目標先講清楚:
如何讓向量資料庫中的內容,隨著來源資料更新而「持續正確」
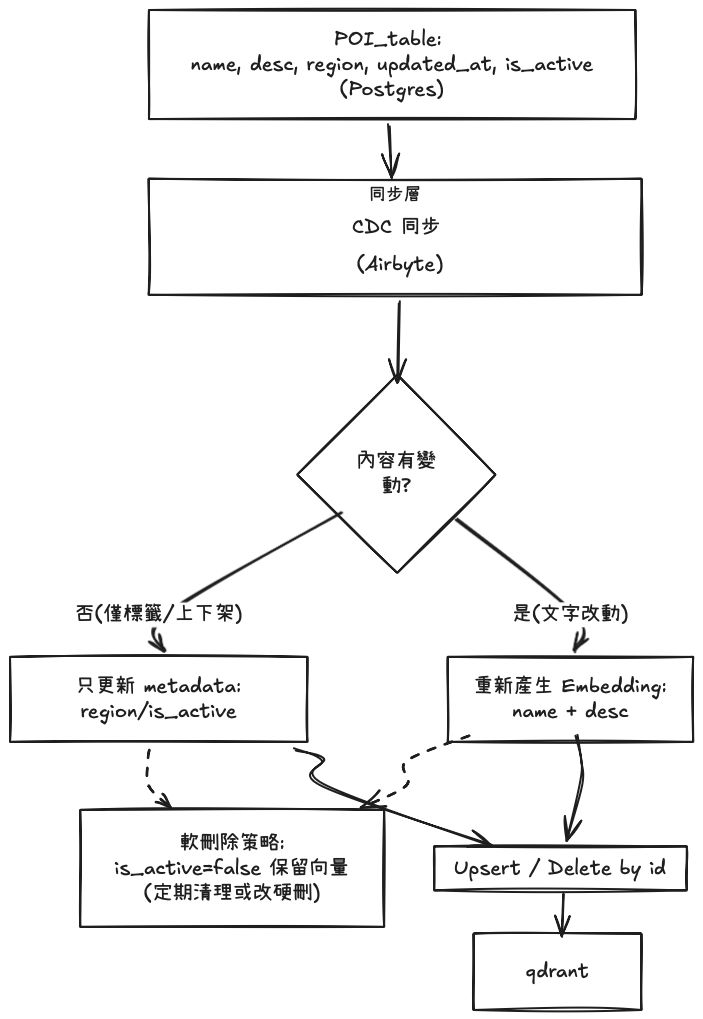
許多「會變動」的內容(菜單、報價、活動資訊、最新文章、景點資訊…)原本都存在傳統關聯式資料庫(例如 MSSQL、Postgres)。當開始做語意檢索 / RAG,就會遇到一個痛點:如何讓向量資料庫中的內容,隨著來源資料更新而「持續正確」?
提供做法:
[!NOTE]
- 如果要達到更加即時,大部分是建議使用有支援向量搜尋的資料庫(ex. postgres, mongo, elestic)
- 文章提到的情境是無法重啟或修改postgres部署設定,因此無法使用pgvector
什麼時候用?
結構化業務資料變動快(例如電商商品/庫存、價格、可賣量),需要「幾近即時」可查。
怎麼運作?
什麼時候用?
你有可程式化/基礎建設即程式(IaC)式的資料管線,希望把「Embedding/Chat 模型」當成管線資源統一管理。
怎麼運作?
embed_model.embed(text)。testdb.articles 抽「今日新文」→ 將「標題+內文」做嵌入 → 寫入 Elasticsearch 供語義/RAG 查詢。主要依據以下的原因:
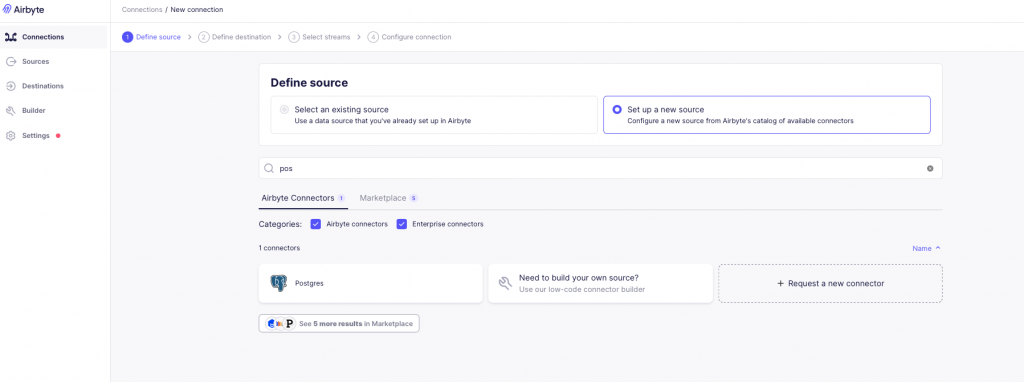
airbyte官方文件提供詳細的部署方式
跟一般的Postgres連線設定一樣
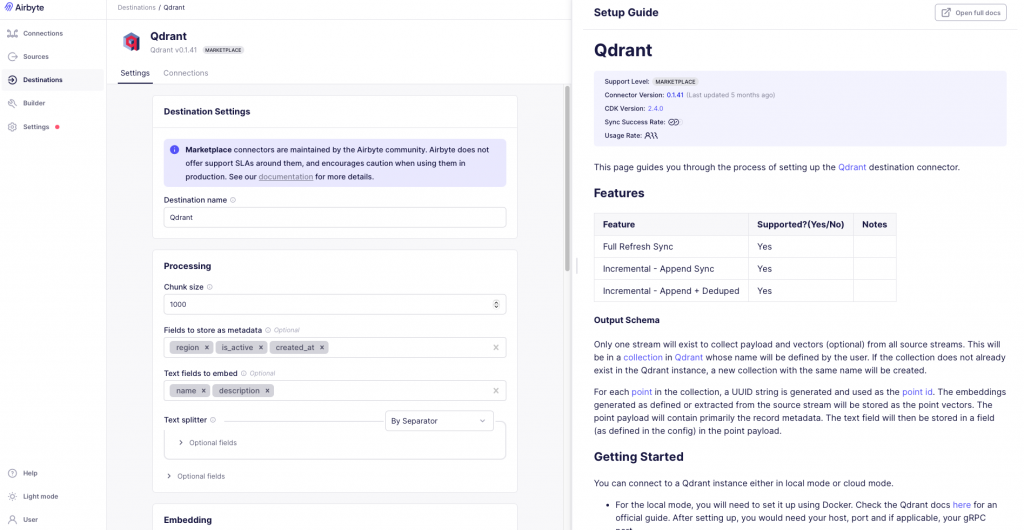
- 直接將postgres table的field,依照需求填入Fields to store as metadata欄位和Text fields to embed欄位,就會依照設定組成metadata跟embedding
- 針對「Text fields to embed欄位」,多個欄位會組成成一個字串去進行embedding
- 目前有支援ollama的edge端的embedding model
提供多種方式
分享context 處理工程的做法
1.airbyte document
2.Real-Time RAG: Streaming Vector Embeddings and Low-Latency AI Search
3.qdrant-Optimizer
4.Flink CDC YAML:面向数据集成的 API 设计