目標先講清楚:
mem0怎麼使用向量資料庫跟關聯資料庫去管理記憶
在了解mem0針對不同的記憶類型,有不同的資料庫進行管理後,對於其中事實記憶和情節記憶非常好奇:記憶如何存到向量資料庫?長文本會不會造成效能問題?情節記憶是怎麼跟服務搭配?
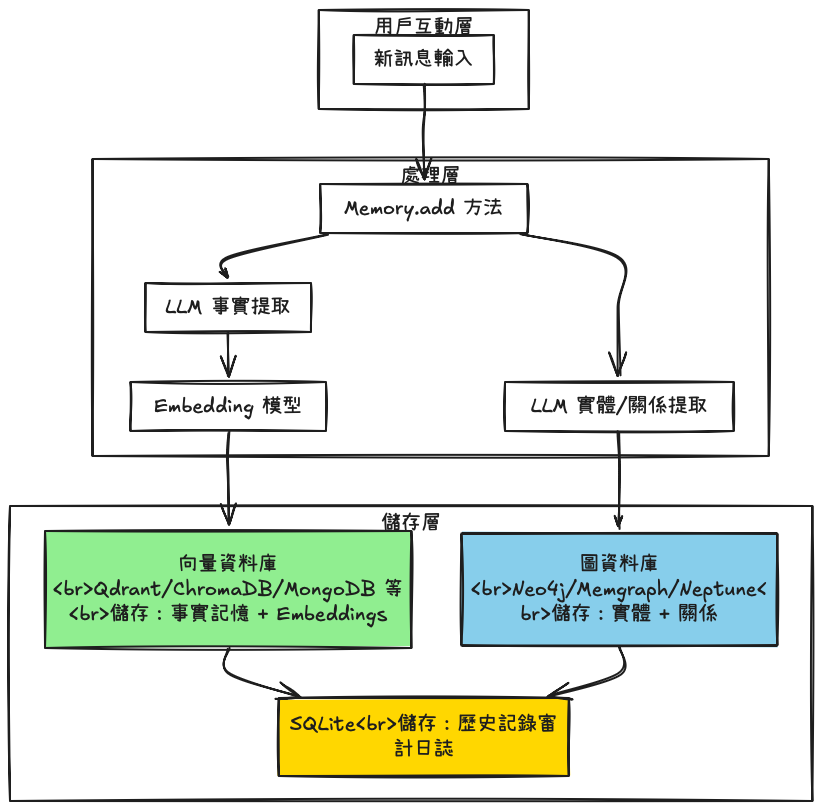
Mem0 在創建記憶時會自動生成唯一的 memory_id,作為key:
python# 來源:mem0/memory/main.py - _create_memory 方法
def _create_memory(self, data, existing_embeddings, metadata=None):
embeddings = self.embedding_model.embed(data, memory_action="add")
memory_id = str(uuid.uuid4()) # 自動生成唯一 ID
metadata = {
"data": data,
"hash": hashlib.md5(data.encode()).hexdigest(),
"created_at": datetime.now(timezone.utc).isoformat(),
# ... 其他元資料
}
# 插入向量資料庫
self.vector_store.insert(
vectors=[embeddings],
ids=[memory_id], # UUID 作為主鍵
payloads=[metadata]
)
return memory_id
關鍵機制:
| 操作 | Key 來源 | 說明 |
|---|---|---|
| 新增 | 自動生成 UUID | 系統分配唯一識別碼 |
| 查詢 | 語義相似度搜尋 | 不依賴 key,透過向量距離 |
| 更新 | 使用既有 memory_id | LLM 決策後用 UUID 定位 |
| 刪除 | 使用既有 memory_id | 直接用 UUID 刪除 |
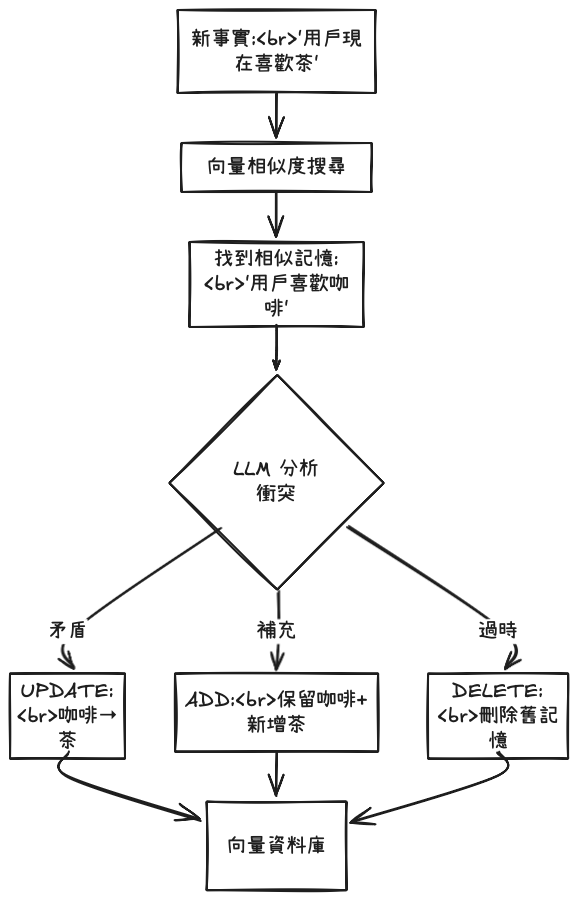
Mem0 的更新機制不依賴傳統的 key-value 對應,而是透過語義相似度 + LLM 決策:
python# 來源:mem0/memory/main.py - _add_to_vector_store 方法
def _add_to_vector_store(self, messages, metadata, filters, infer):
if infer: # 默認為 True
# 步驟 1: LLM 提取新的事實
new_retrieved_facts = json.loads(response)["facts"]
for new_mem in new_retrieved_facts:
# 步驟 2: 為新事實生成 embedding
messages_embeddings = self.embedding_model.embed(new_mem, "add")
# 步驟 3: 搜尋相似的現有記憶
existing_memories = self.vector_store.search(
query=new_mem,
vectors=messages_embeddings,
limit=5,
filters=filters
)
# 步驟 4: LLM 決定操作類型
# 返回格式:
# {
# "memory_actions": [
# {"event": "ADD", "memory": "新事實"},
# {"event": "UPDATE", "memory_id": "uuid", "new_memory": "..."},
# {"event": "DELETE", "memory_id": "uuid"}
# ]
# }
LLM 決策邏輯
重點:Mem0 在 infer=True 模式下(默認),不會直接存儲長文本,而是提取關鍵事實。
範例:假設輸入一個 5000 行的代碼規格文檔:
python# 長文本輸入
long_spec = """
[5000 行的詳細代碼規格]
包含:
- 架構設計圖
- 詳細的 API 定義
- 完整的數據模型
- 業務邏輯說明
- ... 總計約 50,000 tokens
"""
# Mem0 處理
result = memory.add(
messages=[{"role": "user", "content": long_spec}],
user_id="developer_001",
infer=True # 啟用事實提取
)
LLM 提取結果
python# LLM 提取的事實(來源:實際運作邏輯)
extracted_facts = [
"使用 RESTful API 架構",
"數據庫選用 PostgreSQL",
"認證採用 JWT",
"前端使用 React + TypeScript",
"部署環境為 AWS",
"支持微服務架構",
# ... 約 20-50 個關鍵事實
]
# 存儲量對比
# 原始:50,000 tokens
# 實際存儲:~2,000 tokens
# 壓縮比:96%
這個記憶從代碼看來,比較像是當作聊天歷程的紀錄,而不會送進LLM
sql-- 來源:mem0/memory/storage.py - SQLiteManager._create_history_table
CREATE TABLE IF NOT EXISTS history (
id TEXT PRIMARY KEY, -- 歷史記錄 ID
memory_id TEXT, -- 關聯的記憶 ID(外鍵)
old_memory TEXT, -- 更新前的值
new_memory TEXT, -- 更新後的值
event TEXT, -- 事件類型:ADD/UPDATE/DELETE
created_at DATETIME, -- 創建時間
updated_at DATETIME, -- 更新時間
is_deleted INTEGER, -- 刪除標記
actor_id TEXT, -- 執行操作的用戶/代理
role TEXT -- 角色
)
關鍵特點:
python# 來源:mem0/memory/storage.py - SQLiteManager.get_history
def get_history(self, memory_id: str) -> List[Dict[str, Any]]:
with self._lock:
cur = self.connection.execute(
"""
SELECT id, memory_id, old_memory, new_memory, event,
created_at, updated_at, is_deleted, actor_id, role
FROM history
WHERE memory_id = ?
ORDER BY created_at ASC, DATETIME(updated_at) ASC
""",
(memory_id,),
)
rows = cur.fetchall()
return [
{
"id": r[0],
"memory_id": r[1],
"old_memory": r[2],
"new_memory": r[3],
"event": r[4],
"created_at": r[5],
"updated_at": r[6],
"is_deleted": bool(r[7]),
"actor_id": r[8],
"role": r[9],
}
for r in rows
]
查詢特點
| 特性 | 狀態 | 影響 |
|---|---|---|
WHERE 條件 |
使用 memory_id |
需要全表掃描(無索引) |
ORDER BY |
兩個時間欄位 | 需要額外排序 |
LIMIT |
沒有 | 返回所有歷史記錄 |
根據代碼分析,history 方法主要用於:
python# 來源:Memory 類的 history 方法使用場景
# ✅ 開發者手動查詢
history = memory.history(memory_id="892db2ae-...")
# ✅ 審計追蹤
for record in history:
print(f"{record['event']}: {record['old_memory']} → {record['new_memory']}")
# ❌ 不會自動傳給 LLM
# ❌ 不參與記憶搜尋
# ❌ 不影響記憶更新決策
重要結論:歷史記錄是純粹的審計日誌,不參與 AI 的記憶處理流程。
分享向量資料庫的更新策略