昨天我們談到 品質監控與幻覺偵測 , 就算模型輸出的答案正確,還要確保它「可靠、可信」。
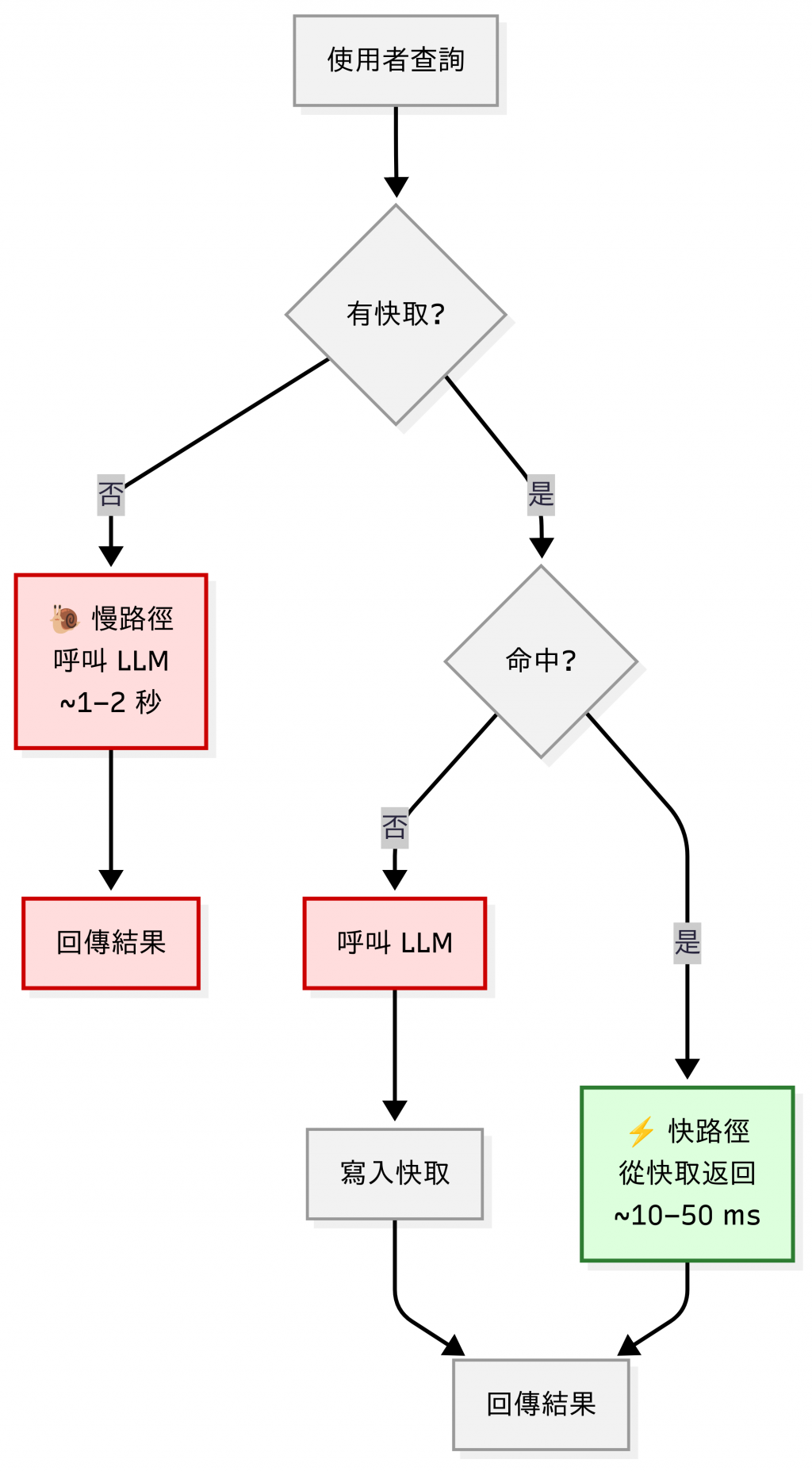
但即使模型回答正確,還有一個現實問題:
👉 為什麼我的 LLM 應用這麼慢、這麼貴?
品質解決的是「答案正不正確」,
而今天要談的 快取(Cache),解決的是「答案快不快、貴不貴」。
對 DevOps 工程師來說,Cache 一點也不陌生:我們在系統設計裡早就習慣用 CDN、Redis、Memcached 來減少重複查詢。 放到 LLM 世界,其實邏輯一樣;不用每次都去「重算」,就能省下延遲和成本。
在企業場景中,以下情境非常常見:
如果每次都讓 LLM 從頭生成,不僅延遲高,成本也會飆升。
快取就是解方:重複的問題直接命中快取,避免浪費。
| 情境 | 月請求數 | 單次成本 | 基準成本(無快取) | 快取命中(次 → 省下) | Token Cache 省下 | 需呼叫 LLM(次 → 費用) | 總成本/月 | 節省比例 |
|---|---|---|---|---|---|---|---|---|
| A:FAQ(命中 60%) | 100,000 | $0.0025 | $250 | 60,000 → $150 | — | 40,000 → $100 | $100 | 60% |
| B:一般 QA(命中 30%) | 100,000 | $0.0025 | $250 | 30,000 → $75 | — | 70,000 → $175 | $175 | 30% |
| C:命中 30% + Token Cache 10% | 100,000 | $0.0025 | $250 | 30,000 → $75 | $25(約 10%) | 70,000 → $150($175 − $25) | $150 | 40% |
註:上面區間來自 完整回答快取 的節省 + Token cache(輸入 token 的 50% 折扣,只在可重用時生效)。實際省幅會因流量分佈、命中率、輸入長度與重用率而異;建議用 A/B(cache on/off)在自己的實際數據上驗證。
| 策略 | 適用場景 | 成本節省效果 | 實作難度 | 維運複雜度 | 技術選擇 |
|---|---|---|---|---|---|
| Prompt → 回答 Cache | FAQ、重複查詢多 | 高重複度場景,命中率可觀;例子:Azure 提供語意快取策略以降延遲/負載 [*1] | ★ | ★ | In-memory(Python dict、functools LRU Cache)、LangChain InMemory/SQLite |
| 策略 | 適用場景 | 成本節省效果 | 實作難度 | 維運複雜度 | 技術選擇 |
|---|---|---|---|---|---|
| Embedding 相似查詢 Cache | 自然語言問答、客服 | 查詢改寫約占 ~37%,快取可捕捉這部分流量 [*2] | ★★★ | ★★☆ | 向量資料庫 (FAISS、Weaviate、Pinecone)、Redis Vector Search |
| Token-level Cache | 多輪對話、長上下文 | Cached input 有 50% 折扣(需 ≥ 1024 tokens),並能顯著降低延遲[*3] | ★★☆(API 支援時) / ★★★★(自建) | ★★★ | 雲端 API(OpenAI Token Caching)、自建推理服務支援 KV cache |
| Partial Prompt Cache | 長文檢索、帶上下文 Q&A | 效果依場景而定(避免重複計算部分 Token) | ★★★★ | ★★★ | 自訂分片 (sharding) 邏輯策略 + Redis、** middlware 快取層** |
| 策略 | 適用場景 | 成本節省效果 | 實作難度 | 維運複雜度 | 技術選擇 |
|---|---|---|---|---|---|
| RAG Intermediate Cache | 文件檢索、知識庫 Q&A | TTFT 最多快 4×、**吞吐量約 2.1× [*4] | ★★★ | ★★★ | Redis / Memcached(檢索結果快取)、LangChain Cache |
| Multi-layer Cache (L1/L2) | 大流量、跨服務架構 | L1 超低延遲;L2 叢集/HA/水平擴展 [*5] | ★★★★ | ★★★★ | L1: In-memory(超快) + L2: Redis/Memcached/VectorDB |
[*4] RAGCache(arXiv 2024):RAG 多層知識快取,實驗顯示 TTFT(Time to First Token,首個 Token 輸出延遲)最多快 4×,吞吐量提升約 2.1×。
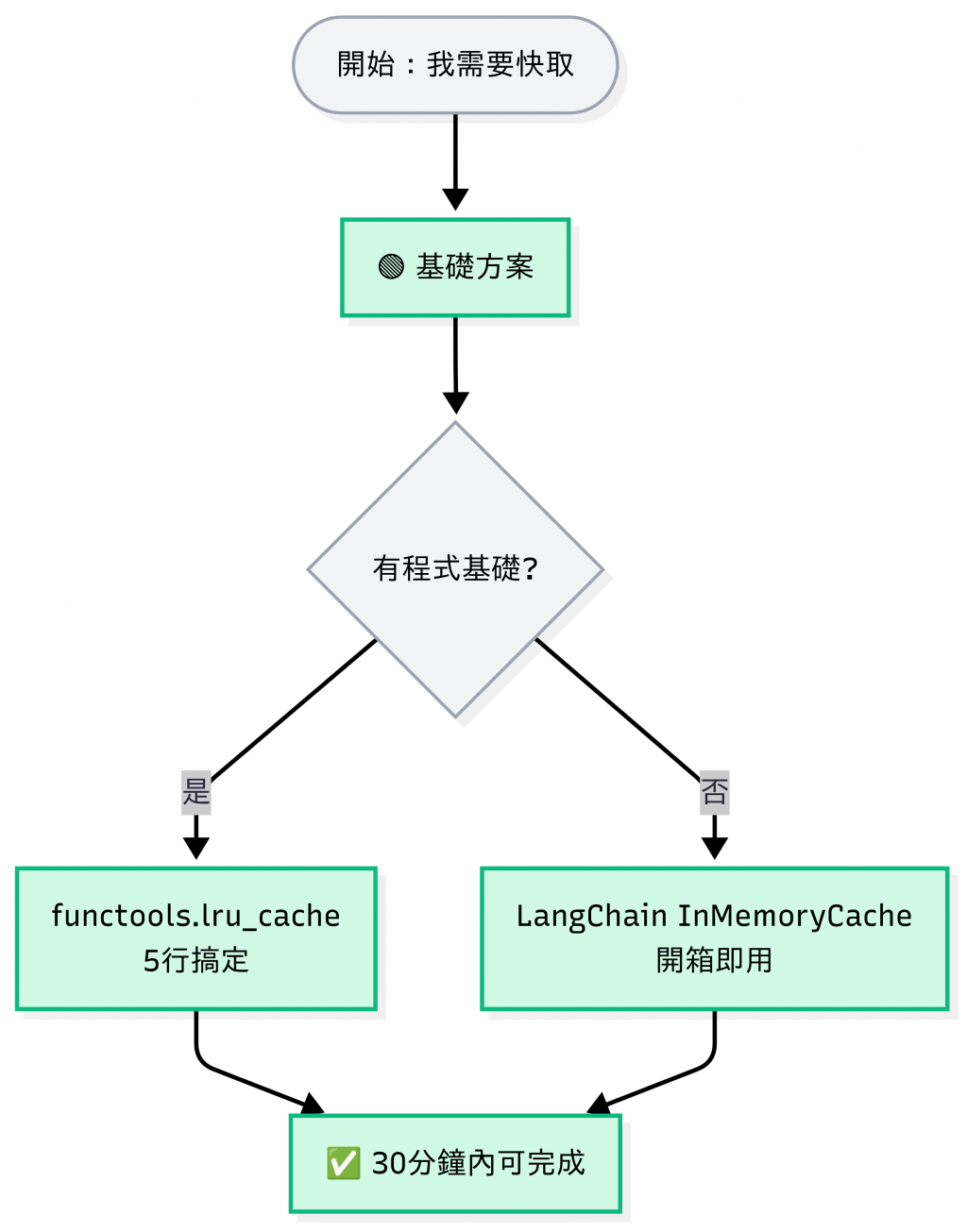
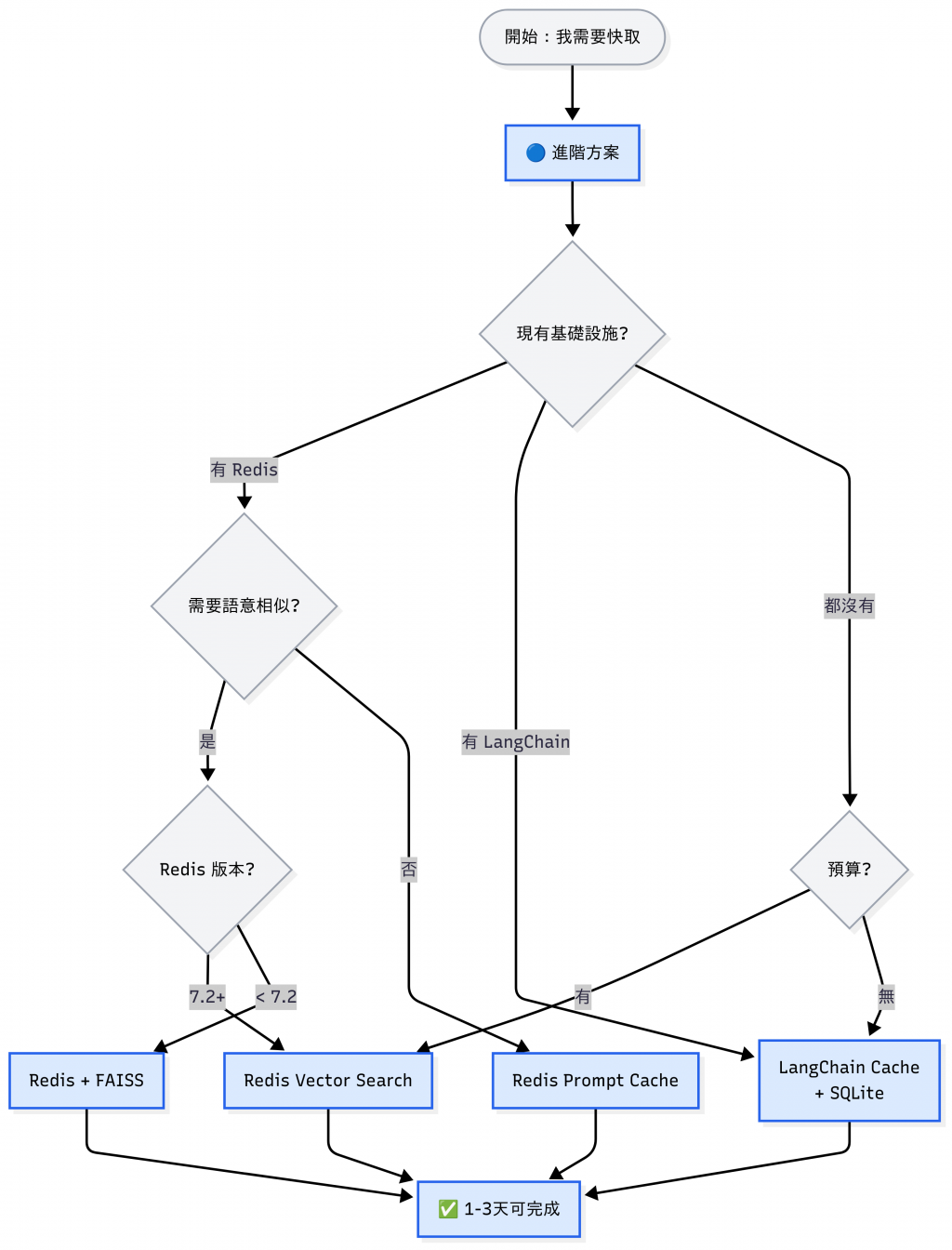
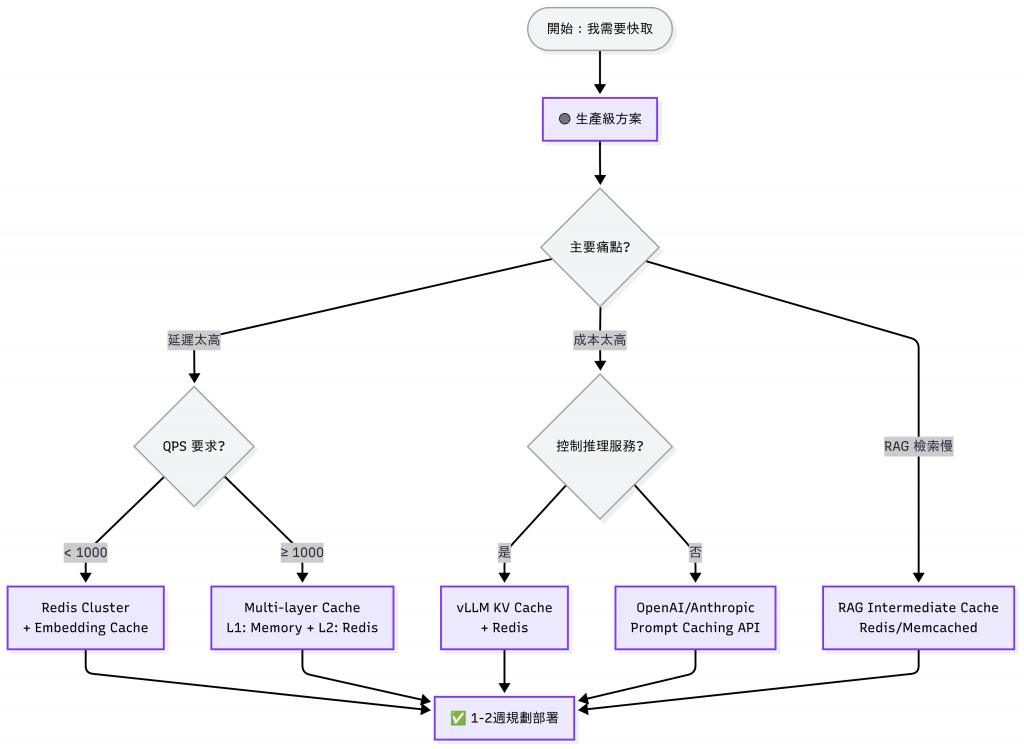
先看專案階段,再看有什麼資源,最後解決痛點,三分鐘快速決定版:
| 情境 | 速解法 | 預期時間 |
|---|---|---|
| 完全新手,只想試試看 | functools.lru_cache | 30 分鐘 |
| 已經用 LangChain | LangChain Cache | 1 小時 |
| 公司有 Redis | Redis Prompt/Vector Cache | 1-2 天 |
| 要上線了,需要穩定 | 看主要痛點決定 | 1-2 週 |
| QPS > 1000 | Multi-layer Cache | 2-4 週 |
以上資料皆來自公開研究與官方文件,為「案例參考值」。
實際效果會依 實際環境是否接受雲端服務、工作負載類型、查詢分布、模型版本與系統設計 而有所差異。建議在導入前先以 A/B 測試或線上實驗 驗證快取策略的效益。
今天的程式碼會放在 GitHub Repo,有興趣的讀者歡迎自行 Fork 研究。
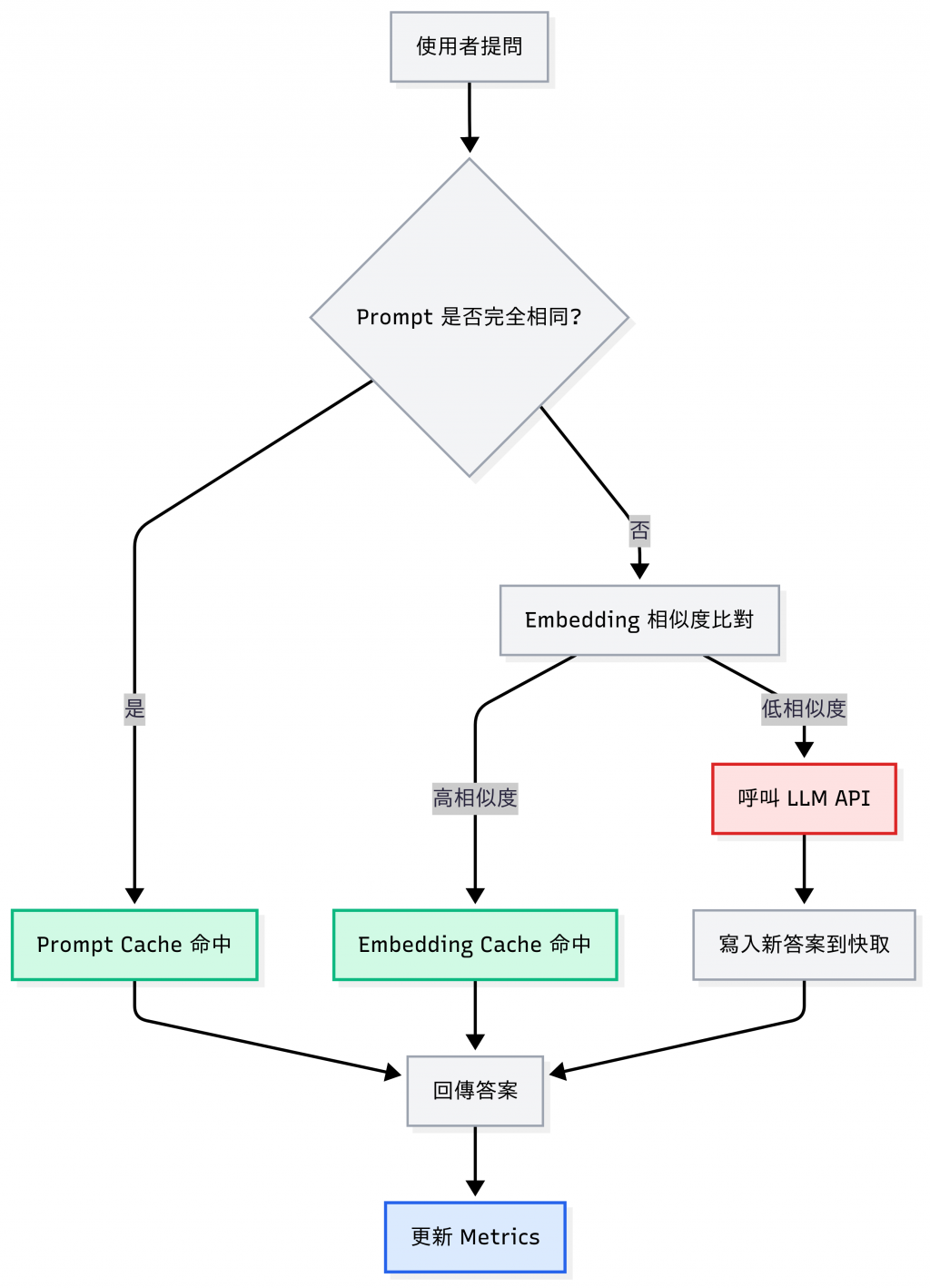
最簡單的做法是Prompt Cache: 完全相同的輸入,就直接回傳快取結果。
這種方式雖然容易上手,但在真實場景裡常常「命中率偏低」。
為什麼?因為用戶很少會輸入一模一樣的句子:
對人類來說是同一件事,但對字串比對來說是「完全不同」,Prompt Cache 就 miss 掉了。
於是我們需要 進階版的快取: 在存取答案之前,先把問題轉成 向量 (Embedding),再用語意相似度判斷是否命中。 這樣即使句子不同,只要語意夠接近,就能重用答案。
知識庫查詢 / RAG 系統
行銷 / 內容生成
對比只有 Prompt Cache 的情境,只需要加一層「embedding 相似度檢查」,技術負擔不高,但卻可以追加處理語意改寫(paraphrase)的功能,更能符合多數企業需要。
所以今天我們會用 FastAPI + Redis + OpenAI Embeddings 兜岀一個範例,先處理重複查詢、再處理相似的語意。因為篇幅關係,完整可執行專案一樣會放在 GitHub。
day21_cache/
.
├── README.md # 專案說明文件
├── api/ # API 層(FastAPI / RESTful 入口)
├── core/ # 核心設定與共用邏輯
├── data/ # 資料相關
├── docker-compose.yml # Docker Compose 定義(Redis, API 等服務)
├── environment.yaml # Conda 環境設定檔
├── models/ # 資料模型
├── pytest.ini # pytest 設定
├── scripts/ # 工具腳本
├── services/ # 服務層(封裝商業邏輯)
└── tests/ # 測試
執行結果:
# 第一次:呼叫 LLM,寫入 Redis
❯ curl -X POST localhost:8000/ask -H "content-type: application/json" -d '{"question":"跟我解釋一下快取?"}'
{"question":"跟我解釋一下快取?","answer":"快取(Cache)是一種用來提高計算機系統性能的技術,主要透過暫時儲存經常使用或最近使用的資料,以便快速訪問。它的工作原理可以理解為一種 \"中間\" 儲存區,當系統需要資料時,首先會查詢快取,如果在快取中找到了所需的資料(這叫做「快取命中」),系統就可以快速提供該資料,而無需從較慢的儲存介質(如硬碟、SSD或網絡)重新加載。\n\n快取通常用在多個層面上,包括:\n\n1. **CPU快取**:處理器內部有多級快取(如L1、L2、L3快取),用來存儲指令和數據,以減少從主記憶體讀取資料的時間。\n\n2. **磁碟快取**:在硬碟或SSD上,快取用於存儲最近訪問的數據,讓常用的資料能更快地被讀取。\n\n3. **瀏覽器快取**:網頁瀏覽器會將訪問過的網站內容(如圖片、CSS、JavaScript)暫存在本地,以便在下次訪問時快速加載,提升頁面顯示速度。\n\n4. **應用程式快取**:許多應用程式會將計算結果或數據暫時存儲,避免重複計算或重複請求資料,提升效能。\n\n快取的好處是明顯的,能顯著提高性能和響應速度,但尚需注意快取的容量和更新策略,以避免過期或不一致的資料影響系統的正確性和穩定性。","source":"llm","prompt_tokens":16,"completion_tokens":409,"cost_usd":0.002502,"cache_hit":false}%
# 第二次:直接從快取命中 (source=llm, cache_hit=true),省下成本
❯ curl -X POST localhost:8000/ask -H "content-type: application/json" -d '{"question":"什麼是快取?"}'
{"question":"什麼是快取?","answer":"快取(Cache)是一種用來提高資料存取速度的技術,通常用在電腦系統和網路中。它的基本原理是將頻繁使用的資料或運算結果暫時存放在一個快速存取的區域,以減少存取較慢的儲存裝置(例如硬碟或網路伺服器)的次數。\n\n快取可以分為幾種類型,包括:\n\n1. **CPU快取**:處理器內部的記憶體,用來儲存最近使用的資料和指令,以加速計算過程。\n\n2. **磁碟快取**:運行在操作系統層級的快取,用來提高從硬碟讀取資料的速度。\n\n3. **網頁快取**:在瀏覽器或代理伺服器中儲存常用的網頁資源,以加快網頁載入速度。\n\n快取的設計通常遵循「局部性原則」,即最近使用的資料或相鄰的資料有較高的機會在將來再次被使用。快取的有效性通常依賴於儲存的資料構成和使用模式。合理的快取策略可以顯著提高系統的性能和響應速度。","source":"llm","prompt_tokens":13,"completion_tokens":292,"cost_usd":0.001791,"cache_hit":true}%
執行結果:
# 雖然字串不同,但透過 Embedding 相似度比對 (閾值 0.85),依然命中快取(source=embed_cache)
❯ curl -X POST localhost:8000/ask -H "content-type: application/json" -d '{"question":"快取是什麼,解釋一下?"}'
{"question":"快取是什麼,解釋一下?","answer":"快取(Cache)是一種用來提高資料存取速度的技術,通常用在電腦系統和網路中。它的基本原理是將頻繁使用的資料或運算結果暫時存放在一個快速存取的區域,以減少存取較慢的儲存裝置(例如硬碟或網路伺服器)的次數。\n\n快取可以分為幾種類型,包括:\n\n1. **CPU快取**:處理器內部的記憶體,用來儲存最近使用的資料和指令,以加速計算過程。\n\n2. **磁碟快取**:運行在操作系統層級的快取,用來提高從硬碟讀取資料的速度。\n\n3. **網頁快取**:在瀏覽器或代理伺服器中儲存常用的網頁資源,以加快網頁載入速度。\n\n快取的設計通常遵循「局部性原則」,即最近使用的資料或相鄰的資料有較高的機會在將來再次被使用。快取的有效性通常依賴於儲存的資料構成和使用模式。合理的快取策略可以顯著提高系統的性能和響應速度。","source":"embed_cache","prompt_tokens":13,"completion_tokens":292,"cost_usd":0.001791,"cache_hit":true}
執行結果:
# 因為沒有命中,LLM 真實回答,並將結果寫入 Prompt Cache + Embedding Cache
❯ curl -X POST localhost:8000/ask -H "content-type: application/json" -d '{"question":"什麼是資料庫索引?"}'
{"question":"什麼是資料庫索引?","answer":"資料庫索引是一種數據結構,旨在提高資料庫查詢操作的速度。它類似於書籍的目錄,可以幫助迅速地找到特定資訊,而無需逐頁翻閱整本書。在資料庫中,索引允許系統更快地定位和檢索行(records),從而加快查詢的執行效率。\n\n### 主要功能:\n1. **提高查詢性能**:索引可以顯著減少查詢所需的時間,特別是在處理大型資料集時。\n2. **支持排序與過濾**:索引使得按特定欄位排序和過濾資料變得更高效。\n3. **唯一性約束**:某些類型的索引(如唯一索引)可以用來強制行的唯一性,避免重複數據。\n\n### 常見的索引類型:\n1. **B樹索引**:最常用的一種索引結構,適合範圍查詢。\n2. **哈希索引**:適合精確查詢,但不支持範圍查詢。\n3. **全文索引**:專門用於加速文字內容的檢索,支持自然語言查詢。\n4. **空間索引**:用來處理地理信息系統(GIS)中的空間數據。\n\n### 注意事項:\n- **維護成本**:雖然索引可以加速查詢,但也會增加資料寫入和更新的開銷,因為每次資料的變動都需要更新相關的索引。\n- **空間佔用**:索引會佔用額外的存儲空間。\n\n總之,資料庫索引是一個重要的性能優化工具,但使用時需謹慎,以平衡查詢速度與寫入性能之間的關係。","source":"llm","prompt_tokens":15,"completion_tokens":429,"cost_usd":0.002619,"cache_hit":false}%
可以看到
/ask次數、cache hit/miss 狀況,幫助我們量化快取效果。
執行結果:
# Prompt 命中率
❯ curl -s localhost:8000/metrics/json | jq '. as $m | ($m.cache_hits.prompt) / (($m.cache_hits.prompt) + ($m.cache_miss.prompt))'
0.2857142857142857
# Embed 命中率
❯ curl -s localhost:8000/metrics/json | jq '. as $m | ($m.cache_hits.embed) / (($m.cache_hits.embed) + ($m.cache_miss.embed))'
1
# 只看 cache bucket(命中/未中)
❯ curl -s localhost:8000/metrics | \
grep -E 'day21_cache_cache_(hits|miss)_total'
# HELP day21_cache_requests_total Total API requests
# TYPE day21_cache_requests_total counter
day21_cache_requests_total{route="/ask"} 7.0
# HELP day21_cache_cache_hits_total Cache hits by kind
# TYPE day21_cache_cache_hits_total counter
day21_cache_cache_hits_total{kind="prompt"} 2.0
day21_cache_cache_hits_total{kind="embed"} 1.0
# HELP day21_cache_cache_miss_total Cache misses by kind
# TYPE day21_cache_cache_miss_total counter
day21_cache_cache_miss_total{kind="prompt"} 5.0
# HELP day21_cache_cost_usd_total Accumulative cost in USD
# TYPE day21_cache_cost_usd_total counter
day21_cache_cost_usd_total 0.009413999999999999
# HELP day21_cache_cache_hits_total Cache hits by kind
# TYPE day21_cache_cache_hits_total counter
day21_cache_cache_hits_total{kind="prompt"} 2.0
day21_cache_cache_hits_total{kind="embed"} 1.0
# HELP day21_cache_cache_miss_total Cache misses by kind
# TYPE day21_cache_cache_miss_total counter
day21_cache_cache_miss_total{kind="prompt"} 5.0
# 一行顯示「三個指標」
❯ curl -s localhost:8000/metrics | awk '
/day21_cache_requests_total{route="\/ask"}/ {req=$2}
/day21_cache_cache_hits_total{kind="prompt"}/ {ph=$2}
/day21_cache_cache_miss_total{kind="prompt"}/ {pm=$2}
/day21_cache_cost_usd_total/ {cost=$2}
END {
hitRate = (ph+pm)>0 ? ph/(ph+pm) : 0
printf "requests=%d | prompt_hit=%d miss=%d (hit_rate=%.1f%%) | cost_usd=%.6f\n", req, ph, pm, hitRate*100, cost
}'
# 本輪共 7 次請求,Prompt 快取命中 2 次、未命中 5(命中率 **28.6%**)次,累計成本 USD$0.009414。
requests=7 | prompt_hit=2 miss=5 (hit_rate=28.6%) | cost_usd=0.009414
執行結果:
========================================================= test session starts =========================================================
platform darwin -- Python 3.11.13, pytest-8.4.2, pluggy-1.6.0 -- /opt/homebrew/Caskroom/miniforge/base/envs/day21_cache/bin/python
cachedir: .pytest_cache
rootdir: /Users/hazel/Documents/github/2025-ironman-llmops-demo/day21_cache
configfile: pytest.ini
plugins: asyncio-1.2.0, anyio-4.10.0
asyncio: mode=Mode.AUTO, debug=False, asyncio_default_fixture_loop_scope=session, asyncio_default_test_loop_scope=session
collected 6 items
tests/test_api.py::test_api_prompt_cache_hit PASSED [ 16%]
tests/test_api.py::test_api_embed_cache_hit PASSED [ 33%]
tests/test_embed_cache_redis.py::test_embed_cache_redis_upsert_and_search PASSED [ 50%]
tests/test_health.py::test_health PASSED [ 66%]
tests/test_metrics.py::test_metrics_and_json_updates PASSED [ 83%]
tests/test_prompt_cache.py::test_prompt_cache_basic PASSED [100%]
========================================================== 6 passed in 5.40s ==========================================================
這樣,重複的問題會直接從 Redis 命中,不必再付費請求 LLM。
一開始我把 EMBED_SIM_THRESHOLD 設成 0.92,結果實測發現:
👉 解法:
把閾值調到 0.85,就能順利命中相似問題,快取真正發揮效用。
在企業場景裡,閾值 最好用歷史 query 做 A/B 測試來決定。
如果把快取視為一種平台能力,我們就能從 DevOps / SRE 的角度來看待它。
不只是在意「命不命中」,而是把快取納入系統 SLI/SLO,確保它真的可靠。
| 類別 | SLI(量測方式) | 典型 SLO(範例) | 儀表板面板建議 (以 Grafana 為例 | 告警(表中僅為建議值) | 說明 |
|---|---|---|---|---|---|
| 可用性 | cache_get 成功率 = 成功/全部 |
99.9% / 30天 | Time series:cache_get_success_rate;Table:錯誤碼分佈 |
cache_get_success_rate < 0.999 for 10m |
Redis 連線失敗、逾時與應用錯誤一起看 |
| 成本 | avg_cost_per_request、cost_usd_total |
輸出 ≤ 0.4× 未開快取基準 | SingleStat:avg_cost_per_request;Time series:cost_usd_total |
(依專案基準線設定) | 與 A/B 對照關閉快取(cache_off)成本 |
| 命中 | cache_hit_rate(拆 hit_rate_prompt、hit_rate_embed) |
FAQ ≥60%;一般 QA ≥30–50% | SingleStat:hit_rate_prompt,hit_rate_embed;Bar gauge:各 route 命中率;Table:Top-N keys(size/命中/更新) |
一般 QA:hit_rate_prompt < 0.3 for 15m;FAQ:< 0.6 for 15m |
命中率低先檢查鍵標準化、閾值、TTL、租戶隔離 |
| 延遲 | p50/p95_latency_ms(分流 cached / uncached) |
cached ≤ 80ms;uncached ≤ 1.2s |
Time series:p95_latency_ms{cached="true"} vs {cached="false"} |
p95_latency_ms{cached="false"} > 1200 for 10m |
分開量測才看得見快取效益 |
| 新鮮度 | stale_served_ratio;stampede_prevented_total |
stale_served_ratio ≤ 0.5% |
Time series:stale_served_ratio;Counter:stampede_prevented_total |
stale_served_ratio > 0.005 for 30m |
帶 TTL / (知識庫 / 自建模型 / 業務邏輯)版本鍵,量測過期資料被取用比率 |
| 資源/Redis 健康 | redis_connected_clients、instantaneous_ops_per_sec、keyspace_hits/misses、evicted_keys、used_memory |
無硬性 SLO(維持在容量與延遲目標內) | Table/Bar gauge:evicted_keys、命中/未中;Time series:used_memory、連線數、Ops |
Evictions 增速異常;used_memory 接近上限;連線/逾時異常 |
設 maxmemory+allkeys-lfu/volatile-ttl 並監控淘汰行為 |
若首次上線,先用寬鬆告警(觀察型)再逐步收緊閾值
快取不只是「程式最佳化」,而是跟其他系統元件一樣,需要有 量測、告警門檻與治理。
雖然快取能有效降低延遲與成本,但在正式採用時也要注意以下問題:
Cache 失效
相似度閾值
隱私與安全
快取污染 (Cache Pollution)
多租戶問題 (Multi-tenant Caching)
版本不一致 (Version Drift)
今天我們介紹了 三大類快取策略以及對應工具,並透過 FastAPI + Redis 示範了最小可行的實作。
透過這些方法,我們能 同時降低延遲與成本,讓 LLM 系統更實用。
👉 可以把這樣的脈絡理解成:
換句話說,Cache 解決短期效率,Registry 解決長期治理。
這樣系統才不只是「能跑」,而是能「跑得快、跑得久」。
明天(Day22)我們會繼續這條路,談到發布管理:解決 LLM 系統回應的追溯、治理以及審計問題。

