
RAG 檢索增強生成,全名叫 Retrieval Augmented Generation,真的當初看到它時我在想他在供啥小。然後看了一下 openai 的文件後,我覺得他這段話說的很好讓我懂。
Retrieval Augmented Generation (RAG) is a technique that improves a model’s responses by injecting external context into its prompt at runtime. Instead of relying solely on the model’s pre-trained knowledge, RAG retrieves relevant information from connected data sources and uses it to generate a more accurate and context-aware response.
檢索增強生成(RAG)是一種技術,能夠在執行時將外部資料注入模型的提示(prompt),讓模型產生更精準、更具上下文的回應。RAG 不僅依賴模型的預訓練知識,還會從連接的資料來源中檢索相關資訊,補充生成過程中的背景。
當時我看到時第一時間在想,好像聽起來就是根據『 用戶的問題,然後先產生出這個問題的相關 Context,然後再喂給 LLM 』。
但那時我就在想,那這樣我就在收到問題時,然後自已產生一段 Context 在一起加到 prompt 中,最後再丟給 LLM 不就好 ? 那這樣幹麻還說的得高大上的感覺呢 ?
例如文件有提到說 RAG 的價值,就有說到一個範例,大約如下 :
假設你在開發一個幫助客服團隊回答產品問題的 GPT。基礎模型雖然有廣泛的通用知識,但並不了解你產品的最新更新記錄或幫助中心的內容。然後透過 RAG 就可以做到讓 GPT 去取得到你的產品知識與最新訊息。
然後我那時就在想,這樣不就只要當用戶訊息我們公司相關資訊時,然後用 Function Calling 回傳需要的公司資料就好 ?
後來想想有幾個問題 :
所以我自已覺得 RAG 真正想要做到的是 :
進行 Retrieval 流程,整理 ( Indexing ) 與找出 ( Query ) 『 好 』的 Context,然後可以讓 LLM ( Augmented、Generation ) 答出更好的答案。
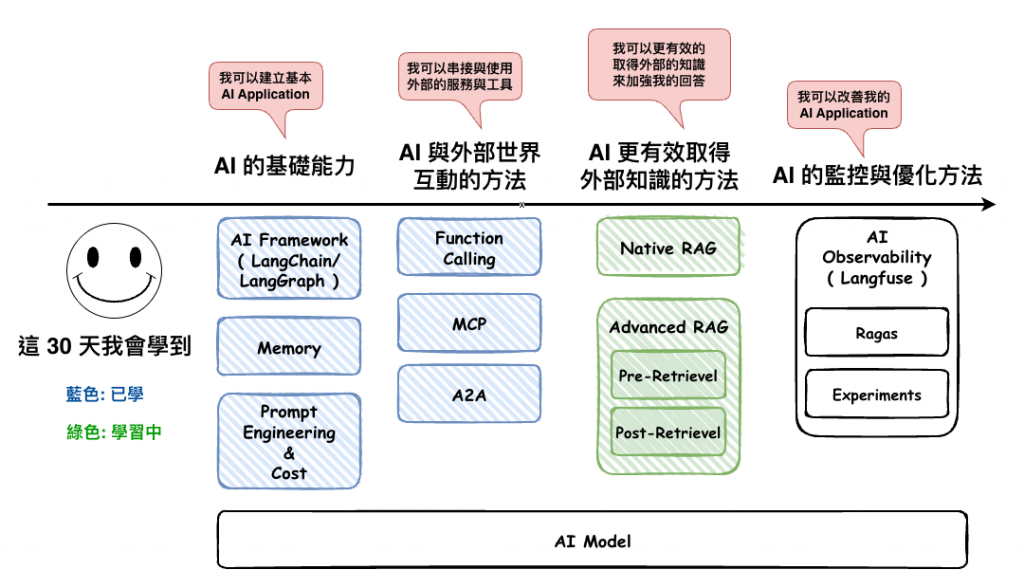
RAG 整個流程可以分兩大部份 :
整個 RAG 流程事實上就是分這兩個,但是這兩個裡面會有很多詳細,再下二篇將會詳細的說明。
🤔 是否一定要用向量資料庫
事實上不一定要,因為我們的目的一直以來都是 :
找到最適合的上下文加入到 Prompt
所以如果你用其它資料庫,又或是用 Elasticsearch 就可以找到你要的上下文,那就不用向量資料庫。
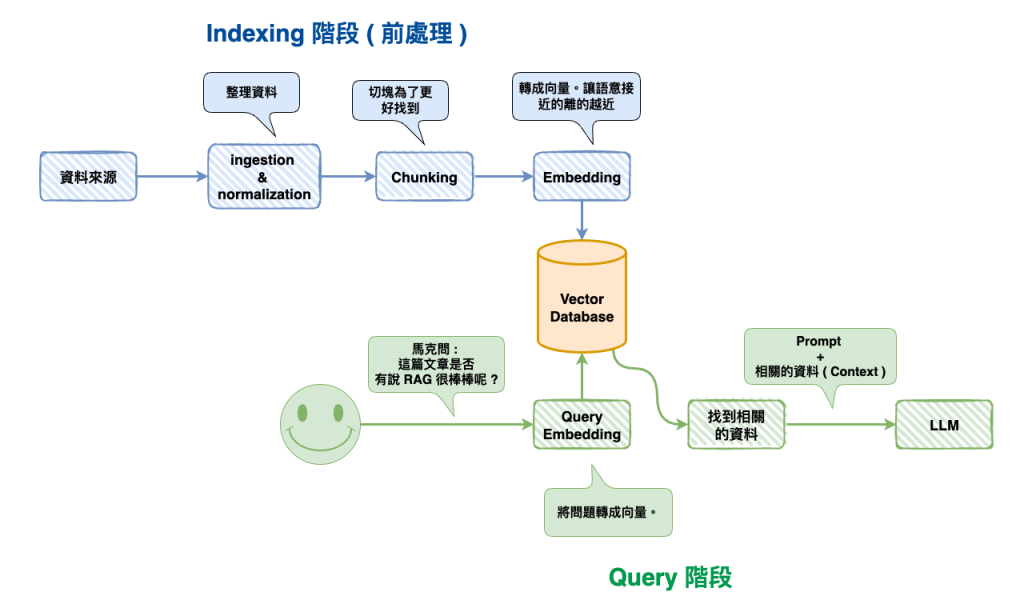
這裡用 LangChain 寫個最簡單的 RAG 範例,然後就是如上面一樣分成兩部份 Indxing 與 Retrieval。
🤔 Step 1. Indexing
import { OpenAIEmbeddings } from "@langchain/openai";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { ChatOpenAI } from "@langchain/openai";
async function indexing() {
// 1. 資料
const documents = [
"馬克是個好人",
"馬克的年齡是20歲",
"馬克的身高是180cm",
"馬克的體重是70kg",
"馬克的職業是工程師",
"馬克的愛好是打電動",
"馬克的興趣是看書",
"馬克的興趣是切東西"
];
// 2. Chunking
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 100,
chunkOverlap: 20,
});
const docs = await textSplitter.createDocuments(documents);
const embeddings = new OpenAIEmbeddings({
modelName: "text-embedding-3-small",
});
// 3. Embedding
const vectorStore = await MemoryVectorStore.fromDocuments(docs, embeddings);
return vectorStore;
}
🤔 Step 2. Query
async function query(vectorStore: MemoryVectorStore) {
// 1. 從向量資料庫中找出相關的 Context
const retriever = vectorStore.asRetriever({
k: 2, // 返回最相關的 2 個文檔
});
const contexts = await retriever.invoke("馬克喜歡什麼?");
console.log("contexts", contexts);
// 2. 將 Context 加到 Prompt 中
const llm = new ChatOpenAI({
modelName: "gpt-5-mini",
});
const answer = await llm.invoke([
{
role: "system",
content: `Context: ${contexts.map((doc) => doc.pageContent).join("\n")}`,
},
{
role: "user",
content: "馬克喜歡什麼?",
},
]);
console.log("answer", answer);
return context;
}
🤔 執行與結果
概念簡單吧,就是先 indexing 後,再來查詢資料,然後再加到 Prompt 上。
(async () => {
const vectorStore = await indexing();
await retrieval(vectorStore);
})();
// Console Log 的結果---------------------------------------------------
context [
Document {
pageContent: '馬克的興趣是看書',
metadata: { loc: [Object] },
id: undefined
},
Document {
pageContent: '馬克是個好人',
metadata: { loc: [Object] },
id: undefined
}
]
answer AIMessage {
"id": "chatcmpl-CMtJ5be3Z9jnBeB6N0jiUKhxymjff",
"content": "馬克喜歡看書。",
"additional_kwargs": {},
"response_metadata": {
"tokenUsage": {
"promptTokens": 35,
"completionTokens": 144,
"totalTokens": 179
},
"finish_reason": "stop",
"model_provider": "openai",
"model_name": "gpt-5-mini-2025-08-07"
},
"tool_calls": [],
"invalid_tool_calls": [],
"usage_metadata": {
"output_tokens": 144,
"input_tokens": 35,
"total_tokens": 179,
"input_token_details": {
"audio": 0,
"cache_read": 0
},
"output_token_details": {
"audio": 0,
"reasoning": 128
}
}
}
https://docs.langchain.com/oss/javascript/integrations/providers
LangChain 在 RAG 這塊事實上有整合了不少東西,處了基本的功能,還有串接了其它第三方服務相關的東西,主要分這三大塊 :
然後以 Retrievers 為例,它就是可以直接去 Arxiv 這個地方取得到論文的資訊來。順到說一下 Arxiv 就是很多論文作者在正式發表論文前或審核的同時會上傳的公開地方,它是一個免費的知識庫,目前我很多 AI 相關的論文也都是在這裡看到的。
然後下面是範例程式碼,我們在這裡就不用做 indexing 的過程,因為已經處理好了,然後我們這裡就是可以直接用以下的方法取得到 Context 來將下一步會帶入到我們的 Prompt 中,但我們這裡就只寫到這就好。
所以如果你是用 LangChain 來做 RAG 可以先看看整合的部份有沒有已經有你要用的東西了,這樣就可以省掉一些時間
import { ArxivRetriever } from "@langchain/community/retrievers/arxiv";
async function setupRetriever() {
console.log("📚 設定 Arxiv Retriever...\n");
const retriever = new ArxivRetriever({
getFullDocuments: false, // false = 只取摘要, true = 下載完整 PDF
maxSearchResults: 3, // 最多返回 3 篇論文
});
return retriever;
}
(async () => {
const retriever = await setupRetriever();
const contexts = await retriever.invoke("RAG");
for (const context of contexts) {
console.log(context.metadata.title);
console.log(context.metadata.published);
console.log(context.metadata.url);
console.log("--------------------------------");
}
})();
// =======================================================================
Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
2024-07-26T03:45:30Z
http://arxiv.org/abs/2407.21059v1
--------------------------------
RAG-Instruct: Boosting LLMs with Diverse Retrieval-Augmented Instructions
2024-12-31T09:00:51Z
http://arxiv.org/abs/2501.00353v1
--------------------------------
Evaluating the Performance of RAG Methods for Conversational AI in the Airport Domain
2025-05-19T11:46:30Z
http://arxiv.org/abs/2505.13006v1
--------------------------------
RAG 事實上在出來後到現在,已經有很多類型了,這裡根據以下幾篇論文簡單的說一下幾個比較有名的,然後詳細的內容,之後文章會一個一個討論,然後先說一下還不只這些,這裡只列幾個現在比較常見的。
首先是第一篇論中中,它提到將 RAG 分為三種類型 :
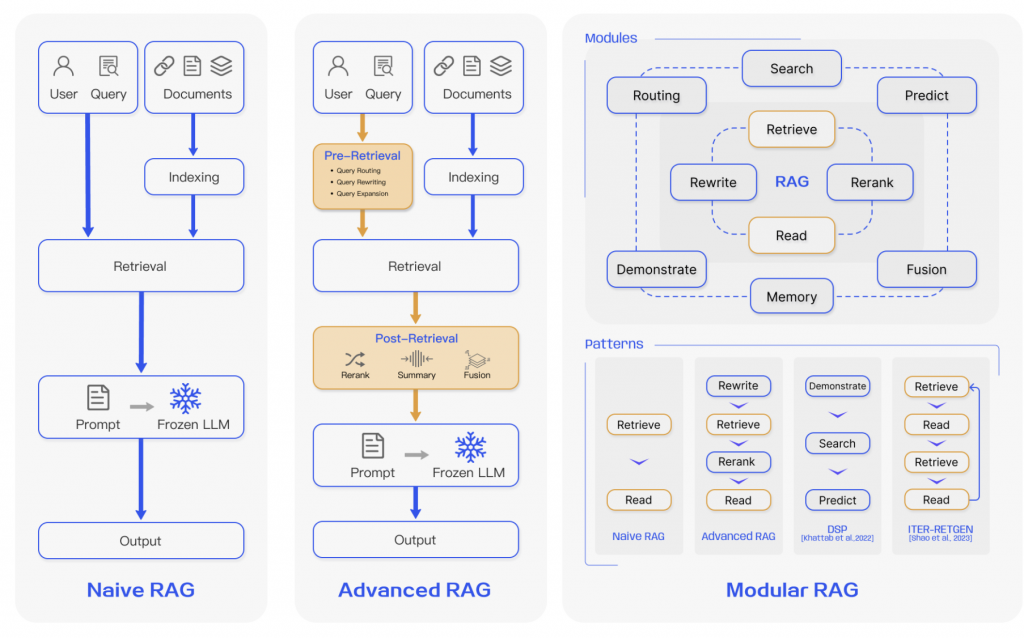
圖片來源: Retrieval-Augmented Generation for Large Language Models: A Survey
Naive RAG : 這個應該就是我們現在看到的最基本的版本。Advanced RAG : 它是為了解決 Naive RAG 不太準確的問題,它加入了兩個階段 Pre-Retrieval 與 Post-Retrieval 。Modular RAG : 它事實上有點不像是我們上面說的傳統 RAG,它比較像是為了應付不同情境,讓每個部份可以模組化,可以讓整個過程更加的彈性。( 可以想成 Naive RAG 與 Advanced RAG 都是 Modular RAG 的一種 Pattern,如上圖 )接下來又出了兩個 :
Graph RAG : 這個是將知識圖譜 ( Knowledge Graph )整合到 RAG 中的概念,利用實體之間的關係和層級結構來增強傳統 RAG 的能力。簡單的說就是如果要回答一個問題,需要理解整個知識中的關係後,才能推論與回答的情境,就適合用它。例如你丟三國志進去,然後問曹操為什麼打袁紹,這種情況下你覺得在不知道他倆的關係有辦法答嗎 ?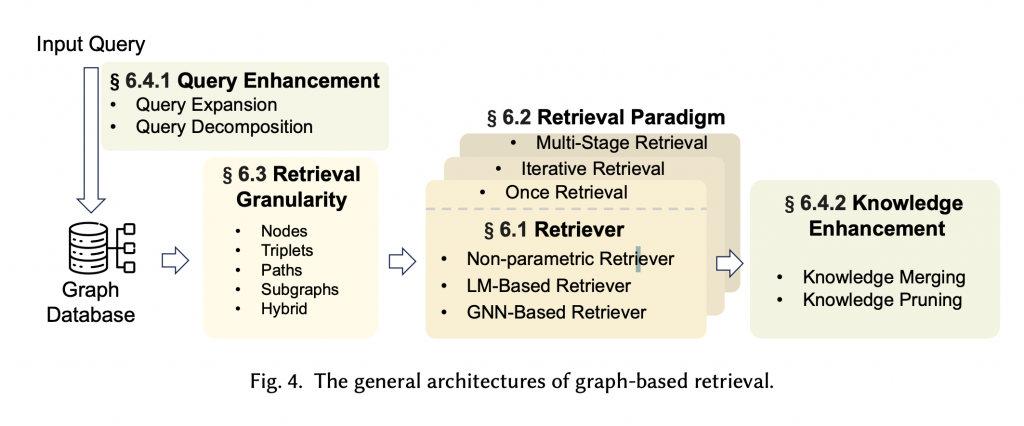
圖片來原: Graph Retrieval-Augmented Generation: A Survey
Agentic RAG : 主要就是在 RAG 流程中,導入 Agent,讓整個流程可以自主決策與優化,這裡先說個大概之後會開篇來專門說。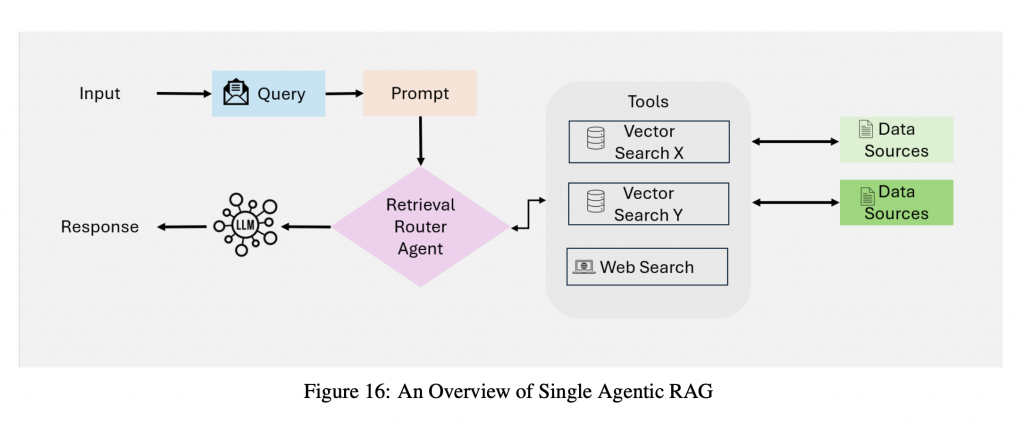
圖片來源: Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
最近在網路上看到的議題,然後會有這個問題的核心原因應該在於 :
LLM 支援越來越多的 Token
但這裡我自已的看法應該是不會,主要有幾個問題 :
🤔 1. 成本的問題
只要 LLM 供應商還是用 token 來計價,我是覺得這個就是個繞不開的問題,就算有 Input Cache 便宜個 1/10 ( 如 OpenAI ),但長期算下來還是錢。
🤔 2. 長上下文導致 LLM 的效果降低
例如最常看到的這篇,主要在說如果上下文太長,會讓 LLM 在理解中間區段,會完全變笨蛋。
Lost in the Middle: How Language Models Use Long Context :
還有這篇文章總結出的 4 個問題 :
所以目前我自已是覺得,只要這些問題還在,RAG 應該不太可能掛掉。
這個是從這篇文章中看到的,我覺得給了我很多學習的方向可以建議看看。
Retrieval-Augmented Generation for Large Language Models: A Survey ( 2023/12 )
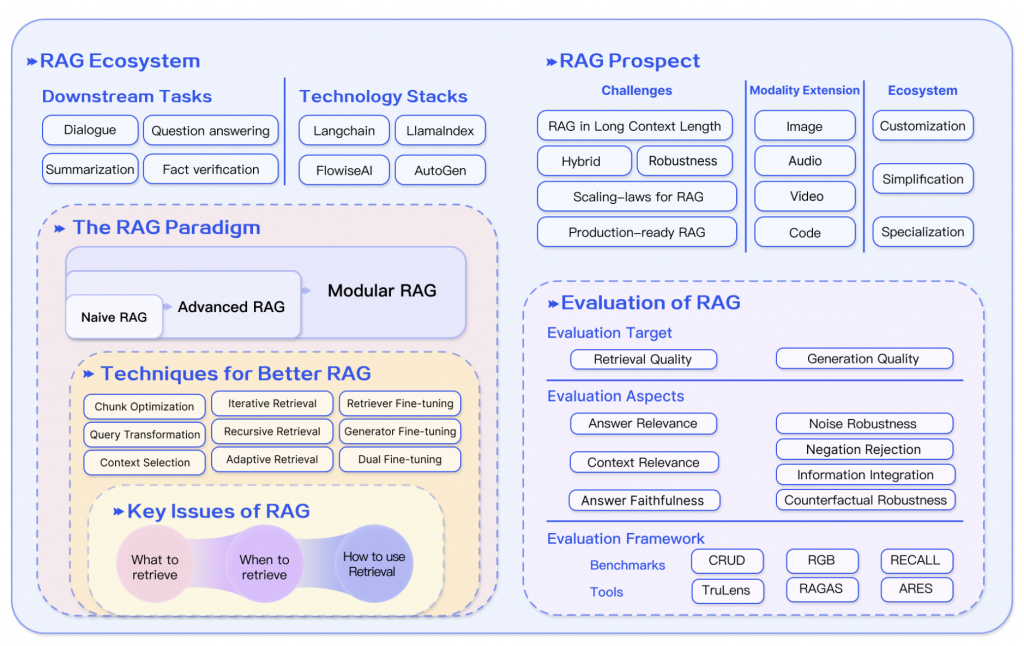
這篇文章我們將整個 RAG 體系,簡單且基本的理解過,包含了 :
接下來明天我們將要來更深入的理解 RAG 的每個部份。
