昨天我們談到 延遲、Token 與成本 的監控,確保系統「跑得快、花得省」。
但如果模型輸出的答案是錯的呢?
👉 在 LLM 應用中,Hallucination(幻覺) 指的是:
模型生成了聽起來合理,但實際上 不存在或不正確的資訊。
例如:
在企業應用裡,這可能導致 誤導客戶、商業風險、甚至法律問題,所以我們需要「品質監控」機制。
在產業界,幻覺問題已經發生過不少次,以下舉幾個代表性案例:
| 案例 | 描述 | 對應文章重點 | 來源 |
|---|---|---|---|
| 韓國:生成型 AI 假新聞/影像傳播 | 在自然災害發生後,SNS 上流傳大量由生成型 AI 合成的「假地震現場影片」,導致群眾誤解。政府與媒體後續出面澄清,呼籲民眾注意資訊來源。 | Error Rate 與 Faithfulness / Coverage:提醒我們,即使影像看起來合理,若缺乏檢索驗證,依然可能是幻覺。 | 경향신문(存取日期:2025-10-04) |
| 日本:教育與研究中的虛構引用 | 朝日新聞評論指出,在日本教育/學術場景中,學生與研究人員使用生成 AI 時,常遇到「虛構的數據與不存在的文獻」。例如:教學資料出現不存在的統計數字、或引用了不存在的研究論文。 | Rule-based Check 與 LLM-as-a-judge:引用來源必須被檢查,否則容易因幻覺導致錯誤知識傳播。 | 朝日新聞(存取日期:2025-10-04) |
| Mount Sinai 的醫療錯誤資訊研究 | 有研究證明,若在 prompt 裡加入虛構的醫療詞彙/症狀/疾病,聊天機器人會被誤導,不僅接受錯誤資訊,還會「延伸」或「解釋」這些虛構內容,讓回答看起來很有權威性但完全是錯的。 | 凸顯 “Retrieval-based” + “Rule-based” 檢測的重要性,以及醫療領域中對幻覺率的嚴苛要求。 | Mount Sinai Health System;MedCity News(存取日期:2025-10-04) |
今天的程式碼會放在 GitHub Repo,有興趣的讀者歡迎自行 Fork 研究。
如果你在做 RAG(Retrieval-Augmented Generation):
範例流程:
以下是一個用檢索結果判定是否是幻覺的 Demo 片段:
# -*- coding: utf-8 -*-
# retrieval_demo.py
"""
Retrieval-based Check Demo
用 sentence-transformers 計算回答與檢索片段的語義相似度,低於閾值即視為可能幻覺
"""
from typing import List, Optional
from sentence_transformers import SentenceTransformer, util
import torch
class RetrievalChecker:
def __init__(self, model_name: str = "all-MiniLM-L6-v2"):
self.model = SentenceTransformer(model_name)
def faithfulness_score(self, docs: List[str], answer: str) -> float:
doc_embeds = self.model.encode(docs, convert_to_tensor=True)
ans_embed = self.model.encode([answer], convert_to_tensor=True)
cos_sim = util.cos_sim(ans_embed, doc_embeds) # shape: [1, N]
return float(cos_sim.max())
# 建議:多語模型(也可改成 bge-m3、jina-embeddings 等)
def retrieval_check(
answer: str,
docs: List[str],
threshold: float = 0.6,
model_name: str = "all-MiniLM-L6-v2",
) -> Optional[float]:
"""
回傳分數(>= threshold)代表通過;否則回傳 None。
"""
checker = RetrievalChecker(model_name)
score = checker.faithfulness_score(docs, answer)
return score if score >= threshold else None
if __name__ == "__main__":
torch.set_num_threads(1) # 避免執行緒過多
# 檢索到的文件片段(RAG context)
docs = [
"公司 VPN 設定文件:步驟 1 安裝軟體,步驟 2 設定帳號,步驟 3 連線。",
]
# ✅ 合理(非幻覺)對照
grounded_answer = (
"依文件步驟:先安裝 VPN 軟體,以公司帳號登入後再嘗試連線。"
"若需要詳細設定,請參考 IT 提供的安裝指南頁面。"
)
# ❌ 幻覺範例(編造路徑/IP/指令,文件未提及)
hallucinated_answer = (
"請編輯 /etc/vpn/config,把伺服器設為 10.0.0.5,"
"存檔後執行 vpnctl --force 重啟即可。"
)
# 門檻:可依場景調整
# FAQ/一般客服:0.4–0.6;內部知識查詢:0.6–0.7;醫療/金融:>=0.8
threshold = 0.6
for label, answer in [
("範例 A(合理對照)", grounded_answer),
("範例 B(幻覺範例)", hallucinated_answer),
]:
score = retrieval_check(answer, docs, threshold=threshold)
if score is None:
print(
f"{label} → Retrieval-based:相似度低於門檻(thr={threshold:.2f})→ ⚠️ 可能幻覺\n"
f"回答:{answer}\n"
)
else:
print(
f"{label} → Retrieval-based:相似度 {score:.2f}(thr={threshold:.2f})✅\n"
f"回答:{answer}\n"
)
執行結果:
❯ python retrieval_demo.py
範例 A(合理對照) → Retrieval-based:相似度 0.90(thr=0.60)✅
回答:依文件步驟:先安裝 VPN 軟體,以公司帳號登入後再嘗試連線。若需要詳細設定,請參考 IT 提供的安裝指南頁面。
範例 B(幻覺範例) → Retrieval-based:相似度低於門檻(thr=0.60)→ ⚠️ 可能幻覺
回答:請編輯 /etc/vpn/config,把伺服器設為 10.0.0.5,存檔後執行 vpnctl --force 重啟即可。
這裡的閾值(例如 0.6)可以依應用情境與業務需求調整,比方說:
實務上建議「拆句 + 覆蓋率(coverage)」,並改用多語模型(如 paraphrase-multilingual-MiniLM-L12-v2)以提升中文判斷穩定度。
在真實系統中,可以把這個檢查結果輸出到 Prometheus 指標,就可以觀察回答的品質:
llm_quality_faithfulness_score
llm_quality_hallucination_total
| 模型 | 特色 | 速度 | 中文表現 | 跨語泛化 | 註解 |
|---|---|---|---|---|---|
| paraphrase-multilingual-MiniLM-L12-v2 | 體積小、推論快、支援多語 | ★★★★☆ | ★★★☆ | ★★★★☆ | 教學/原型首選 |
| LaBSE | 跨語檢索品質佳 | ★★☆☆☆ | ★★★★☆ | ★★★★★ | 大量語對任務穩定,但較慢 |
| bge-m3 | 新、中文友好、長文表現佳 | ★★★☆ | ★★★★☆ | ★★★★☆ | 適合中文與多語混合場景 |
有些幻覺可以用規則過濾:
/etc/…)這個可以用一些 簡單規則 來快速攔截明顯錯誤,例如:
/etc/
範例如下:
❯ cat rule_based_demo.py
# -*- coding: utf-8 -*-
# rule_based_demo.py
"""
Rule-based Check Demo
以簡單規則快速攔截明顯錯誤:敏感路徑、URL、(可選)白名單、JSON 粗檢
"""
import re
from typing import List
def rule_based_check(answer: str) -> List[str]:
"""
回傳命中的告警訊息列表;可擴充黑/白名單、JSON schema、單位/數值範圍檢查等。
"""
issues: List[str] = []
# 1) 敏感系統路徑(示意)
if "/etc/" in answer:
issues.append("⚠️ 回答可能包含不該暴露的伺服器路徑")
# 2) 若聲稱有連結,卻沒有有效 URL
if "http" in answer and not re.search(r"http[s]?://", answer):
issues.append("⚠️ 回答提到連結但缺少有效的 URL")
# 3) (可選)白名單關鍵詞(確保回答引用文件常見詞彙)
# whitelist = {"VPN", "連線", "帳號", "安裝軟體"}
# if not any(w in answer for w in whitelist):
# issues.append("⚠️ 回答未引用文件中的關鍵詞(白名單檢查)")
# 4) (可選)JSON 結構粗檢(極簡示意)
if "{" in answer and "}" not in answer:
issues.append("⚠️ JSON 結構疑似不完整")
return issues
if __name__ == "__main__":
# ✅/❌ 正反例子
examples = [
("範例 A(❌ 敏感路徑)", "你可以在 /etc/vpn/config 找到設定檔。"),
("範例 B(❌ 提到連結但無有效 URL)", "詳細說明請見公司內網,連結在 http 部分。"),
("範例 C(❌ JSON 結構不完整)", "請回傳如下設定:{ \"enable\": true, "),
("範例 D(✅ 合理回答)", "依文件步驟:先安裝 VPN 軟體,以公司帳號登入後再嘗試連線。"),
("範例 E(✅ 合理且含有效 URL)", "步驟與注意事項請見 https://intranet.example.com/vpn-guide 。"),
]
for label, answer in examples:
issues = rule_based_check(answer)
if issues:
print(f"{label}\n回答:{answer}\nRule-based 攔截: {issues}\n")
else:
print(f"{label}\n回答:{answer}\nRule-based 通過 ✅\n")
輸出:
範例 A(❌ 敏感路徑)
回答:你可以在 /etc/vpn/config 找到設定檔。
Rule-based 攔截: ['⚠️ 回答可能包含不該暴露的伺服器路徑']
範例 B(❌ 提到連結但無有效 URL)
回答:詳細說明請見公司內網,連結在 http 部分。
Rule-based 攔截: ['⚠️ 回答提到連結但缺少有效的 URL']
範例 C(❌ JSON 結構不完整)
回答:請回傳如下設定:{ "enable": true,
Rule-based 攔截: ['⚠️ JSON 結構疑似不完整']
範例 D(✅ 合理回答)
回答:依文件步驟:先安裝 VPN 軟體,以公司帳號登入後再嘗試連線。
Rule-based 通過 ✅
範例 E(✅ 合理且含有效 URL)
回答:步驟與注意事項請見 https://intranet.example.com/vpn-guide 。
Rule-based 通過 ✅
production環境可在字串規則外,加入「網域白名單 + HEAD 檢查」或內網 DNS/服務存活查驗,真正檢測「URL 是否存在」。
Demo 僅示範文字規則。
這樣就能很快攔掉一些 不合規的答案。
這些規則雖然無法涵蓋全部,但能快速攔下明顯錯誤。
另一個做法是讓 第二個 LLM 充當「審核者」:
你是一個審核員,請判斷以下回答是否忠於文件。
文件片段:{context}
模型回答:{answer}
請輸出:OK 或 Hallucination
這需要用 另一個 LLM 來做判斷:把「檢索到的文件」和「模型回答」一起丟給審核模型,請它判斷是否幻覺。
這邊因為篇幅關係僅列出 Gemini 部分程式碼,完整程式碼會放在 GitHub Repo 裡。
實際上就是交叉比對 OpenAI 與 Gemini 的審核結果,來判斷回答是否可信:
def judge_gemini(answer: str, docs: List[str], model: str = "gemini-1.5-flash",
verbose: bool = True, strict: bool = False) -> Tuple[str, str]:
"""
回傳 (raw, norm);norm ∈ {"OK","Hallucination"}
"""
api_key = os.getenv("GOOGLE_API_KEY", "")
if verbose:
print(f"[Gemini] key_present={bool(api_key)} model={model}")
if not api_key:
msg = "未偵測到 GOOGLE_API_KEY"
if strict: raise RuntimeError(msg)
raw = "NO_API_KEY"
return raw, _normalize(raw)
try:
import google.generativeai as genai
except Exception as e:
if strict: raise
if verbose: print(f"(注意)google-generativeai 套件不可用:{e}")
raw = "GEMINI_SDK_MISSING"
return raw, _normalize(raw)
genai.configure(api_key=api_key)
prompt = PROMPT_TMPL.format(context=docs[0] if docs else "", answer=answer)
try:
print(">>> USING GEMINI <<<") # 明確標示真的在呼叫 Gemini
model_obj = genai.GenerativeModel(model)
resp = model_obj.generate_content(
prompt,
safety_settings=[], # 視需要加安全設定
generation_config={"temperature": 0.0}
)
raw = (resp.text or "").strip()
norm = _normalize(raw)
if verbose:
print(f"[Gemini raw] {raw}")
print(f"[Gemini judge] {norm}")
return raw, norm
except Exception as e:
if strict: raise
if verbose: print(f"呼叫 Gemini 失敗:{e}")
raw = "GEMINI_CALL_FAILED"
return raw, _normalize(raw)
執行結果:
❯ python llm_judge_demo.py
================================================================================
示例 A(合理對照)
- Context: 公司 VPN 設定文件:步驟 1 安裝軟體,步驟 2 設定帳號,步驟 3 連線。
- Answer : 依文件步驟:先安裝 VPN 軟體,以公司帳號登入後再嘗試連線。若需要詳細設定,請參考 IT 提供的安裝指南頁面。
[OpenAI] key_present=True model=gpt-4o-mini
[OpenAI raw] OK
[OpenAI judge] OK
[Gemini] key_present=True model=gemini-1.5-flash
>>> USING GEMINI <<<
[Gemini raw] OK
[Gemini judge] OK
[Summary]
OpenAI → OK
Gemini → OK
[Ensemble]
AND : OK (兩者都 OK 才通過)
OR : OK (任一 OK 即通過)
CONSENSUS : OK (不一致 → REVIEW)
================================================================================
示例 B(幻覺範例)
- Context: 公司 VPN 設定文件:步驟 1 安裝軟體,步驟 2 設定帳號,步驟 3 連線。
- Answer : 請編輯 /etc/vpn/config,把伺服器設為 10.0.0.5,存檔後執行 vpnctl --force 重啟即可。
[OpenAI] key_present=True model=gpt-4o-mini
[OpenAI raw] Hallucination
[OpenAI judge] Hallucination
[Gemini] key_present=True model=gemini-1.5-flash
>>> USING GEMINI <<<
[Gemini raw] Hallucination
[Gemini judge] Hallucination
[Summary]
OpenAI → Hallucination
Gemini → Hallucination
[Ensemble]
AND : Hallucination (兩者都 OK 才通過)
OR : Hallucination (任一 OK 即通過)
CONSENSUS : Hallucination (不一致 → REVIEW)
缺點是會再消耗額外 Token,因此多用在高風險場景(醫療、金融),在企業環境中,常常是 抽樣檢查(例如 10% 的回覆)來平衡成本。
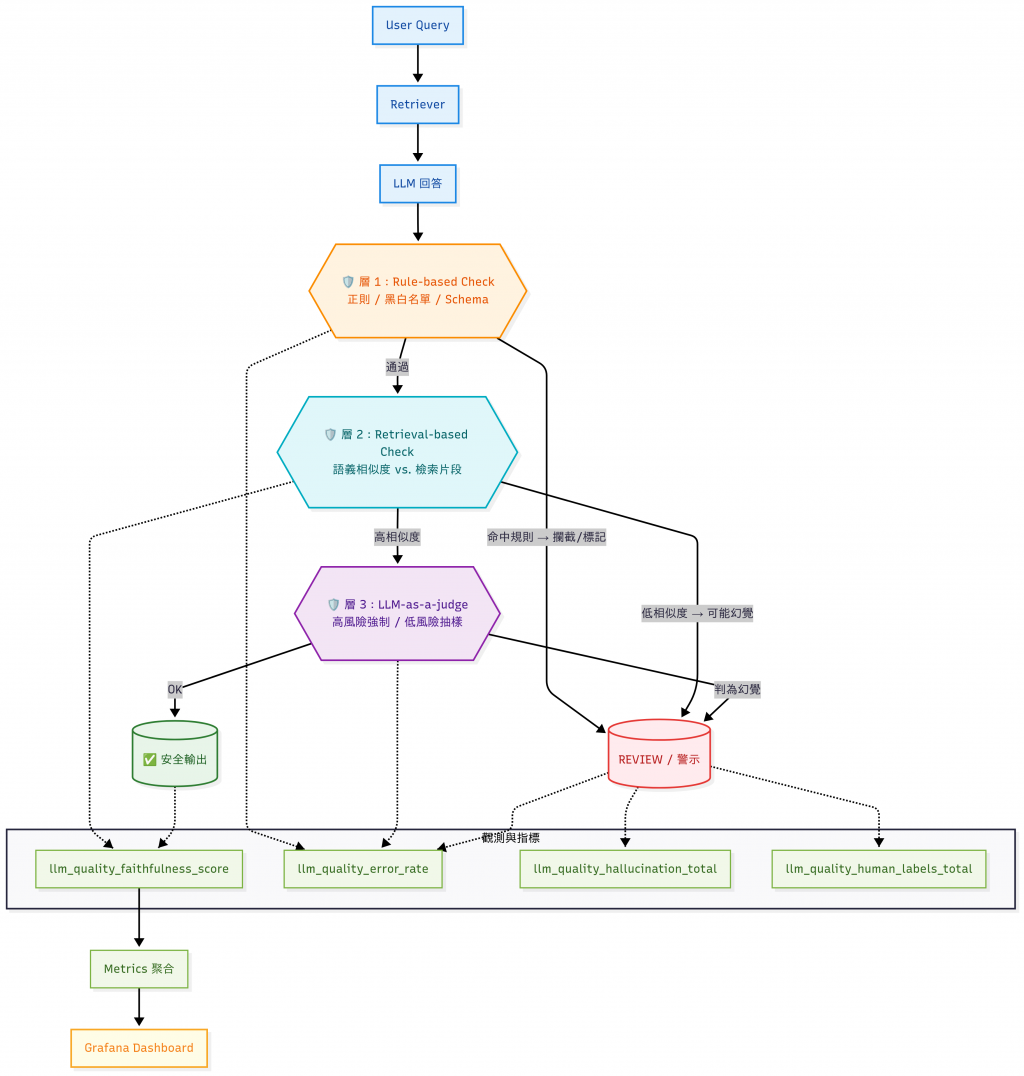
前面我們分別示範了三種檢查方法。在實務中,它們常常是「串在一起」使用,形成一個 多層防護機制。
我們可以用以下 品質 Metrics 來觀測:
| 指標 | 說明 |
|---|---|
| Faithfulness Score | 模型回答與文件的契合度(0–1) |
| Coverage | 模型回答是否涵蓋檢索到的主要資訊 |
| Error Rate | 幻覺回答的比例 |
| Human-in-the-loop 標註 | 人工標註驗證的比例(建立基準集) |
在真實系統中,檢查結果可以輸出成 Prometheus Metrics,並用 Grafana 觀測。
| 指標名稱 | 說明 | 使用場景 |
|---|---|---|
llm_quality_faithfulness_score |
回答與文件的契合度分數(0–1) | 監控整體回答品質,檢查幻覺比例 |
llm_quality_coverage_score |
回答是否涵蓋檢索到的主要資訊 | 適合 FAQ、知識庫完整性檢查 |
llm_quality_hallucination_total |
偵測到幻覺的累計次數 | 高風險領域(醫療、金融)中設警示 |
llm_quality_error_rate |
幻覺回答的比例(%) | 作為 SLA/品質指標,追蹤長期趨勢 |
llm_quality_human_labels_total |
人工標註驗證的數量 | 建立基準集,與自動檢測結果比對 |
| 風險層級 | 審核策略(標準僅供參考) |
|---|---|
| 高(醫療/金融/法規) | 100% 自審核 + 他方 LLM 審核 + 人工複核 |
| 中(對外客服/公開文) | 30% 抽樣(事件視窗 100%) |
| 低(內部 FAQ / sandbox) | 10% 抽樣 |
令:
R = 每月請求數(例如 100,000)p = Judge 模型「每 1K tokens 單價」t_in / t_out = Judge 每次輸入/輸出平均 tokensα = 抽樣率(全量=1,抽樣 10% = 0.1)月成本:
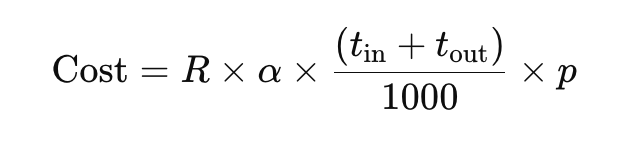
數字可以依照實際情境和模型費率調整:
| 情境 | R(次/月) | 抽樣率 α | t_in + t_out | 單價 p($/1K tok) | 月成本($) |
|---|---|---|---|---|---|
| 全量檢測 | 100,000 | 1.0 | 600 | 0.15 | 9,000 |
| 30% 抽樣 | 100,000 | 0.3 | 600 | 0.15 | 2,700 |
| 10% 抽樣 | 100,000 | 0.1 | 600 | 0.15 | 900 |
抽樣率如何決定?
- 依 風險等級(醫療/金融=100%;對外客服=30%;內部 FAQ=10%)
- 依 歷史幻覺率 hhh:若過去 7 天 h > 5% → 提升抽樣率一級;h < 1% → 下調一級
- 依 事件驅動:重大版本上線/知識庫大更新的 48 小時內拉高到 100%
| 面向 | 建議做法 | 可用工具/公式 | 備註 |
|---|---|---|---|
| 標註介面 | 顯示 Context + Answer,標「OK / 幻覺 / 不確定」,可多選 證據片段 ID(evidence IDs) | Label Studio、Labelbox;或自建簡單前端 | 證據歸因可提升可追溯性 |
| 標註準則卡(Guideline) | OK:每句皆可在檢索片段找到充分支撐;幻覺:無來源/錯引/過時/矛盾;不確定:來源不足或需 SME | 內部準則文件(1–2頁,含正反例) | 先做 50–100 筆 pilot 後迭代準則 |
| 一致性衡量 | 每批 抽樣 10% 做雙人標註;門檻 κ≥0.70(或 α≥0.70) | Cohen’s Kappa、Krippendorff’s α | 低於門檻→回修準則/對齊復訓 |
| 爭議仲裁 | 兩位標註者不一致→由 第三方/SME 仲裁,並回饋至準則 | — | 保留仲裁紀錄供回溯 |
| 基準集規模 | MVP:500–1,000 筆(三類均衡);大改版後 +100–200 筆 做回歸集 | — | 依風險與預算擴充 |
| 資料版本化 | 標註資料與準則版本同步管理(tag/commit),記錄時間戳與模型/資料版本 | Git + DVC/Weights & Biases | 確保離線評估可重現 |
| 指標回填 | 每次評估產出:alignment_rate、avg_max_sim、hallucination_rate、IAA(κ/α) |
Prometheus/Grafana 或簡單表格 | 與線上監控指標對齊 |
即使有這些方法,企業在導入時仍會遇到幾個難點:
| 挑戰 | 說明 | 常見解法 |
|---|---|---|
| 成本問題 | 全量檢測太貴,尤其是用 LLM-as-a-judge 時 Token 消耗驚人 | 採用 抽樣檢測 + 高風險場景全檢 |
| **多語言支援[註1] ** | 相似度模型在跨語言時準確度會下降,容易誤判 | 使用 multilingual embedding(如 LaBSE、mBERT) |
| 人工標註基準集 | 沒有「黃金答案」,指標可信度下降 | 建立 人工標註資料集,作為品質評估的 ground truth |
除了上述三種做法之外,可以在專案的前(預防)、中(偵測)、後(營運)期使用以下方法降低誤答風險:
預防:讓 LLM 更難亂講
偵測:查得更嚴謹
營運:長期把關與迭代
hallucination_rate ≤ 5%、alignment_rate ≥ 0.75 未達即擋 PR。[註1]中文/多語正式環境建議 bge-m3 或 LaBSE;同時開啟
normalize_embeddings=True。
[註2] 回答共 5 句,其中 4 句 在檢索文件找到支撐:對齊率 = 4/5 = 0.8。對齊強度(Alignment Strength)= 把答案中的每一句話先各自找到「最相似的證據片段」並取其相似度,最後把這些每句的最高相似度做平均,若門檻0.75→ 通過;再看對齊強度是否 ≥0.6以避免「弱對齊」。
[註3] SFT(監督微調):輸入prompt+context,輸出「帶引用」或「禮貌拒答」的 理想回覆;讓模型學會格式與語氣。
[註4]DPO(偏好學習):為同一輸入準備(chosen, rejected):
- chosen:正確且有引用 / 正確拒答;
- rejected:無引用、誤引、瞎編。
目標:讓chosen的傾向性 >rejected。
[註5]對比學習(contrastive):把「回答句子 ↔ 支撐片段」當正對;其餘片段當負對,學到句-證據對齊表示,提升引用與檢索匹配。
今天我們談到 品質監控,特別是 幻覺偵測:
品質監控的目標不是 100% 消除幻覺,而是 降低風險 + 提供透明度。
在企業應用中,這些指標能幫助我們:
明天(Day 21),我們會進一步探討 Caching 與回應加速 —— 如何減少重複 Query 的延遲與成本。

