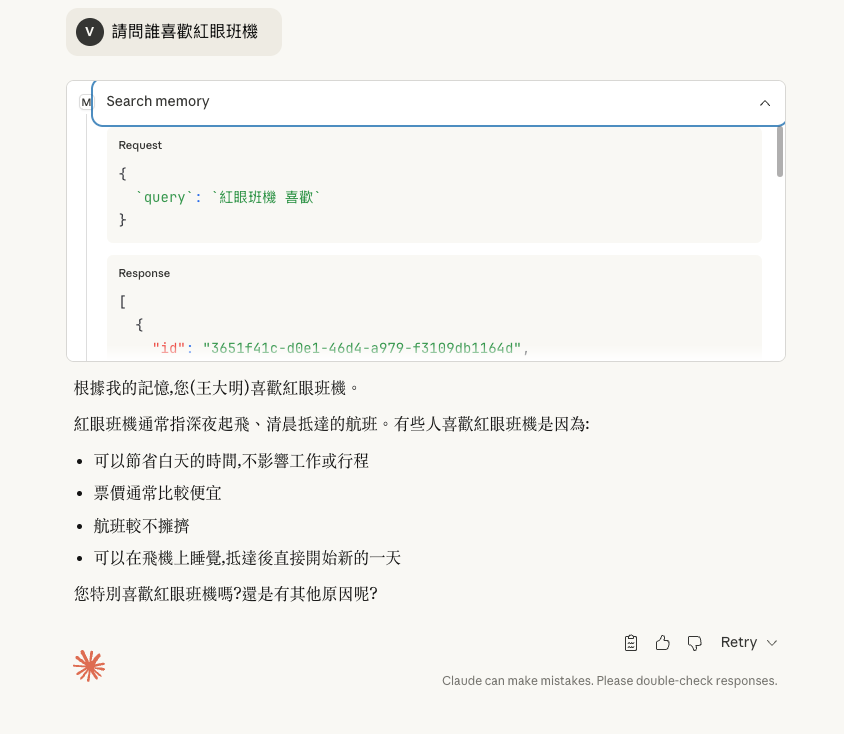
這個功能,如果一個系統有不同的agent的框架,可以方便共享記憶,讓跟使用者的互動更順利
會再回到mem0,探討為什麼事實記憶(Facts)是搭配向量資料庫,而情節記憶(Episodic / History)是搭配SQL資料庫
