
目標先講清楚:
針對Anthropic的context engineering文章進行重點筆記
針對Anthropic發表的文章 - Effective context engineering for AI agents,探討context engineering的技術,並整理文章提到,落地時可以用到的技巧或注意事項;
這篇文章提到的內容:
什麼是上下文工程?
在推理過程中,持續策展與維護最合適的一組 tokens(資訊),讓代理在多輪對話、長時間任務中維持品質與可控性。
為什麼需要?
長上下文不是萬靈丹:Chroma 對 18 個 SOTA/旗艦模型的研究顯示,輸入越長,模型使用上下文越不均勻、可靠性下降(Context Rot);因此「放多少」「放哪裡」「先檢索再推理」變得關鍵。
小結論:把「上下文」當作稀缺資源經營:能外部化就外部化、能檢索就檢索、能壓縮就壓縮。
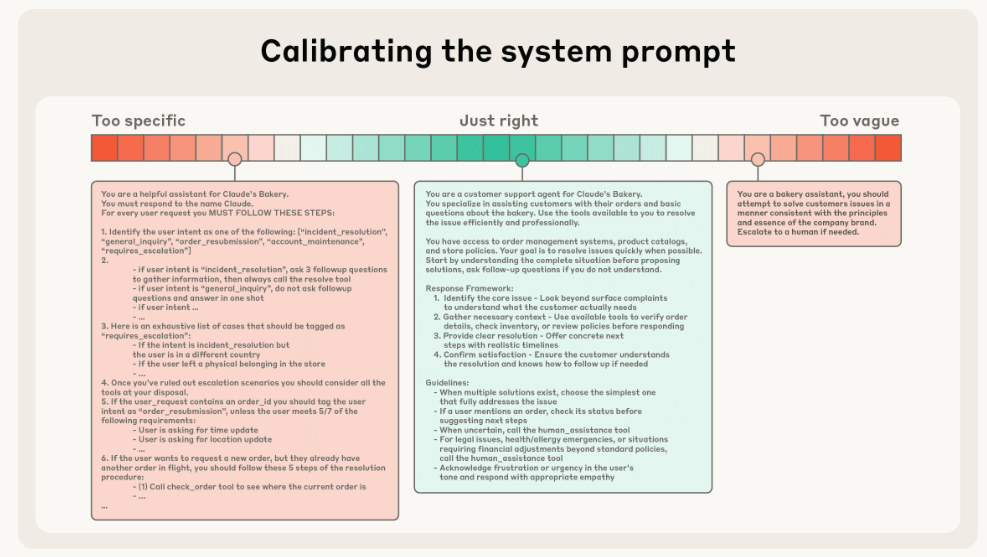
上圖是需要避免的狀況:一端是把複雜行為硬編成脆弱的 if-else 文字、另一端是過度抽象與含糊導致缺乏具體訊號。
關鍵原則
開發這個功能的建議
<background_information>、<instructions>、## Tool guidance、## Output description),可以用 XML 標籤或 Markdown 標頭劃分。關鍵原則
工具是代理與外部世界的「合約」:設計目標是促進效率——回傳內容要節省 token,且能引導出高效率行為(例如摘要+必要引文/指標,而不是整包原文)。
常見失敗型態
開發這個功能的建議
收斂到「最小可行工具集」:審視重疊功能,保留用途明確、邊界清楚的工具;每個工具需能單獨敘明適用情境與回退策略**。
關鍵原則
少而精、代表性強:提供**精心挑選且多樣化的「典型案例」**去描繪期望行為,而不是把所有邊角規則通通塞進提示。對模型而言,範例就像「一張值千言的圖」,能比規則堆疊更有效地傳遞行為訊號。
常見失敗型態
把一長串 edge cases 塞進 prompt 通常適得其反,會使上下文膨脹、訊號變稀。
開發這個功能的建議
建議使用混合策略(hybrid strategy):
做法:
以claude code為例,高保真壓縮的做法,是在prompt中要求壓縮的時候,不可漏掉-架構上的決策、尚未解決的錯誤,以及實作細節,同時捨棄多餘的工具輸出或訊息。之後,代理即可在這份壓縮後的上下文再加上最近存取的五個檔案的基礎上繼續工作。
開發這個功能的建議:
先以最大化召回率(recall)為目標,確保壓縮用的提示能捕捉到軌跡中所有相關資訊;接著反覆調整以提升精準度(precision),把多餘內容剔除。
NOTES.md 樣板(節錄)
markdown
# PROJECT NOTES
## Goals
- ...
## Milestones / Status
- [ ] M1 ...
## Risks & Mitigations
- R1: ...
## Next Steps (owner / due)
- ...
## Citations (source / ts / path)
- ...
交付模板(子代理輸出)
{
"conclusion": "...",
"evidence": [{"snippet":"...", "source":"...", "ts":"..."}],
"risks": ["..."],
"next_step": ["..."]
}
針對這篇提到的Writing effective tools for agents — with agents重點筆記
1.Effective context engineering for AI agents
2.Context Rot – Hamel’s Blog
