上一篇文章中,提到 Firehose 的 recordID 會和目標寫入的資料是一比一的關係,所以必須在 Firehose 前面架設一個 Lambda 來去分割我們的 record。Firehose 可以將串流資料送到多種儲存後端,包含 S3、Redshift、OpenSearch 等,
而今天,我們選用的儲存後端是 S3 Table,它是 AWS 在 2024 年底推出的新服務。它和 S3 有什麼不同?為什麼要選用 S3 Table 作為 Data LakeHouse?今天的文章將會聚焦在 S3 Table 的核心概念與設計考量,幫助大家理解為什麼它適合作為我們的 Data Lakehouse 解決方案。
S3 Table 本身也是物件儲存(object storage)的一種,只是它內建 Apache Iceberg 的設計,讓儲存表格式資料這件事情變得輕易許多。
在 S3 Table 還沒問世之前,我們也可以在一般的 S3 bucket 套上 Iceberg,但要做到這一點,我們除了要在 Glue 上設定 catalog以外,在做資料的新增、查詢、刪減時,也必須透過其他查詢引擎如 Athena 等。最後,我們也需要直接在 S3 General bucket 上面管理 Iceberg 的 metadata 與 Parquet 檔案。
在 S3 Table 出現前,若要在 AWS 上建構一個基於 Iceberg 的資料湖,我們需要自行處理以下挑戰:
而 S3 Table 在這些地方做了大量自動化:背景會定期重寫與整理 parquet 檔案,維持 Iceberg metadata tree 輕量化,並自動整合 Glue Catalog。這讓使用者能專注於資料應用本身,而非底層維運。
並且,我們也能透過常用的查詢引擎來查詢 S3 Table裡的表格式資料。可以說,S3 Table 在使用上與 Iceberg 無異,但它幫我們簡化了很多設定與管理。
綜合以上特點,選擇 S3 Table 的原因可以從三個面向來看:
換句話說,S3 Table 讓 Data Lakehouse 可以更容易落地,並讓之後的維運可以更加的容易,又能兼顧資料的查詢效能。
在傳統的 Data Lakehouse 架構中,我們需要透過 AWS Glue Data Catalog 來管理 Iceberg 表格的 metadata。S3 Table 也可以透過 Data Catalog 來管理資料,並透過 Athena 等查詢引擎進行資料查詢。
若要做到這點,在 S3 Table Bucket 的 Console 中,我們會需要 Enable Integration with AWS analytics services,才能讓 S3 Table 與其他查詢引擎服務進行整合。而它背後的設計則是將 S3 Table 與 AWS Glue Data Catalog(資料目錄)整合,並從 Lake Formation 控制台或使用服務 API 將該目錄註冊為 Lake Formation 資料位置。
當你在 Data Catalog 中管理資料,並將資料位置註冊到 Lake Formation 時,你就可以使用 Lake Formation 來控制對資料集的存取權限。
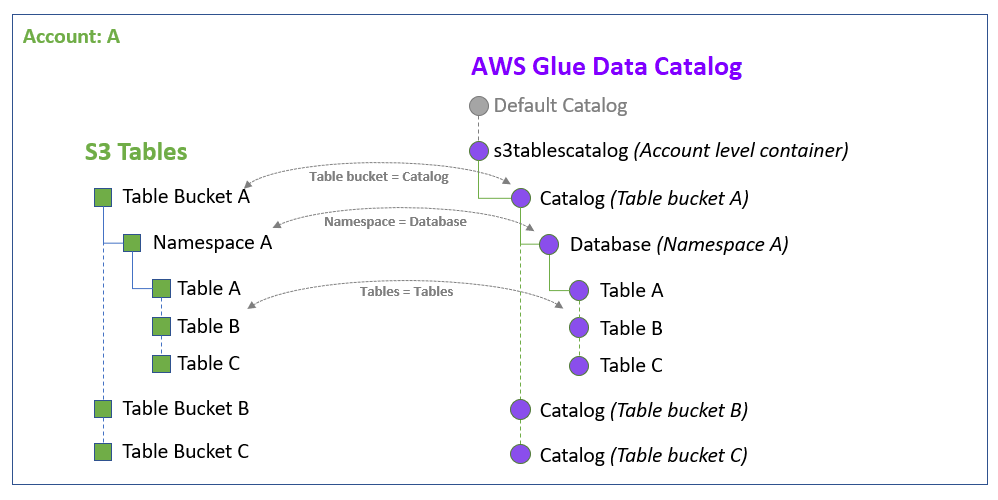
從上面的對照表可以看到,當我們將 S3 Table 做 Integration 後,它就會自動與 Glue Data Catalog 做整合。當創建一個 S3 Table 後,系統會自動創建一個 s3tablecatalog,這個 catalog 會建立在 Account level,所以一個帳戶只會有一個 s3tablecatalog。
接著我們創建的 table bucket 則會在這個 s3tablecatalog 下面再創建一個 catalog,這個 catalog 才是我們平常所熟知的 catalog,在這個 catalog 之下,可以創建多個 Database,而在 S3 Table 中,它則是被命名為 Namespace。
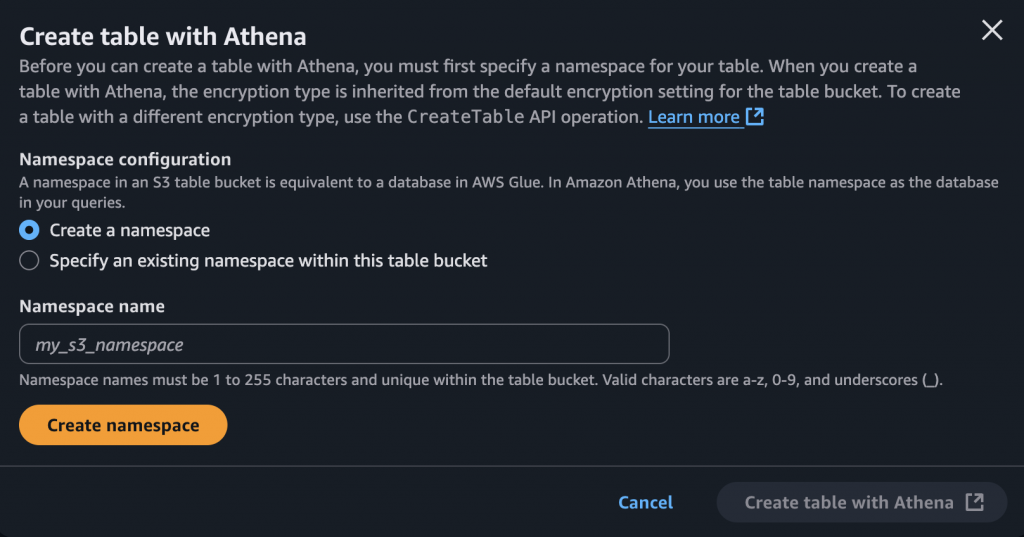
S3 Table 中的 "table" 可以透過 Athena 創建。在創建時,便會要你指定 table 所屬的 namespace。
今天,我們了解了 S3 Table 在做大量資料儲存時的優勢。在選定資料的儲存後端之後,我們便可以完善前幾天設計的 data pipeline 架構。
AWS Documentation - Creating an Amazon S3 Tables catalog in the AWS Glue Data Catalog
AWS Dcumentation - Working with Amazon S3 Tables and table buckets


 iThome鐵人賽
iThome鐵人賽